Was ist Step 3.5 Flash?
Ehrlich gesagt war ich ziemlich skeptisch, als ich zum ersten Mal von Step 3.5 Flash hörte. Das Ganze dreht sich darum, dass es sich um ein Open-Source-Sprachmodell (LLM) handelt, das auf Geschwindigkeit, logische Schlussfolgerungen und den Einsatz auf handelsüblicher Hardware ausgelegt ist. Natürlich fragte ich mich: Kann ein KI-Modell wirklich die Art von Leistung liefern, die normalerweise nur von großen Cloud-Servern bereitgestellt wird? Oder ist das nur eine weitere schicke Demo, die sich in der Praxis schwer tut?
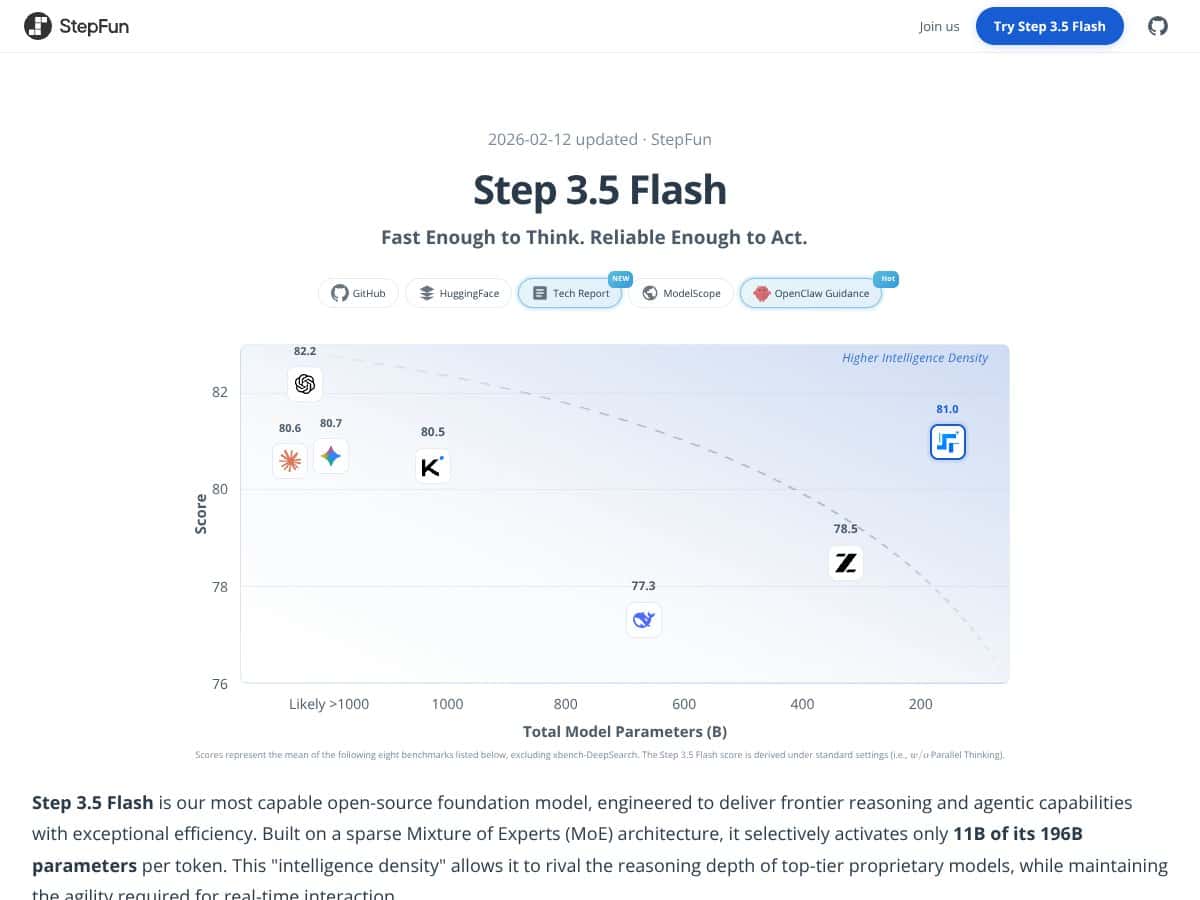
Auf gut Deutsch gesagt behauptet Step 3.5 Flash, ein sehr leistungsfähiges KI-Modell zu sein, das komplexe Texte verstehen und generieren, logische Schlussfolgerungen ziehen und sogar lokal auf leistungsstarker Verbraucherhardware laufen kann. Es basiert auf einer spärlich besetzten Mixture of Experts (MoE)-Architektur, was bedeutet, dass es eine enorme Anzahl von Parametern besitzt (insgesamt 196 Milliarden), aber nur einen Bruchteil davon zu jedem Zeitpunkt aktiviert wird, was es angeblich schneller und effizienter macht. Man kann es sich vorstellen wie ein sehr großes Team, bei dem nur wenige Experten für jede Aufgabe hinzugezogen werden, statt dass alle dauerhaft mitwirken.
