Was ist APIEval-20?
Ehrlich gesagt, als ich zum ersten Mal auf APIEval-20 stieß, war ich ziemlich skeptisch. Die Idee eines Benchmarks, der prüft, ob eine KI tatsächlich Fehler in APIs finden kann — nur anhand eines Schemas und eines Muster-Payloads — klang interessant, aber auch etwas speziell. Ich habe schon viele API-Testing-Tools gesehen, die Testfälle generieren, aber die meisten von ihnen verlassen sich stark auf Dokumentation, Quellcode oder zumindest etwas Vorwissen über die Logik der API. Was mir auffiel, war die Behauptung, dass APIEval-20 darauf abzielt, KI-Agenten in einer Black-Box-Umgebung zu bewerten, ähnlich wie reale Tester oft vorgehen, wenn ihnen nur begrenzte Informationen vorliegen.
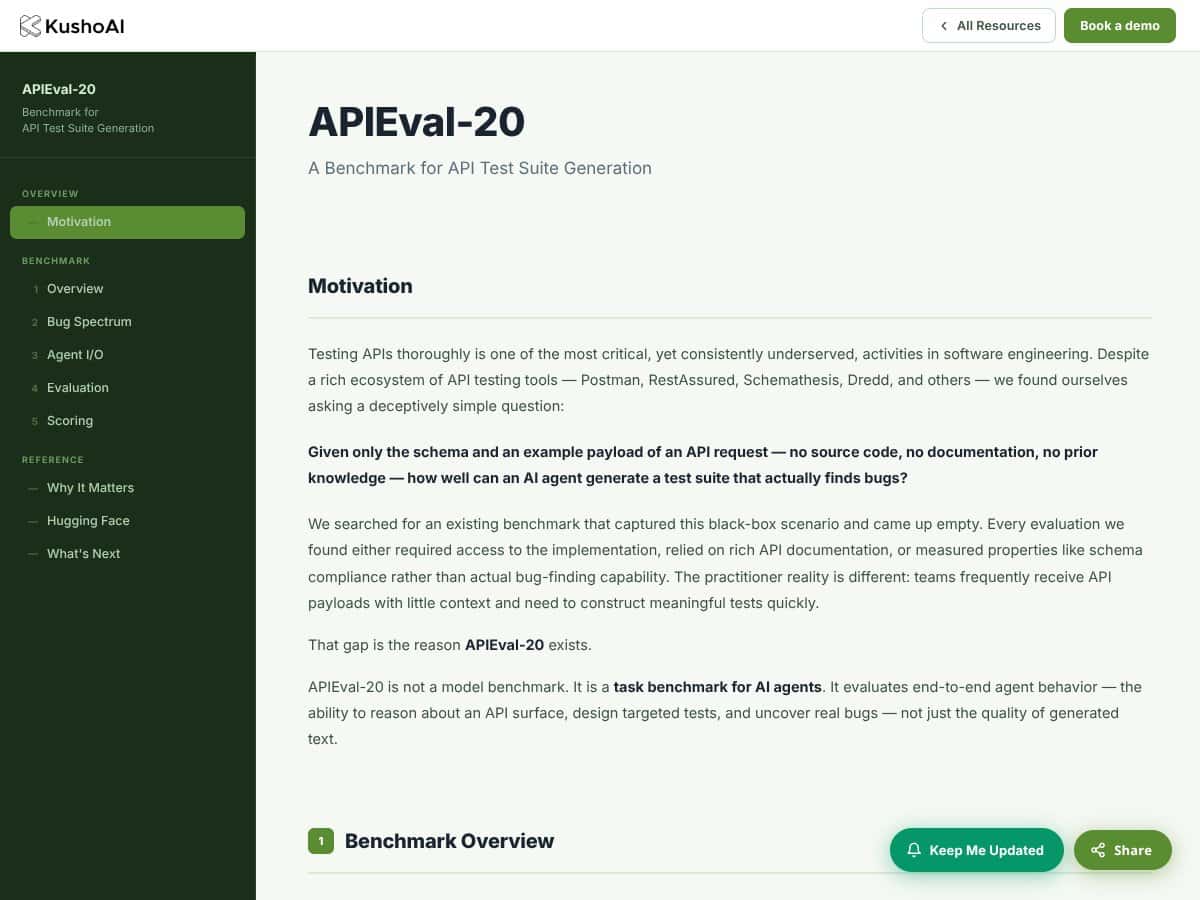
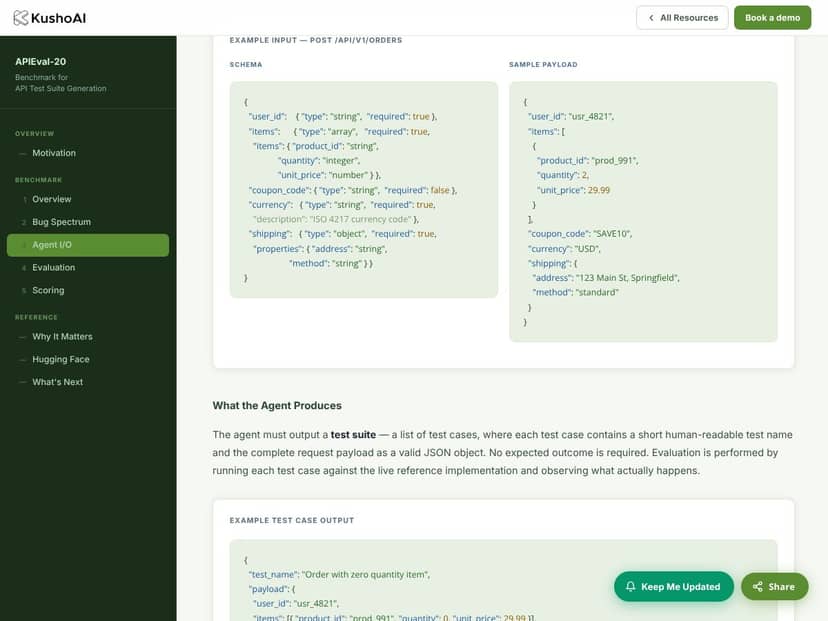
In einfachen Worten ist es eine Sammlung von 20 API-Szenarien aus verschiedenen Bereichen, von denen jedes mit eingebetteten Fehlern versehen ist. Die Aufgabe der KI besteht darin, Test-Suiten zu erstellen, die diese Fehler anhand des Schemas und eines einzigen Muster-Payloads aufdecken. Kein Quellcode, keine internen Dokumentationen — nur die