¿Qué es Step 3.5 Flash?
Sinceramente, cuando supe por primera vez de Step 3.5 Flash, estaba bastante escéptico. Todo el bombo a su alrededor es que es un modelo de lenguaje grande (LLM) de código abierto construido para la velocidad, el razonamiento y para poder desplegarse en hardware de consumo. Entonces, naturalmente, me pregunté: ¿puede un modelo de IA realmente ofrecer el tipo de rendimiento que normalmente solo ofrecen grandes servidores en la nube? ¿O es esto sólo otra demostración elegante que falla en el uso real?
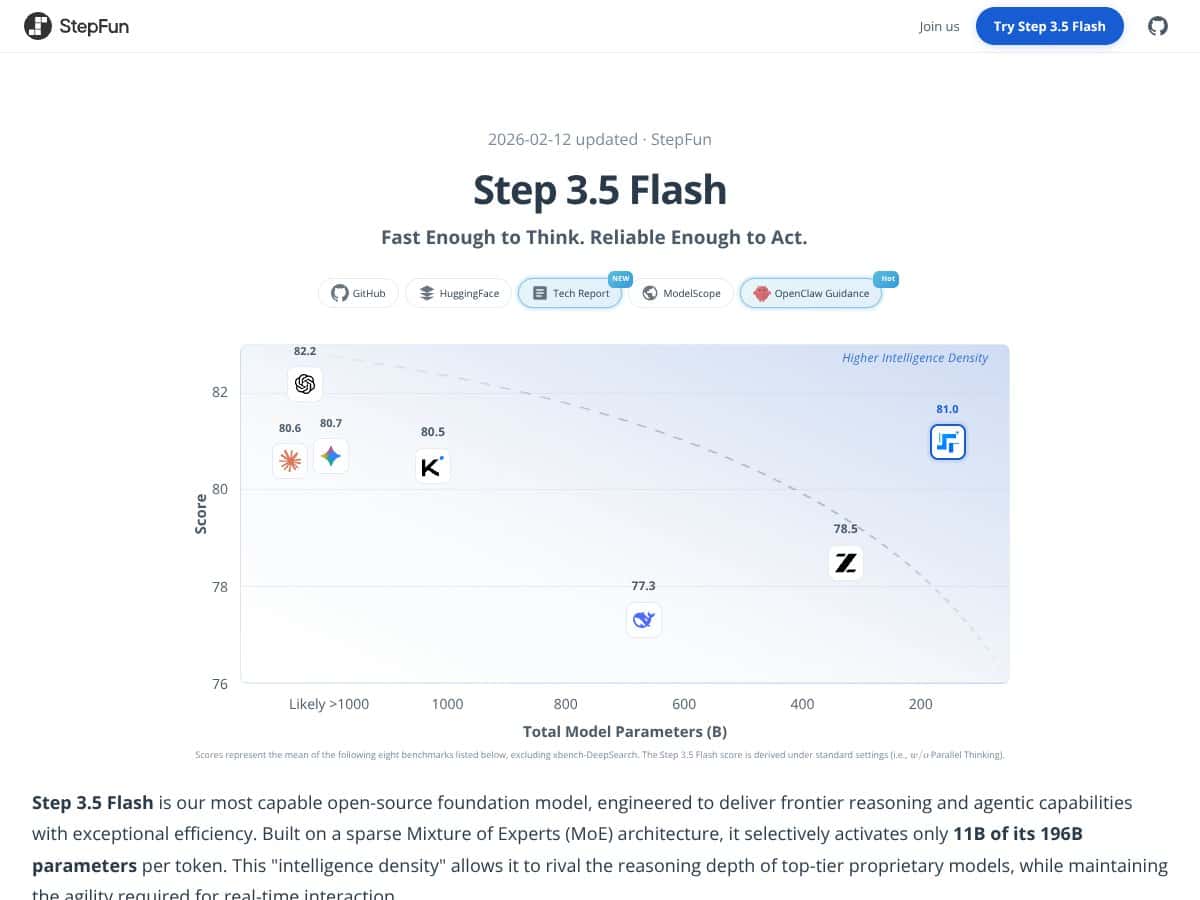
En términos simples, Step 3.5 Flash afirma ser un modelo de IA muy capaz que puede entender y generar textos complejos, realizar tareas de razonamiento e incluso ejecutarse localmente en hardware de consumo de gama alta. Está construido sobre una arquitectura de Mezcla de Expertos (MoE) dispersa, lo que significa que tiene un enorme número de parámetros (196 mil millones en total), pero solo activa una fracción de ellos en cualquier momento dado, lo que supuestamente lo hace más rápido y eficiente. Piensa en ello como un equipo muy grande donde solo unos pocos expertos son convocados para cada tarea, en lugar de que todos participen todo el tiempo.