Das Hauptproblem, das es zu lösen versucht: Wie erhält man leistungsstarke KI-Schlussfolgerungs- und Codierungsfähigkeiten, ohne auf massiven, teuren Cloud-Infrastrukturen angewiesen zu sein? Wenn es so funktioniert wie beworben, könnte es fortgeschrittene KI für Einzelpersonen und kleine Teams zugänglich machen, ohne dass man Zugänge von großen Cloud-Anbietern mieten oder Datenschutzbedenken in Kauf nehmen muss.
Die Macher dahinter sind StepFun AI, ein Unternehmen, das Open-Source-Modelle mit Fokus auf Effizienz und lokale Bereitstellung vorantreibt. Ich konnte nicht viele detaillierte Informationen über das Team finden, aber die Entwicklung des Modells scheint auf aktueller Forschung zu basieren, insbesondere rund um spärlich besetzte MoE-Architekturen und die Verarbeitung langer Kontextinformationen.
Mein erster Eindruck? Mir fiel auf, dass das Modell tatsächlich so leistungsfähig zu sein scheint, wie der Hype in Benchmark-Ergebnissen suggeriert. Es ist auf logische Schlussfolgerungen, Codierung und agentische Aufgaben ausgelegt und scheint in diesen Bereichen zu überzeugen. Allerdings vorweg: Es ist kein Plug-and-Play-Produkt mit einer schickeren GUI oder einer einfachen API. Es ist eher ein forschungsorientiertes, technikaffines Werkzeug, das etwas Einrichtung und Verständnis von KI-Modellen erfordert. Erwarten Sie außerdem nicht, dass es bei mehrsprachigen Aufgaben oder bei alltäglichen, informellen Gesprächen perfekt funktioniert. Es ist eher für spezialisierte, leistungsstarke Aufgaben gedacht.
Ein weiterer Hinweis: Soweit ich es beurteilen konnte, ist es von Haus aus nicht für Gelegenheitsnutzer oder kleine Projekte gedacht. Es richtet sich an Entwickler, Forscher oder Hobbyisten, die sich mit der lokalen Bereitstellung von KI auskennen und sich mit Hardware- und Software-Integration auskennen. Wenn Sie einen fertigen Chatbot mit einer benutzerfreundlichen Oberfläche erwarten, ist das nichts für Sie.
Step 3.5 Flash Preisgestaltung: Lohnt es sich?