oberflächlichen Details der API. Das Ziel ist nicht nur, hübsche Testskripte zu erzeugen; es geht darum zu sehen, ob die KI ausreichend logisch schlussfolgern kann, um tatsächliche Probleme zu finden, die ein menschlicher Tester möglicherweise entdecken könnte.
Nach dem, was ich herausfinden konnte, wird dieses Projekt von KushoAI entwickelt, einem Unternehmen, das offenbar auf KI-gestützte Testlösungen spezialisiert ist, obwohl das genaue Team hinter APIEval-20 nicht ausdrücklich beschrieben wird. Mein erster Eindruck war, dass es ein ernsthafter Versuch ist, über die einfache Testgenerierung hinauszugehen und tatsächlich die Fähigkeit zur Fehlererkennung auf realistische Weise zu messen.
Damit das klar ist: Es ist kein vollwertiges Test-Framework oder eine Automatisierungsplattform. Es ist ein Benchmark, speziell darauf ausgelegt, KI-Agenten zu bewerten, nicht um umfassende Testworkflows zu ersetzen. Erwarten Sie also nicht, dass es Dinge wie UI-Tests, exploratives Testen oder komplexe Integrationen abdeckt. Es ist eng fokussiert — was nicht unbedingt schlecht ist, aber es ist sinnvoll, die Erwartungen realistisch zu halten.