El principal problema que intenta resolver: ¿cómo obtener potentes capacidades de razonamiento y codificación de IA sin depender de una infraestructura en la nube masiva y cara? Si funciona como se anuncia, podría hacer que la IA avanzada sea accesible para individuos y equipos pequeños sin necesitar alquilar acceso a grandes proveedores de nube o enfrentarse a preocupaciones de privacidad.
Los impulsores son StepFun AI, una empresa que ha estado promoviendo modelos de código abierto con un enfoque en la eficiencia y el despliegue local. No pude encontrar mucha información detallada sobre el equipo, pero el desarrollo del modelo parece basado en investigaciones recientes, especialmente en arquitecturas MoE dispersas y manejo de contextos largos.
¿Mi primera impresión? Bueno, me sorprendió descubrir que el modelo, de hecho, parece tan capaz como el bombo sugiere en las pruebas de rendimiento. Está diseñado para razonamiento, codificación y tareas con enfoque de agente, y parece cumplir en esos frentes. Dicho esto, quiero ser claro: no es un producto plug-and-play con una interfaz gráfica elegante ni una API simple. Es más bien una herramienta orientada a la investigación y a usuarios con experiencia tecnológica, que requiere cierta configuración y comprensión de los modelos de IA. Además, no esperes que sea perfecto en tareas multilingües o para manejar conversaciones cotidianas informales. Está más orientado a tareas especializadas y de alto rendimiento.
Otra advertencia: por lo que pude comprobar, no está diseñado para usuarios casuales o para proyectos a pequeña escala fuera de la caja. Está dirigido a desarrolladores, investigadores o aficionados que se sienten cómodos desplegando IA localmente y que manejan bien la integración de hardware y software. Si esperas un chatbot listo para usar con una interfaz amigable, no es éste.
Precio de Step 3.5 Flash: ¿Vale la pena?
| Plan | Precio | Qué Obtienes | Mi Opinión |
|---|---|---|---|
| Plan gratuito | Desconocido / No listado públicamente | Probablemente acceso limitado o restringido, probablemente solo para implementación local | Advertencia justa: los detalles del plan gratuito no están claros. Si quieres probar este modelo, espera limitaciones—probablemente en los límites de uso o en el acceso a funciones. Prepárate para restricciones que podrían dificultar una evaluación completa. |
| Acceso a la API a través de SiliconFlow | $0.10 por cada 1,000 tokens de entrada, $0.30 por cada 1,000 tokens de salida | API de pago por uso, escalable para proyectos pequeños a grandes, sin suscripción fija | Esto parece razonablemente asequible para un modelo avanzado, especialmente considerando su rendimiento de referencia. Pero ten en cuenta que los costos pueden sumar si procesas grandes volúmenes; planifica tu uso en consecuencia. |
| Acceso a la API a través de OpenRouter | $0.10 por cada 1,000 tokens de entrada, $0.30 por cada 1,000 tokens de salida | Similar a SiliconFlow, adecuado para quienes prefieren el ecosistema de OpenRouter | Mismo precio que SiliconFlow, así que no hay grandes sorpresas. Pero de nuevo, podrían existir límites de uso o puertas de características; revisa sus términos antes de un uso intensivo. |
| Despliegue Local | Gratis (Código abierto) | Ejecutarse en hardware de consumo de alta gama como Mac Studio M4 Max o NVIDIA DGX Spark | Esto es una gran ventaja para usuarios preocupados por la privacidad o los que tienen acceso a hardware potente. No hay tarifa de licencia, pero los requisitos de hardware no son triviales. |
Respecto a los precios, es bastante transparente si consideras el acceso a la API, con tarifas estándar de pago por uso que son competitivas para modelos de este calibre. La pregunta real es si tu volumen de uso justifica los costos, especialmente porque un alto rendimiento y el procesamiento de grandes volúmenes de tokens puede volverse costoso rápidamente. Una advertencia: si eres un aficionado o solo estás experimentando, los costos de la API podrían ser algo elevados en comparación con alternativas de código abierto. Para empresas o usuarios de gran uso, el valor en velocidad y eficiencia podría justificarlo.