| Plan | Preis | Was Sie erhalten | Meine Einschätzung |
|---|---|---|---|
| Kostenlose Stufe | Unbekannt / Nicht öffentlich gelistet | Vermutlich eingeschränkter Zugriff, wahrscheinlich nur für lokale Bereitstellung | Hinweis: Die Details der kostenlosen Stufe sind nicht klar. Wenn Sie dieses Modell testen möchten, rechnen Sie mit Einschränkungen – vermutlich bei Nutzungsbeschränkungen oder beim Zugriff auf Funktionen. Seien Sie auf Beschränkungen vorbereitet, die eine vollständige Bewertung erschweren könnten. |
| API-Zugang über SiliconFlow | $0,10 pro 1.000 Eingabe-Tokens, $0,30 pro 1.000 Ausgabe-Tokens | Bezahlung nach Nutzung der API, skalierbar von kleinen bis zu großen Projekten, kein festes Abonnement | Dies scheint vernünftig bepreist für ein fortgeschrittenes Modell, insbesondere angesichts seiner Benchmark-Leistung. Bedenken Sie jedoch, dass die Kosten steigen können, wenn Sie große Datenmengen verarbeiten – planen Sie Ihre Nutzung entsprechend. |
| API-Zugang über OpenRouter | $0,10 pro 1.000 Eingabe-Tokens, $0,30 pro 1.000 Ausgabe-Tokens | Ähnlich wie SiliconFlow, geeignet für diejenigen, die das OpenRouter-Ökosystem bevorzugen | Gleiche Preisgestaltung wie SiliconFlow, daher keine großen Überraschungen. Allerdings könnten Nutzungsobergrenzen oder Funktionsbeschränkungen lauern – prüfen Sie vor intensiver Nutzung die Nutzungsbedingungen. |
| Lokale Bereitstellung | Kostenlos (Open-Source) | Läuft auf leistungsstarker Endverbraucher-Hardware wie dem Mac Studio M4 Max oder NVIDIA DGX Spark | Das ist ein großer Vorteil für datenschutzbewusste Nutzer oder solche, die Zugang zu leistungsstarker Hardware haben. Es fallen keine Lizenzgebühren an, aber die Hardware-Anforderungen sind nicht unerheblich. |
Was die Preisgestaltung betrifft: Sie ist ziemlich透明, wenn Sie eine API-Nutzung in Betracht ziehen, mit standardmäßigen Pay-as-you-go-Tarifen, die für Modelle dieser Klasse wettbewerbsfähig sind. Die eigentliche Frage ist, ob Ihr Nutzungsvolumen die Kosten rechtfertigt, insbesondere da hoher Durchsatz und die Verarbeitung vieler Tokens schnell teuer werden können. Eine faire Warnung: Falls Sie Hobbyist sind oder einfach nur experimentieren, könnten die API-Kosten im Vergleich zu Open-Source-Optionen etwas hoch sein. Für Unternehmen oder Heavy-Duty-Nutzer könnte der Wert in Geschwindigkeit und Effizienz die Kosten rechtfertigen.
Was auf der Verkaufsseite nicht gesagt wird, ist, ob versteckte Kosten anfallen – wie Wartung, Infrastruktur oder mögliche Überziehungsgebühren. Da die Details zur kostenlosen Stufe fehlen, nimm nicht an, dass sie großzügig ist; es könnte eher eine Test- oder eingeschränkte Demo-Umgebung sein. Klären Sie diese Punkte unbedingt, bevor Sie sich verpflichten.
Welcher Plan macht Sinn? Wenn Sie als Solo-Entwickler oder Forscher gelegentlich testen, könnten die kostenlosen oder kostengünstigen API-Optionen ausreichen. Aber wenn Sie es in großem Maßstab einsetzen—zum Beispiel in ein Produkt oder eine Dienstleistung integrieren—werden Sie die API-Pläne benötigen, und Sie sollten Ihre Token-Nutzung genau überwachen, um Überraschungen zu vermeiden.
Vorteile und Nachteile
Was mir gefallen hat
- Inferenz mit Hochgeschwindigkeit: Die Erzielung von 100–300 Tokens pro Sekunde bei komplexen Schlussfolgerungen ist beeindruckend, insbesondere für ein Modell, das lokal läuft. Das ist ein echter Wendepunkt für Echtzeit-Anwendungen.
- Effiziente Verarbeitung langer Kontextgrößen: Die Unterstützung von bis zu 262K Tokens mit einem hybriden Aufmerksamkeitsmechanismus bedeutet, dass Sie riesige Datensätze oder lange Codebasen ohne Probleme verarbeiten können. Das ist selten und außerordentlich wertvoll für bestimmte Arbeitsabläufe.
- Open-Source & Lokale Bereitstellung: Keine Cloud-Abhängigkeit bedeutet besseren Datenschutz und mehr Kontrolle. Der Betrieb auf Verbraucherhardware wie dem Mac Studio M4 Max macht es auch für ernsthafte Hobbyisten und kleine Teams zugänglich.
- Fortgeschrittene Benchmark-Ergebnisse: Benchmarks wie SWE-bench und IMO-AnswerBench zeigen, dass dieses Modell nicht nur schnell ist—es ist auch klug, besonders beim Programmieren, beim Schlussfolgern und bei agentenbasierten Aufgaben.
- Skalierbare Selbstverbesserung: Die Einbindung von RL-Frameworks deutet auf laufende Verbesserungen und Anpassungsfähigkeit hin, was vielversprechend für die zukünftige Leistung ist.