APIEval-20 Preisgestaltung: Lohnt es sich?
| Plan | Preis | Was Sie erhalten | Meine Einschätzung |
|---|---|---|---|
| Kostenlos | Kostenlos | Zugang zum offenen Benchmark-Datensatz, lokale Auswertungen möglich, beschränkt auf Kern-Szenarien | Großartig zum Experimentieren und Forschen, insbesondere wenn Sie KI-Modelle testen oder in Ihre eigenen Arbeitsabläufe integrieren. Allerdings im Umfang begrenzt und es fehlen möglicherweise fortgeschrittene Funktionen oder Unterstützung. |
| Kommerzieller/Erweiterter Zugriff | Preisdetails nicht öffentlich aufgeführt | Möglicher Zugriff auf weitere Szenarien, detaillierte Bewertungsberichte oder integrierte Evaluations-Pipelines, abhängig von den KushoAI-Angeboten | Guter Hinweis: Die Details sind unklar. Falls Sie einen kostenpflichtigen Plan in Erwägung ziehen, wenden Sie sich an KushoAI, um Klarheit zu erhalten. Erwarten Sie, dass der Hauptwert in Unternehmens- oder Forschungsumgebungen liegt, die konsistente Benchmarking benötigen. |
Zum Thema Preisgestaltung: Soweit öffentlich verfügbar, ist APIEval-20 im Wesentlichen kostenlos zugänglich und lokal auszuführen, was einen großen Vorteil für Forschungsteams und Entwickler darstellt, die ohne Vorabkosten experimentieren möchten. Wenn Sie jedoch nach fortschrittlichen Funktionen, gehosteten Evaluierungen oder Integrationen suchen, müssen Sie möglicherweise die anderen kostenpflichtigen Produkte von KushoAI in Betracht ziehen — Details bleiben jedoch spärlich.
Was sie auf der Verkaufsseite nicht sagen, ist, ob es Nutzungsbeschränkungen, API-Aufruf-Limits oder Funktionsbeschränkungen im kostenfreien Tarif gibt. Mein Eindruck ist, dass es offen ist und auf Hugging Face gehostet wird; der zentrale Benchmark-Datensatz und die Evaluationsskripte dürften kostenlos zugänglich sein, aber das Hochskalieren oder Enterprise-Support könnte Kosten verursachen.
Welcher Plan macht also Sinn? Wenn Sie Forscher sind, ein Entwickler, der die Bug-Findungs-Fähigkeiten Ihres KI-Agenten testen möchte, oder ein Team, das Benchmark-Datensätze erforscht, deckt der kostenfreie Zugriff wahrscheinlich Ihren Bedarf. Wenn Sie ein Unternehmen sind, das plant, dies in eine CI/CD-Pipeline oder Produkttests zu integrieren, müssen Sie KushoAI direkt kontaktieren — und mit potenziellen Kosten rechnen.
Zusammenfassend scheint die Preisgestaltung fair zu sein, angesichts der offenen, forschungsorientierten Natur. Achten Sie jedoch auf versteckte Einschränkungen, falls Sie skalieren oder stark in Produktionsumgebungen darauf angewiesen sind. Klären Sie immer mit KushoAI, was im kostenlosen Tarif enthalten ist und welche zusätzlichen Kosten möglicherweise anfallen.
Das Gute und das Schlechte
Was mir gefällt
- Objektive Bewertung mit Fokus auf reale Bugs: Im Gegensatz zu vielen Benchmarks, die sich auf subjektive Einschätzungen oder synthetische Metriken stützen, bewertet APIEval-20, ob der KI-Agent tatsächlich einen platzierten Bug aufdeckt – was deutlich sinnvoller ist.
- Black-Box-Bewertung: Die Einrichtung ahmt viele realweltliche Szenarien nach, bei denen Ihnen nur begrenzte Eingaben — Schema und Beispielpayloads — zur Verfügung stehen, wodurch die Testergebnisse besser auf praxisnahe API-Tests zugeschnitten sind.
- Mehrdomänen-Abdeckung: Mit Szenarien, die E-Commerce, Zahlungen, Authentifizierung und mehr umfassen, bietet es eine umfassende Sicht auf die Fehlererkennungsfähigkeiten eines KI-Agenten über verschiedene API-Stile und Komplexitätsgrade hinweg.
- Offener und reproduzierbarer Datensatz: Er wird auf Hugging Face gehostet und ist sowohl Forschern als auch Entwicklern zugänglich, was Transparenz und Community-Validierung fördert.
- Fördert ganzheitliches End-to-End-Denken: Der Benchmark betont die Fähigkeit des Agenten, das Verhalten von APIs zu verstehen und sinnvolle Tests zu erstellen — nicht nur plausible Code-Schnipsel zu generieren.