Lo que no dicen en la página de ventas es si existen costos ocultos, como mantenimiento, infraestructura o posibles cargos por excedentes. Además, dado que los detalles del plan gratuito no están presentes, no asumas que es generoso; podría ser más bien un entorno de prueba o demostración limitado. Asegúrate de aclarar estos puntos antes de comprometerte.
¿Qué plan tiene sentido? Si eres un desarrollador o investigador en solitario que realiza pruebas ocasionales, las opciones de API gratuitas o de bajo costo podrían ser suficientes. Pero si vas a desplegar a gran escala—digamos que lo integres en un producto o servicio—querrás los planes de API, y deberías vigilar de cerca tu uso de tokens para evitar sorpresas.
Lo bueno y lo malo
Lo que me gustó
- Inferencia de alta velocidad: Alcanzar 100–300 tokens por segundo con razonamiento complejo es impresionante, especialmente para un modelo que se ejecuta localmente. Eso supone un cambio radical para las aplicaciones en tiempo real.
- Manejo eficiente de contextos largos: Soportar hasta 262 mil tokens con un mecanismo de atención híbrido significa que puedes procesar conjuntos de datos masivos o bases de código extensas sin esfuerzo. Eso es raro y de gran valor para flujos de trabajo específicos.
- Código abierto y despliegue local: Sin dependencia de la nube significa mejor privacidad y control de los datos. Ejecutarlo en hardware de consumo como el Mac Studio M4 Max lo hace accesible para aficionados serios y equipos pequeños.
- Resultados de benchmarks avanzados: Benchmarks como SWE-bench e IMO-AnswerBench demuestran que este modelo no es solo rápido: también es inteligente, especialmente en codificación, razonamiento y tareas con enfoque en agentes.
- Auto-mejora escalable: La inclusión de marcos de aprendizaje por refuerzo (RL) sugiere mejoras continuas y adaptabilidad, lo que es prometedor para el rendimiento futuro.
Qué podría mejorar
- Requisitos de hardware: Para sacar el máximo provecho de Step 3.5 Flash, necesitas hardware de gama alta, como Mac Studio M4 Max o NVIDIA DGX Spark, lo que no es factible para todos. Esto podría ser un factor decisivo para usuarios de pequeña escala o aquellos con equipos de gama baja.
- Ecosistema y herramientas limitados: Como modelo relativamente nuevo, el ecosistema alrededor de Step 3.5 Flash sigue siendo inmaduro. No se mencionan plugins, integraciones ni interfaces fáciles de usar, lo que podría ralentizar la adopción o complicar el despliegue.
- Sesgo de benchmarks: La mayoría de los benchmarks están en inglés y en dominios técnicos; el rendimiento en otros idiomas o en tareas menos estructuradas permanece sin verificar. Si tu trabajo es multilingüe o creativo, ten cuidado.
- Precios opacos y límites de uso: La falta de información detallada sobre las franjas gratuitas, cuotas o puertas de características dificulta la planificación a largo plazo. Si alcanzas límites, podrías necesitar cambiar a planes de pago de forma inesperada.
- Nuevo y en evolución: Al ser un lanzamiento reciente, existe el riesgo de errores, documentación incompleta o características que faltan que suelen acompañar a modelos en etapas tempranas. Prepárate para una curva de aprendizaje y posibles problemas de adaptación.
¿Para quién está realmente Step 3.5 Flash?
Si eres desarrollador, investigador o aficionado a la IA con acceso a hardware de alto nivel y una necesidad de razonamiento con contexto extenso y ultra rápido, este modelo podría encajar perfectamente. Es especialmente adecuado para tareas como codificación compleja, razonamiento de contexto largo, o la construcción de sistemas basados en agentes donde la privacidad y la velocidad son primordiales.