Was könnte besser sein
- Hardware-Anforderungen: Um das volle Potenzial von Step 3.5 Flash auszuschöpfen, benötigen Sie High-End-Hardware – wie Mac Studio M4 Max oder NVIDIA DGX Spark –, was nicht für jeden realistisch ist. Dies könnte für Anwender mit kleinem Budget oder Low-End-Systemen ein Ausschlusskriterium darstellen.
- Eingeschränktes Ökosystem und Tools: Als ein relativ neues Modell ist das Ökosystem rund um Step 3.5 Flash noch unausgereift. Es sind keine Plugins, Integrationen oder benutzerfreundlichen Schnittstellen erwähnt, was die Einführung verlangsamen oder die Bereitstellung erschweren könnte.
- Benchmark-Bias: Die meisten Benchmarks sind in Englisch und technischen Domänen; Leistungen in anderen Sprachen oder weniger strukturierten Aufgaben bleiben unbestätigt. Wenn Ihre Arbeit mehrsprachig oder kreativ ist, seien Sie vorsichtig.
- Undurchsichtige Preisgestaltung & Nutzungsgrenzen: Das Fehlen detaillierter Informationen zu kostenlosen Tarifen, Quoten oder Funktionsbeschränkungen macht eine langfristige Planung schwierig. Wenn Sie auf Limits stoßen, müssen Sie möglicherweise unerwartet auf kostenpflichtige Pläne wechseln.
- Neuheit und Weiterentwicklung: Da es sich um eine neu erschienene Version handelt, besteht das Risiko von Fehlern, unvollständiger Dokumentation oder fehlenden Funktionen, die bei Modellen in der frühen Phase auftreten. Seien Sie auf eine Lernkurve und mögliche Startschwierigkeiten vorbereitet.
Für wen ist Step 3.5 Flash tatsächlich geeignet?
Wenn Sie ein Entwickler, Forscher oder KI-Hobbyist mit Zugang zu High-End-Hardware und dem Bedarf an ultra-schnellem Denken über lange Kontextfenster sind, könnte dieses Modell eine perfekte Lösung sein. Es ist besonders geeignet für Aufgaben wie komplexe Codierung, langwieriges Schlussfolgern oder den Aufbau agentischer Systeme, bei denen Privatsphäre und Geschwindigkeit an erster Stelle stehen.
Wenn Sie beispielsweise an einem KI-Assistenten arbeiten, der große Codebasen oder lange Dokumente auf Ihrem lokalen Rechner verarbeitet, bietet Step 3.5 Flash die Leistung und Flexibilität, dies ohne Cloud-Abhängigkeiten zu ermöglichen. Es ist außerdem ideal für diejenigen, die in einer praktischen Umgebung modernste KI-Architekturen wie Sparse MoE testen möchten.
Wenn Ihr Arbeitsablauf jedoch kein massiver Kontext oder Echtzeit-agentische Begründung erfordert — und insbesondere, wenn Sie ein knappes Budget oder Hardware der unteren Preisklasse verwenden, könnte dies überdimensioniert sein. Es ist nicht für Gelegenheitsnutzer oder kleine Projekte gedacht, die die Hardware-Investitionen nicht rechtfertigen können oder nicht bereit sind, die Komplexität zu bewältigen.
Für wen es sinnvoll ist, woanders nach Alternativen zu schauen
Wenn Ihr primärer Bedarf ein allgemeines Sprachmodell für einfache Aufgaben ist oder wenn Sie keinen Zugang zu Hochleistungs-Hardware haben, ist dies nicht die richtige Wahl. Modelle wie Llama 3.1 oder kleinere Open-Source-Alternativen könnten Ihnen besser dienen—insbesondere, da sie auf bescheidener Hardware laufen und eine breitere Community-Unterstützung haben.
Genauso, wenn Sie eine Plug-and-Play-Lösung mit minimalem Setup benötigen oder wenn Sie ein ausgereiftes Ökosystem mit dedizierten Plugins und Integrationen bevorzugen, warten Sie, bis dieses Modell reift, oder ziehen Sie etablierte Optionen in Betracht. Proprietäre Modelle mit API-Zugriff von OpenAI, Anthropic oder Google könnten auch besser geeignet sein, wenn Sie Benutzerfreundlichkeit gegenüber roher Leistung priorisieren.