- Gezielt eingefügte Bugs unterschiedlicher Komplexität: Die Aufnahme von einfachen bis komplexen Bugs hilft, die Tiefe des Verständnisses einer KI und ihre Fähigkeit zur Fehlerentdeckung zu bewerten – nicht nur oberflächliche Probleme.
Was könnte besser sein
- Begrenzte Szenarienauswahl: Mit nur 20 Szenarien erfasst es möglicherweise nicht die Vielfalt realer APIs vollständig, insbesondere Nischen- oder hochspezialisierte APIs. Dies könnte seine Anwendbarkeit für einige Branchen einschränken.
- Fehlende benutzerfreundliche Dokumentation oder Benutzeroberfläche: Als Forschungsbenchmark ist es eher ein Rohdatensatz und ein Evaluationsskript als ein ausgereiftes Produkt. Für Teams ohne KI-Expertise könnte die Einrichtung nicht trivial sein.
- Keine klare Bewertungsstruktur oder Konfidenzmaße: Obwohl es die Fehlererkennung bewertet, sind Details dazu, wie Teilabdeckung oder Falsch-Positive gehandhabt werden, nicht transparent, was vergleichende Analysen erschweren könnte.
- Begrenztes Community-Feedback: Als neuer Benchmark gibt es noch nicht eine Fülle unabhängiger Bewertungen oder Fallstudien, die reale Auswirkungen oder Best Practices bei der Skalierung demonstrieren.
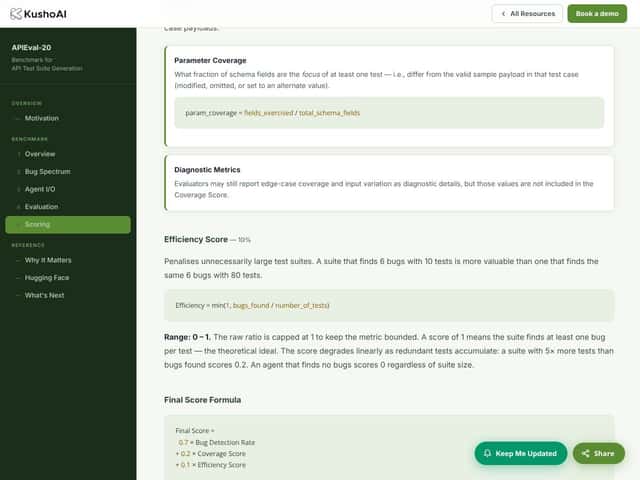
- Fokus auf Fehlererkennung, nicht auf eine vollständige Test-Suite: Wenn Ihr Ziel eine umfassende API-Testsuite ist, einschließlich Lasttests, Sicherheitsprüfungen oder Compliance-Checks, ist dieser Benchmark dafür nicht ausgelegt.
Für wen ist APIEval-20 eigentlich gedacht?
Wenn Sie Forscher oder Entwickler sind, die an KI-gestützten API-Testing-Tools arbeiten, ist APIEval-20 ein überzeugender Benchmark. Er ist speziell darauf ausgelegt, diejenigen zu unterstützen, die beurteilen möchten, ob ihre Modelle das Verhalten von APIs nachvollziehen und echte Bugs mit minimalem Input aufdecken können. Beispielsweise, wenn Sie ein LLM entwickelt haben, das behauptet, Testfälle zu generieren, und Sie eine Möglichkeit benötigen, objektiv zu messen, wie gut es Bugs findet, bietet dieser Benchmark eine standardisierte Methode, dies zu tun.
Es ist auch ideal für Teams, die KI-Integration in ihre bestehenden Testabläufe erforschen. Angenommen, Sie haben einen KI-Agenten, der, ausgehend von nur einem API-Schema und Beispieldaten, gezielte Tests erstellen muss, um Fehler in einer Live-Umgebung zu finden. APIEval-20 kann als Validierungsschritt dienen, um Verbesserungen im Laufe der Zeit zu quantifizieren oder verschiedene Modelle zu vergleichen.