Por ejemplo, si trabajas en un asistente de IA que maneja grandes bases de código o documentos extensos en tu máquina local, Step 3.5 Flash ofrece la potencia y la flexibilidad para hacerlo sin dependencias de la nube. También es ideal para quienes quieran experimentar con arquitecturas de IA de vanguardia como MoE disperso, en un entorno práctico.
Sin embargo, si tu flujo de trabajo no requiere un contexto masivo o razonamiento en tiempo real basado en agentes —y especialmente si tienes un presupuesto ajustado o hardware de gama baja—esto podría ser excesivo. No está destinado a usuarios casuales o proyectos pequeños que no pueden justificar las inversiones en hardware o que no estén dispuestos a manejar la complejidad.
Quién debería mirar en otro lugar
Si tu necesidad principal es un modelo de lenguaje de uso general para tareas simples, o si no tienes acceso a hardware de alto rendimiento, esta no es la opción adecuada. Modelos como Llama 3.1 o alternativas de código abierto más pequeñas podrían servirte mejor, especialmente porque funcionan con hardware modesto y cuentan con un soporte comunitario más amplio.
Del mismo modo, si necesitas una solución lista para usar (plug-and-play) con una configuración mínima, o si prefieres un ecosistema maduro con plugins e integraciones dedicadas, espera a que este modelo madure o considera opciones ya consolidadas. Los modelos propietarios con acceso a la API de OpenAI, Anthropic o Google también podrían estar mejor adaptados si priorizas la facilidad de uso sobre el rendimiento puro.
Por último, si el soporte multilingüe o evaluaciones más diversas son cruciales para tu trabajo, ten en cuenta que el rendimiento de Step 3.5 Flash en esas áreas no está verificado. Podrías llevarte una decepción si tus expectativas están fuera de sus fortalezas actuales.
Cómo Step 3.5 Flash se compara con las alternativas
Mixtral 8x22B (Mistral AI)
- Qué hace de manera diferente: Mixtral 8x22B se apoya en una arquitectura de Mixture of Experts de alta eficiencia similar a Step 3.5 Flash, pero con un recuento de parámetros ligeramente menor (alrededor de 22B). Pone énfasis en pesos de código abierto y en una inferencia optimizada para un despliegue rápido, orientándose principalmente a tareas multilingües y de dominios más amplios.
- Comparación de precios: de código abierto, por lo que es gratuito para ejecutar localmente; los costos de la API en la nube son comparables, alrededor de 0,10–0,30 USD por millón de tokens.
- Elige este si... necesitas un modelo flexible, multilingüe, con buena eficiencia y pesos abiertos, especialmente si quieres experimentar con diferentes arquitecturas sin restricciones de hardware.
- Quédate con Step 3.5 Flash si... tu objetivo principal es razonamiento de vanguardia, codificación de alto rendimiento y capacidades basadas en agentes, especialmente si cuentas con hardware local de alta gama.
DeepSeek-V3
- Qué lo distingue: DeepSeek-V3 es también un modelo MoE de código abierto optimizado para codificación y matemáticas, con una ventana de contexto amplia. Enfatiza benchmarks sólidos en dominios técnicos similares a Step 3.5 Flash.
- Comparación de precios: Gratuito para implementación local; la API en la nube cuesta aproximadamente $0.10-$0.30 por token, similar a las opciones de API de Step 3.5 Flash.
- Elige esto si... buscas un enfoque en precisión técnica y manejo de contextos largos sin necesitar necesariamente las funciones más recientes de agente.
- Mantente con Step 3.5 Flash si... necesitas razonamiento multitarea superior, velocidad y una arquitectura flexible para flujos de trabajo con capacidades de agente.
Qwen2.5-Coder (Alibaba)
- Qué lo distingue: Qwen2.5-Coder está diseñado para tareas de codificación, ostenta altas puntuaciones SWE-bench y capacidades sólidas de codificación. Está diseñado específicamente para aplicaciones centradas en desarrolladores.
- Comparación de precios: De código abierto, por lo que es gratuito localmente; los costos de la API son similares, alrededor de $0.10-$0.30 por token.
