¿Qué es Forge Agent?
Sinceramente, cuando escuché por primera vez hablar de Forge Agent, estaba bastante escéptico. El marketing habla mucho de acelerar las velocidades de inferencia de GPU sin tocar ni una sola línea de código—suena genial, pero ya he visto proyectos prometer más de lo que cumplen. Así que decidí investigar por mí mismo, curioso por saber si es solo otro truco de optimización de IA o algo realmente útil.
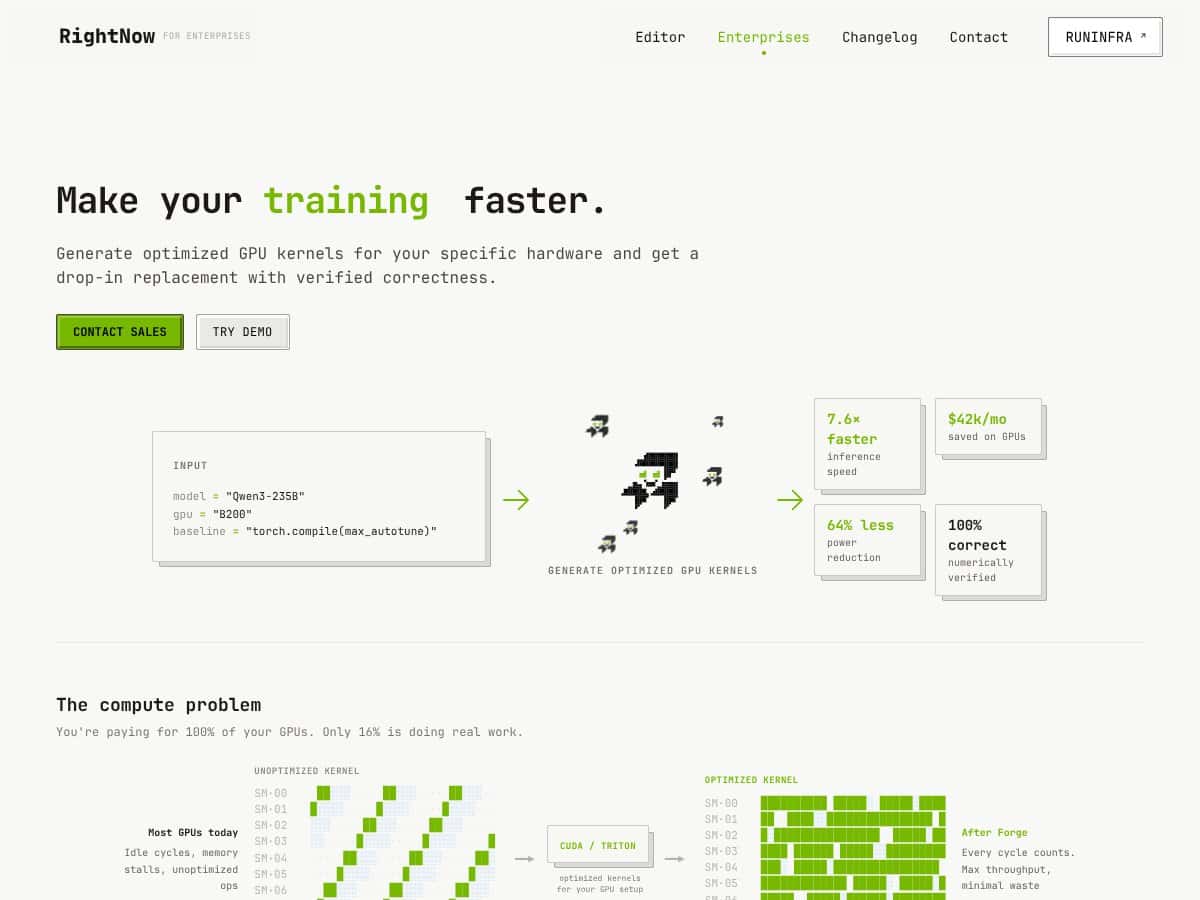
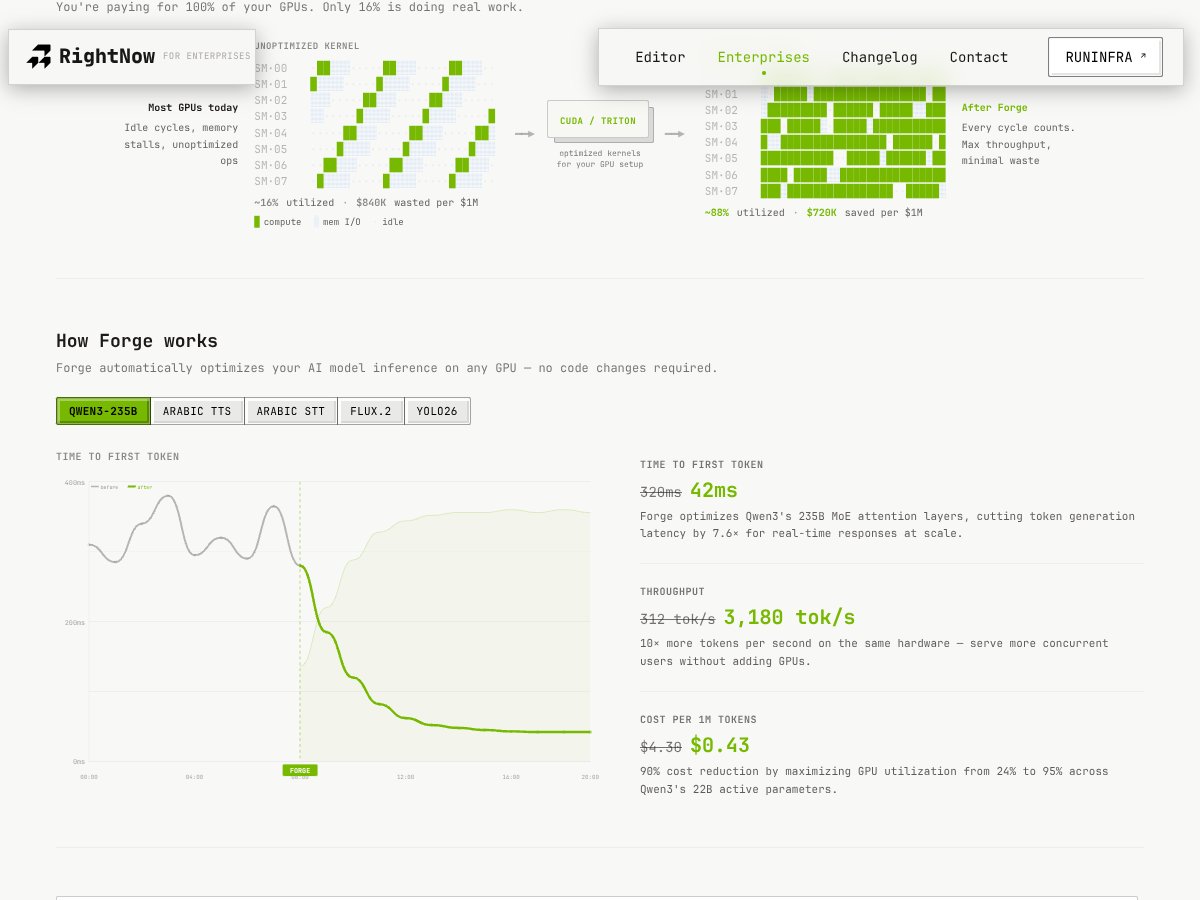
En lenguaje llano, Forge Agent es una herramienta que automáticamente intenta hacer que tus modelos de IA se ejecuten más rápido en GPUs generando código de kernel personalizado y optimizado—piensa en ello como un generador de código CUDA o Triton muy inteligente y automatizado. La idea es que tus modelos se ejecuten hasta 14 veces más rápido, con exactitud perfecta, y no tengas que ajustar o afinar nada manualmente. En cambio, afirma hacer todo el trabajo duro de bajo nivel por ti.
El problema que está abordando es bastante claro: la mayoría de la inferencia de IA se ve obstaculizada por código no optimizado que deja muchos ciclos de GPU inactivos. Estás pagando por hardware costoso, pero una gran parte de tus recursos de GPU no están haciendo mucho. Eso resulta en dinero perdido, mayor consumo de energía y tiempos de respuesta más lentos—especialmente frustrante cuando intentas servir aplicaciones en tiempo real o ampliar la capacidad de inferencia.
RightNow AI, la empresa detrás de Forge Agent, no es un nombre muy conocido, pero parece centrarse en la optimización a nivel de GPU para cargas de IA. Según lo que he recopilado, están dirigiéndose a equipos de ML e ingenieros de infraestructura que quieren exprimir cada onza de rendimiento de su hardware sin sumergirse en la programación CUDA por sí mismos.