In der Praxis funktioniert dies gut für QA-Ingenieure, KI-Forscher und Automatisierungsteams, die eine wiederholbare Black-Box-Herausforderung wünschen, die ihre Modelle dazu bringt, über API-Logik nachzudenken, statt lediglich plausible Code-Schnipsel zu erzeugen. Es ist nicht für Gelegenheitnutzer oder diejenigen gedacht, die eine umfassende Prüfung in Bereichen wie UI, Leistung oder Sicherheit suchen — es ist ein gezielter Benchmark für die Erkennung von Fehlern.
Wer sollte woanders suchen
Wenn Ihr Ziel allgemeine API-Tests sind, zum Beispiel das Automatisieren von Postman-Sammlungen, oder Sie UI-Workflows verifizieren müssen, ist APIEval-20 wahrscheinlich nicht das richtige Tool. Es konzentriert sich eng auf Fehlererkennung basierend auf minimalen Eingaben, daher gibt es bessere Optionen, wenn Sie eine breite Test-Suite, Lasttests oder Sicherheitsprüfungen benötigen — wie LoadRunner, OWASP ZAP oder die integrierten Funktionen von Postman.
Ähnlich verhält es sich, wenn Sie nicht an der Entwicklung oder Forschung von KI-Modellen arbeiten und einfach nur eine einfache Möglichkeit suchen, Ihre APIs zu testen, könnte dieser Benchmark zu abstrakt oder komplex wirken. Er erfordert eine gewisse Vertrautheit mit KI-Bewertungs-Setups und bietet möglicherweise nicht die sofortige Benutzerfreundlichkeit oder Benutzeroberfläche, die ein typisches QA-Team erwartet.
Für Teams, die eine schlüsselfertige Lösung mit detaillierten Berichten, Dashboards oder Integrationen in bestehende CI/CD-Pipelines suchen, könnten die kommerziellen Angebote von KushoAI (hier nicht im Detail erläutert) besser geeignet sein. Beachten Sie, dass APIEval-20 als Forschungsbenchmark darauf abzielt, kontrollierte, vergleichende Experimente durchzuführen, statt vollständige Testplattformen bereitzustellen.
Wie APIEval-20 im Vergleich zu Alternativen abschneidet
SWE-bench
- Was es anders macht: SWE-bench konzentriert sich stärker darauf, allgemeine Software-Engineering-Fähigkeiten zu bewerten, einschließlich Code-Korrektheit, Tests und Debugging in mehreren Programmiersprachen. Es ist umfassender in der Bewertung der Programmierfähigkeit als bei der rein API-spezifischen Fehlererkennung. - Preisvergleich: SWE-bench ist typischerweise ein kostenpflichtiger Dienst mit Abonnementoptionen, der je nach Nutzung oft mehrere Hundert Dollar pro Monat kostet. - Wählen Sie diese Option, wenn Sie eine umfassende Software-Engineering-Bewertung benötigen, die Codierung und Debugging zusätzlich zu API-Tests umfasst. - Bleiben Sie bei APIEval-20, wenn Ihr Hauptziel darin besteht, objektiv die Fähigkeit einer KI zu messen, API-spezifische Bugs nur anhand von Schema und Payloads zu finden.APIBench
- Was es anders macht: APIBench bietet eine Suite von API-Testing-Szenarien, basierend auf realen API-Sammlungen, oft in Tools wie Postman integriert. Es legt Wert auf manuelle und halbautomatisierte Testworkflows. - Preisvergleich: Viele APIBench-Sammlungen sind kostenlos oder in Tools wie Postman enthalten, aber umfassende Enterprise-Versionen können Hunderte pro Monat kosten. - Wähle dies aus, wenn du eine praxisnahe Testumgebung suchst, die sich in vorhandene API-Testing-Tools integrieren lässt. - Bleibe bei APIEval-20, wenn du eine objektive, benchmarking-basierte Bewertung der KI-Fehlererkennung statt einer Testumgebung benötigst.HumanEval
- Was es anders macht: HumanEval ist darauf ausgelegt, Code-Generierungsmodelle danach zu bewerten, ob sie korrekte Lösungen zu Programmieraufgaben liefern, wobei der Fokus auf der Korrektheit des Codes liegt und nicht auf dem Testen. - Preisvergleich: In der Regel kostenlos als Teil offener Forschungsdatensätze oder auf bestimmte Benchmarks. - Wähle dies aus, wenn dein Fokus auf der Genauigkeit der Codegenerierung liegt, nicht auf der API-Fehlererkennung. - Bleibe bei APIEval-20, wenn du einen Benchmark speziell für API-Tests und das Auffinden von Fehlern benötigst.Postman Collections / Postman AI
- Was es anders macht: Postman bietet eine benutzerfreundliche Oberfläche für manuelle und halbautomatisierte API-Tests, einschließlich KI-gestützter Testgenerierung, ist jedoch nicht als Benchmark konzipiert oder für eine objektive Fehlererkennungsbewertung vorgesehen. - Preisvergleich: Kostenlose Stufe verfügbar; kostenpflichtige Pläne beginnen bei rund 8 USD pro Benutzer/Monat für zusätzliche Funktionen. - Wähle dies aus, wenn du eine leicht zu bedienende Plattform für manuelle API-Tests und Zusammenarbeit suchst. - Bleibe bei APIEval-20, wenn du eine objektive, reproduzierbare Benchmark für KI-Fehlererkennung benötigst, nicht nur ein Testing-Tool.Fazit: Solltest du APIEval-20 ausprobieren?