Schließlich, wenn mehrsprachige Unterstützung oder vielfältigere Benchmarks für Ihre Arbeit entscheidend sind, beachten Sie, dass Step 3.5 Flashs Leistung in diesen Bereichen nicht verifiziert ist. Sie könnten enttäuscht werden, wenn Ihre Erwartungen außerhalb seiner aktuellen Stärken liegen.
Wie Step 3.5 Flash im Vergleich zu Alternativen abschneidet
Mixtral 8x22B (Mistral AI)
- Was es anders macht: Mixtral 8x22B basiert auf einer hocheffizienten Mixture-of-Experts-Architektur, ähnlich wie Step 3.5 Flash, jedoch mit einer leicht geringeren Parameteranzahl (etwa 22B). Es legt Wert auf Open-Source-Gewichte und optimierte Inferenz für eine schnelle Bereitstellung, hauptsächlich ausgerichtet auf mehrsprachige Aufgaben und breitere Domänen.
- Kostenvergleich: Open-Source, läuft also lokal kostenlos; Cloud-API-Kosten sind vergleichbar und liegen bei etwa 0,10–0,30 USD pro Million Tokens.
- Wählen Sie dies, wenn... Sie ein flexibles, mehrsprachiges Modell mit guter Effizienz und offenen Gewichten benötigen, insbesondere wenn Sie mit unterschiedlichen Architekturen experimentieren möchten, ohne Hardwareeinschränkungen.
- Bleiben Sie bei Step 3.5 Flash, wenn... Ihr primäres Ziel fortschrittliche Begründungsfähigkeiten, leistungsstarke Codierung und agentische Fähigkeiten sind, insbesondere auf hochwertiger lokaler Hardware.
DeepSeek-V3
- Was es anders macht: DeepSeek-V3 ist ebenfalls ein Open-Source-MoE-Modell, das für Programmierung und Mathematik optimiert ist und über ein großes Kontextfenster verfügt. Es legt großen Wert auf starke Benchmarks in technischen Bereichen, die Step 3.5 Flash ähneln.
- Preisvergleich: Kostenlos für die lokale Bereitstellung; Cloud-API liegt grob bei $0,10–$0,30 pro Token, ähnlich wie die API-Optionen von Step 3.5 Flash.
- Wählen Sie dies aus, wenn... Sie Wert legen auf technische Genauigkeit und die Verarbeitung langer Kontextfenster, ohne unbedingt die neuesten agentischen Funktionen zu benötigen.
- Bleiben Sie bei Step 3.5 Flash, wenn... Sie eine bessere Mehrfachaufgaben-Reasoning, höhere Geschwindigkeit und eine flexible Architektur für agentische Arbeitsabläufe benötigen.
Qwen2.5-Coder (Alibaba)
- Was es anders macht: Qwen2.5-Coder ist auf Codierungsaufgaben zugeschnitten, weist hohe SWE-Bench-Werte und robuste Codierungsfähigkeiten auf. Es ist speziell für entwicklerfokussierte Anwendungen konzipiert.
- Preisvergleich: Open-Source, also lokal kostenlos; API-Kosten liegen ähnlich, ca. $0,10-$0,30 pro Token.
- Wählen Sie dies aus, wenn... Ihr Hauptfokus auf Coding und Entwicklerwerkzeugen liegt, und weniger auf allgemeiner Argumentation oder Aufgaben mit langem Kontext.
- Bleiben Sie bei Step 3.5 Flash, wenn... Sie eine ausgewogenere Modellstimme möchten mit Begründungsfähigkeiten, Agentik und Multi-Task-Fähigkeiten jenseits des reinen Codings.
Llama 3.1 405B (Meta)
- Was es anders macht: Llama 3.1 ist ein dichter, groß angelegtes Modell mit starken Schlussfolgerungsfähigkeiten und Mehrsprachigkeit, erfordert jedoch deutlich mehr Rechenleistung und ist nicht für Echtzeit-Agentikaufgaben optimiert.
- Preisvergleich: In der Regel über Cloud-API zugänglich mit höheren Kosten; lokale Bereitstellung ist anspruchsvoll und erfordert leistungsstarke GPUs oder Cluster.
- Wählen Sie dies aus, wenn... Sie ein Modell mit nachweislicher Schlussfolgerungsfähigkeit und Mehrsprachigkeit benötigen und die notwendige Hardware sowie Budget haben, um es zu unterstützen.