Mi impresión inicial fue que está tal como se anuncia: si confías en sus afirmaciones. El proceso se supone que es directo: sube tu modelo, especifica tu GPU y deja que Forge genere kernels optimizados en menos de una hora. Me sorprendió descubrir que parece generar código que, al menos en teoría, puede acelerar masivamente las cosas sin que tengas que cambiar tu base de código. Sin embargo, también noté que la documentación y la incorporación son bastante mínimas, por lo que te quedas tratando de resolver algunas cosas por tu cuenta.
Lo que quiero dejar claro de antemano es qué Forge no es. No es una plataforma de IA de uso general ni una herramienta completa de automatización de pipelines. Es específicamente sobre la optimización a bajo nivel de kernels para inferencia. Si buscas una forma de construir o entrenar modelos, esto no es. Y por lo que puedo decir, está orientado a equipos técnicos cómodos con interfaces de línea de comandos y perfilado de GPU—probablemente no sea una solución lista para usar para usuarios no técnicos.
Precios de Forge Agent: ¿Vale la pena?
| Plan | Precio | Qué obtienes | Mi opinión |
|---|---|---|---|
| Plan gratuito | Desconocido / No publicado públicamente | Acceso limitado o de demostración a las funciones de Forge CLI; los detalles no están claros | Advertencia: como los detalles del nivel gratuito no están publicados públicamente, es difícil evaluar cuán útil es o qué limitaciones podrían existir. Probablemente apto para pruebas iniciales, pero quizá no para cargas de trabajo a gran escala en producción. |
| Empresarial / a medida | No divulgado | Soluciones a medida que incluyen infraestructura dedicada, soporte y Acuerdos de Nivel de Servicio (SLA) | Aquí está lo esencial sobre los precios... probablemente sea una cotización personalizada, lo que tiene sentido para equipos grandes o empresas con necesidades específicas. Pero para empresas más pequeñas o desarrolladores individuales, podría ser un obstáculo importante si los costos son altos u opacos. |
Mi opinión honesta
Honestamente, sin detalles de precios claros, es difícil determinar si Forge Agent ofrece una buena relación calidad-precio. En comparación con alternativas como NVIDIA TensorRT o opciones de código abierto como TVM u ONNX Runtime, que son gratuitas o tienen precios transparentes, el valor de Forge depende de las mejoras de rendimiento que afirma y de cuánto estés dispuesto a pagar por comodidad y automatización.
Lo que no te dicen en la página de ventas es si esas mejoras de rendimiento conllevan un costo adicional o si forman parte de un paquete empresarial más amplio. Si eres un equipo pequeño o un desarrollador individual, la falta de precios visibles y la necesidad de cotizaciones potencialmente personalizadas podrían ser una barrera significativa. Sin embargo, si eres un equipo de ML en una gran organización que busca maximizar la utilización de la GPU con un mínimo ajuste manual, la inversión podría justificarse, siempre que el costo se alinee con tu presupuesto.
Aviso: siempre solicita una demostración o prueba antes de comprometerse, especialmente porque el retorno de la inversión (ROI) depende en gran medida de tus modelos e infraestructura específicos.
Lo bueno y lo malo
Lo que me gustó
- Reclamaciones de rendimiento: Inferencia hasta 14x más rápida suena impresionante, especialmente si se mantiene en escenarios reales. La mención de una corrección del 100% verificada numéricamente es tranquilizadora.
- Flujo de trabajo sin cambios de código: para equipos que temen reescribir modelos o pipelines, esto puede ahorrar mucho tiempo y reducir el riesgo de implementación.
- Soporte para múltiples modelos: Ya sea que trabajes con modelos de lenguaje, generación de imágenes o reconocimiento de voz, Forge parece lo suficientemente versátil para manejar diversas cargas de trabajo.
- Automatización mediante agentes de IA en enjambre: Esto podría democratizar la optimización de GPU, haciéndola accesible incluso para quienes no cuentan con una profunda experiencia en CUDA o Triton.
- Integración con frameworks populares: El asistente interactivo para modelos de HuggingFace y archivos de PyTorch facilita una incorporación más fluida a esos ecosistemas.
Qué podría mejorar
- Falta de reseñas públicas o comentarios de la comunidad: Es difícil evaluar el rendimiento real o la fiabilidad sin validación independiente o testimonios de usuarios.