Insgesamt würde ich APIEval-20 mit etwa 7 von 10 bewerten. Es ist ein solider Schritt nach vorn bei der objektiven Messung der Fähigkeit einer KI, echte Fehler in APIs zu finden – insbesondere angesichts der Spezialisierung dieses Gebiets. Das Black-Box-Setup und der Fokus auf tatsächliche Fehlererkennung machen es zu einem sinnvollen Benchmark, aber es ist noch relativ neu, und sein Umfang ist auf 20 Szenarien begrenzt. Wenn dein Team KI-Testing-Tools prüft oder Fähigkeiten zur Bug-Erkennung erforscht, lohnt sich ein Blick darauf.
Definitiv, wenn du in einer technischen Umgebung arbeitest, in der API-Zuverlässigkeit entscheidend ist und du sehen möchtest, wie nah deine KI-Tools an einen QA-Ingenieur herankommen, probier es aus. Die kostenlose Stufe ist eine gute Möglichkeit, es auszuprobieren, ohne Verpflichtungen einzugehen. Wenn du eine umfassende QA-Abdeckung, UI-Tests oder End-to-End-System-Debugging benötigst, solltest du es durch andere Tools ergänzen.
Persönlich würde ich es empfehlen, wenn dein Ziel speziell das Benchmarking der KI-Fehlererkennung ist. Wenn du gerade erst anfängst oder eine umfassendere Test-Suite benötigst, findest du möglicherweise bei etablierten Tools wie Postman oder SWE-bench einen größeren Mehrwert. Aber für reine API-Fehlererkennung ist APIEval-20 eine vielversprechende, offene Option.
Häufige Fragen zu APIEval-20
Ist APIEval-20 sein Geld wert?
Ja, besonders, weil es kostenlos und offen ist. Es geht mehr um den Wert von Benchmarking und Forschung als um direkte kommerzielle Investitionen.
Gibt es eine kostenlose Version?
Ja, der Datensatz und der Benchmark werden offen auf Hugging Face gehostet und können lokal kostenlos ausgeführt werden. Für den Zugriff sind keine kostenpflichtigen Stufen erforderlich.
Wie schneidet es im Vergleich zu anderen Benchmarks ab?
Im Vergleich zu allgemeinen Code-Benchmarks wie HumanEval ist APIEval-20 spezialisierter und praktischer für API-Tests. Es ist realistischer als synthetische Tests, aber der Umfang ist enger.
Kann es mehrstufige API-Workflows bewerten?
Ja, es enthält Szenarien mit mehrstufigen Prozessen, die die Fähigkeit eines Agenten testen, komplexe Interaktionen zu bewältigen.
Testet es die Fehlerbehandlung und Randfälle?
Auf jeden Fall; viele Szenarien konzentrieren sich auf Fehlerantworten, Schema-Beschränkungen und ungewöhnliche Payloads, um die Robustheit der KI herauszufordern.
Kann ich eine Rückerstattung erhalten?
Da der Benchmark kostenlos und offen ist, sind Rückerstattungen nicht möglich. Für kommerzielle Produkte prüfen Sie bitte die spezifischen Richtlinien des jeweiligen Anbieters.