- Elige esto si... tu enfoque principal es la codificación y las herramientas para desarrolladores, y menos el razonamiento general o tareas de contexto largo.
- Mantente con Step 3.5 Flash si... quieres un modelo más equilibrado con razonamiento, habilidades de agente y capacidades multitarea más allá de la codificación.
Llama 3.1 405B (Meta)
- Qué lo distingue: Llama 3.1 es un modelo denso a gran escala con razonamiento sólido y soporte multilingüe, pero requiere significativamente más potencia de cómputo y no está optimizado para tareas en tiempo real con capacidades de agente.
- Comparación de precios: Por lo general se accede a través de una API en la nube con costos más altos; la implementación local es exigente, requiriendo GPUs de gama alta o clústeres.
- Elige esto si... necesitas un modelo con razonamiento probado y habilidades multilingües, y cuentas con el hardware y el presupuesto para soportarlo.
- Mantente con Step 3.5 Flash si... quieres eficiencia y una implementación local en hardware de consumo, lo cual Llama 3.1 no soporta bien.
Conclusión: ¿Deberías probar Step 3.5 Flash?
En general, le daría a Step 3.5 Flash una puntuación sólida de 7.5 sobre 10. Es una potencia para su tamaño: ofrece una velocidad, eficiencia y capacidades de razonamiento impresionantes, especialmente si cuentas con hardware de gama alta. No es perfecto; necesitarás un hardware decente para realmente desbloquear su potencial, y aún es bastante nuevo en el ecosistema, por lo que algunas herramientas e integraciones pueden parecer inmaduras.
Si eres alguien que quiere un modelo flexible y de código abierto capaz de manejar codificación, matemáticas y tareas con contextos largos de forma local, definitivamente vale la pena probarlo. La naturaleza de código abierto significa que no hay costos de nube por adelantado, y es una buena manera de familiarizarse con arquitecturas MoE dispersas de vanguardia.
Sin embargo, si cuentas con un presupuesto ajustado, tienes hardware de gama baja o, principalmente, necesitas un modelo para tareas multilingües o de razonamiento general, quizá quieras mirar en otro lado—como Llama 3.1 si prefieres modelos densos, o Mixtral si buscas soporte multilingüe con pesos abiertos.
Personalmente, lo recomendaría si tienes buen manejo de la tecnología y buscas una solución local de alto rendimiento que pueda crecer con tus necesidades. Si solo estás experimentando de forma casual, podría ser excesivo, y modelos más simples podrían hacer el trabajo sin las complicaciones del hardware.
En resumen, pruébalo si estás listo para invertir en buen hardware y quieres explorar tecnología de vanguardia. Si no, podrías gastar mejor tu dinero y tu tiempo en opciones más establecidas o menos exigentes.
Preguntas frecuentes sobre Step 3.5 Flash
- ¿Vale la pena Step 3.5 Flash? Es gratis si lo hospedas tú mismo, pero el costo de hardware puede ser alto. Sus beneficios de rendimiento lo hacen valioso si necesitas razonamiento en tiempo real y despliegue local.
- ¿Existe una versión gratuita? Sí, puedes ejecutarlo localmente de forma gratuita, pero necesitas hardware de gama alta como Mac Studio M4 Max o NVIDIA DGX para un rendimiento óptimo.
- ¿Cómo se compara con Mixtral 8x22B? Ambos son modelos MoE eficientes, pero Step 3.5 Flash ofrece un razonamiento y capacidades de agente superiores, mientras que Mixtral es más multilingüe y flexible para uso general.
- ¿Puede manejar tareas multilingües? Actualmente, la mayoría de las pruebas se centran en el inglés; el rendimiento multilingüe está menos documentado, así que está principalmente optimizado para tareas centradas en el inglés.
- ¿Qué hay de contextos muy largos? Soporta contextos muy largos de hasta 262K tokens, lo que lo hace excelente para razonamiento complejo sobre documentos grandes.
- ¿Qué tan difícil es de configurar? Necesitarás ciertas habilidades técnicas para desplegar y optimizar en hardware de gama alta, pero la buena documentación está mejorando.
- ¿Puedo obtener soporte o reembolsos? Dado que es de código abierto, los reembolsos no son aplicables. El soporte depende de foros comunitarios y la documentación.