- Precios poco claros: La ausencia de planes transparentes complica la planificación presupuestaria, especialmente para equipos pequeños o startups.
- Documentación limitada sobre detalles del flujo de trabajo: No hay muchos detalles sobre cómo funciona el proceso de optimización bajo el capó, lo cual podría ser importante para depurar o generar confianza.
- Potencial bloqueo de proveedor: Dado que la herramienta depende en gran medida de la optimización propietaria, migrar podría ser costoso o complicado.
- Soporte y ecosistema: Al no mencionarse foros comunitarios ni documentación extensa, la incorporación podría resultar desafiante para usuarios con menos experiencia.
¿Para quién es realmente Forge Agent?
Si formas parte de un equipo de ingeniería de ML en una empresa de tamaño medio a grande, especialmente si gestionas cargas de inferencia a gran escala, Forge Agent podría marcar la diferencia. Es ideal si quieres maximizar el rendimiento de la GPU sin invertir mucho en ajuste manual de bajo nivel o experiencia en CUDA. Por ejemplo, si tu equipo ejecuta varios modelos de lenguaje o pipelines de generación de imágenes y necesitas una inferencia más rápida con precisión predecible, la automatización de Forge podría optimizar tus operaciones.
De igual modo, si gestionas la infraestructura y necesitas sacar el máximo rendimiento de los clústeres de GPU existentes—por ejemplo, para reducir costos operativos o aumentar la capacidad—, la promesa de alcanzar hasta 14 veces más velocidad y ahorros significativos en costos hace que valga la pena considerarla. El enfoque de implementación sin código es especialmente atractivo para equipos que prefieren evitar reescribir modelos o profundizar en kernels de CUDA.
Sin embargo, si eres un desarrollador individual, una pequeña startup o alguien que busca un SDK plug-and-play con precios transparentes, Forge podría resultar excesivo o difícil de justificar sin información clara de costos y beneficios.
Quién debería buscar en otro lugar
Si tu principal necesidad es un motor de inferencia flexible y de código abierto sin bloqueo de proveedor, alternativas como ONNX Runtime, TVM o incluso TensorRT (que es gratuito para el hardware de NVIDIA) podrían ser más adecuadas. Esas opciones ofrecen transparencia y soporte de la comunidad, que Forge actualmente no ofrece.
Además, si buscas una plataforma de IA de uso general o herramientas de entrenamiento de modelos en lugar de solo optimización de kernels de GPU, Forge no está diseñada para ello. Su foco está en el rendimiento de la inferencia, así que si tu carga de trabajo implica entrenamiento o desarrollo de modelos personalizados, busca en otro lugar.
Finalmente, si necesita reseñas detalladas de usuarios, validación comunitaria, o desea ver benchmarks independientes de rendimiento, tenga en cuenta que la reputación de Forge aún está en construcción—así que proceda con precaución hasta que pueda verificar sus afirmaciones en su entorno específico.
Cómo se compara Forge Agent con las alternativas
NVIDIA TensorRT
- Qué lo diferencia: TensorRT es el optimizador de inferencia dedicado de NVIDIA que aprovecha una integración profunda con CUDA y la aceleración por hardware. Está altamente afinado para GPUs NVIDIA y admite pipelines de despliegue centrados en entornos de producción.
- Comparación de precios: TensorRT es gratuito para usuarios de GPU NVIDIA, pero puede que necesite pagar por soporte empresarial o herramientas adicionales. El precio de Forge no es público, pero la naturaleza de código abierto de TensorRT lo hace más accesible si se siente cómodo con la configuración manual.
- Elija esto si... desea una integración estrecha con la GPU NVIDIA y tiene la experiencia técnica para optimizar modelos manualmente.
- Manténgase con Forge Agent si... prefiere un enfoque más automatizado, sin código, que admite hardware no NVIDIA y tipos de modelos diversos.
PyTorch torch.compile()
- Qué hace de forma diferente: torch.compile() es una característica nativa de PyTorch que crea modelos para mejorar el rendimiento, pero sigue confiando en gran medida en el runtime y las capacidades de optimización existentes de PyTorch.
- Comparación de precios: Gratis, ya que viene integrada en PyTorch.
- Elija esto si... desea una solución rápida e integrada dentro de PyTorch y se siente cómodo con el ajuste manual y una optimización menos agresiva que la que ofrece Forge.