- Bleiben Sie bei Step 3.5 Flash, wenn... Sie Effizienz und lokale Bereitstellung auf Heimanwender-Hardware wünschen, die Llama 3.1 nicht gut unterstützt.
Fazit: Sollten Sie Step 3.5 Flash ausprobieren?
Insgesamt würde ich Step 3.5 Flash eine solide 7,5 von 10 geben. Es ist in seiner Größe ein Kraftpaket – es bietet beeindruckende Geschwindigkeit, Effizienz und Begründungsfähigkeiten – insbesondere, wenn Sie hochwertige Hardware verwenden. Es ist nicht perfekt; Sie benötigen ordentliche Hardware, um sein Potenzial wirklich auszuschöpfen, und es ist im Ökosystem noch ziemlich neu, sodass einige Tools und Integrationen möglicherweise unausgereift wirken könnten.
Wenn Sie ein flexibles Open-Source-Modell suchen, das lokal Codierung, Mathematik und Aufgaben mit langem Kontext bewältigen kann, ist dies definitiv einen Versuch wert. Die Open-Source-Natur bedeutet, dass keine Cloud-Kosten im Voraus anfallen, und es ist eine gute Möglichkeit, sich mit modernen Sparse-MoE-Architekturen vertraut zu machen.
Allerdings, wenn Sie ein knappes Budget haben, Hardware der unteren Klasse nutzen oder hauptsächlich ein Modell für mehrsprachige oder allgemeine Schlussfolgerungsaufgaben benötigen, sollten Sie sich möglicherweise anderswo umsehen — zum Beispiel Llama 3.1, wenn Sie kompakte Modelle bevorzugen, oder Mixtral, wenn Sie mehrsprachige Unterstützung mit offenen Gewichten wünschen.
Persönlich würde ich es empfehlen, wenn Sie technikaffin sind und eine leistungsstarke, lokale Lösung wünschen, die mit Ihren Bedürfnissen wachsen kann. Wenn Sie nur gelegentlich experimentieren, könnte es übertrieben sein, und einfachere Modelle könnten den Job erledigen, ohne den Hardware-Aufwand zu verursachen.
Kurz gesagt: Probieren Sie es aus, wenn Sie bereit sind, in hochwertige Hardware zu investieren und zukunftsweisende Technologien zu erforschen. Wenn nicht, könnte es besser sein, Ihr Geld und Ihre Zeit in etabliertere oder weniger anspruchsvolle Optionen zu investieren.
Häufig gestellte Fragen zu Step 3.5 Flash
- Ist Step 3.5 Flash sein Geld wert? Es ist kostenlos, wenn Sie es selbst hosten, aber die Hardwarekosten können hoch sein. Die Leistungsverbesserungen machen es lohnenswert, wenn Sie Echtzeit-Schlussfolgerungen benötigen und eine lokale Bereitstellung wünschen.
- Gibt es eine kostenlose Version? Ja, Sie können es lokal kostenlos ausführen, aber für optimale Leistung benötigen Sie Hochleistungs-Hardware wie Mac Studio M4 Max oder NVIDIA DGX.
- Wie schneidet es im Vergleich zu Mixtral 8x22B ab? Beide sind effiziente MoE-Modelle, aber Step 3.5 Flash bietet bessere Schlussfolgerungen und agentische Fähigkeiten, während Mixtral mehrsprachiger und flexibler für den allgemeinen Gebrauch ist.
- Kann es mehrsprachige Aufgaben bewältigen? Derzeit konzentrieren sich die meisten Benchmarks auf Englisch; die mehrsprachige Leistung ist weniger dokumentiert, daher ist es hauptsächlich für englisch-zentrierte Aufgaben optimiert.
- Was ist mit langen Kontexten? Es unterstützt sehr lange Kontexte bis zu 262.000 Token, was es hervorragend für komplexe Schlussfolgerungen über große Dokumente macht.
- Wie schwierig ist die Einrichtung? Sie benötigen einige technische Kenntnisse, um es auf Hochleistungs-Hardware bereitzustellen und zu optimieren, aber gute Dokumentation verbessert sich.
- Gibt es Support oder Rückerstattungen? Da es Open-Source ist, sind Rückerstattungen nicht möglich. Support hängt von Community-Foren und Dokumentationen ab.