- Manténgase con Forge Agent si... desea una optimización automatizada de alto nivel que no requiera intervención manual ni un conocimiento profundo de CUDA.
OpenVINO
- Qué lo distingue: OpenVINO es el kit de herramientas de Intel para optimizar modelos principalmente en hardware de Intel, con un enfoque en la aceleración de CPU y GPU integrada. Soporta modelos de varios marcos de trabajo, pero está menos centrado en GPU que Forge.
- Comparación de precios: Gratis y de código abierto.
- Elija esto si... su implementación es en hardware de Intel y desea herramientas de código abierto y con soporte de la comunidad.
- Manténgase con Forge Agent si... necesita optimizaciones específicas para GPU y soporte para tipos de modelos diversos más allá de las herramientas centradas en la CPU.
ONNX Runtime
- Qué lo distingue: ONNX Runtime es un motor de inferencia de alto rendimiento que admite modelos convertidos al formato ONNX. Ofrece amplio soporte de hardware y es ligero para su despliegue.
- Comparación de precios: Gratis y de código abierto.
Conclusión: ¿Deberías probar Forge Agent?
En general, le daría a Forge Agent una puntuación de alrededor de 7 de 10. Es una herramienta sólida si buscas sacar más rendimiento de tus cargas de trabajo de GPU sin perderte en los entresijos del ajuste de bajo nivel. Su gran atractivo es la automatización y la promesa de hasta 14x de velocidad con cero cambios de código, lo cual puede marcar la diferencia para equipos que buscan victorias fáciles.
Si eres ingeniero de aprendizaje automático o ingeniero de infraestructura manejando modelos grandes y necesitas optimización rápida y fiable, Forge merece una mirada seria. El hecho de que soporte una amplia gama de tipos de modelos y ofrezca automatización significa que puedes centrarte en tu trabajo principal en lugar de ajustar kernels.
Sin embargo, si te sientes cómodo con la optimización manual, o si tu hardware es principalmente Intel o no es de NVIDIA, podrías encontrar más valor en otro lugar. Además, si eres un equipo pequeño o un individuo probando cosas, la falta de información de precios clara y de reseñas de la comunidad podría hacerte dudar.
Para aquellos dispuestos a pagar por un rendimiento de grado empresarial, la automatización de Forge puede ahorrar grandes cantidades de tiempo. Si hay una prueba gratuita o demostración disponible, vale la pena probarla para ver si se ajusta a tu flujo de trabajo. Personalmente, recomendaría darle una oportunidad si tu principal punto de dolor es la velocidad de inferencia de GPU para modelos grandes. Si tu configuración ya está optimizada con otras herramientas, puede que no veas suficiente beneficio para justificar el cambio.
En resumen: Si quieres una herramienta de optimización de GPU sin complicaciones y de alto rendimiento, prueba Forge. Si te sientes más cómodo con el ajuste manual, o si tu configuración está fuera de su alcance, quizá sea mejor gastar tu dinero en soluciones alternativas como TensorRT o ONNX Runtime.
Preguntas frecuentes sobre Forge Agent
- ¿Vale la pena el dinero de Forge Agent? Depende de tus necesidades. Si tienes cuellos de botella en la inferencia de GPU y buscas automatización, podría ser una gran inversión. Pero sin precios transparentes, es difícil decir si es rentable para equipos pequeños.
- ¿Existe una versión gratuita? No se menciona de forma explícita ninguna capa gratuita ni prueba disponible públicamente. Es posible que necesites contactar con RightNow AI para acceso empresarial o de prueba.
- ¿Cómo se compara con NVIDIA TensorRT? TensorRT ofrece optimización profunda y manual, principalmente para hardware de NVIDIA, mientras que Forge automatiza la optimización en varios modelos y hardware, haciéndolo más accesible pero potencialmente menos afinado.
- ¿Puedo usar Forge con mis modelos personalizados? Sí, el asistente interactivo admite archivos PyTorch personalizados y otros tipos de cargas de trabajo, lo que lo hace flexible para varios proyectos.
- ¿Es compatible con múltiples marcos de trabajo? Sí, admite modelos de HuggingFace, PyTorch y otros, con el objetivo de una amplia compatibilidad.
- ¿Puedo obtener un reembolso si no me gusta? Las políticas de reembolso no están detalladas públicamente; deberás consultar directamente con RightNow AI.