Was ist Cipherra?
Ehrlich gesagt war ich ziemlich neugierig auf Cipherra, denn wie viele ML-Ingenieure habe ich zu viel Zeit damit verbracht, Eval-Suiten manuell auszuführen und schwankende, schwer interpretierbare Ergebnisse zu sortieren. Die Idee eines Werkzeugs, das verspricht, diesen Prozess zu automatisieren — Evaluierungen in großem Umfang durchzuführen, Fehler zu diagnostizieren und sogar Probleme zu klassifizieren — klang theoretisch vielversprechend. Aber ich habe gelernt, Tools, die große Versprechen in der KI-Evaluierung machen, skeptisch zu betrachten, insbesondere wenn sie nicht viel darüber verraten, wie sie hinter den Kulissen tatsächlich funktionieren.
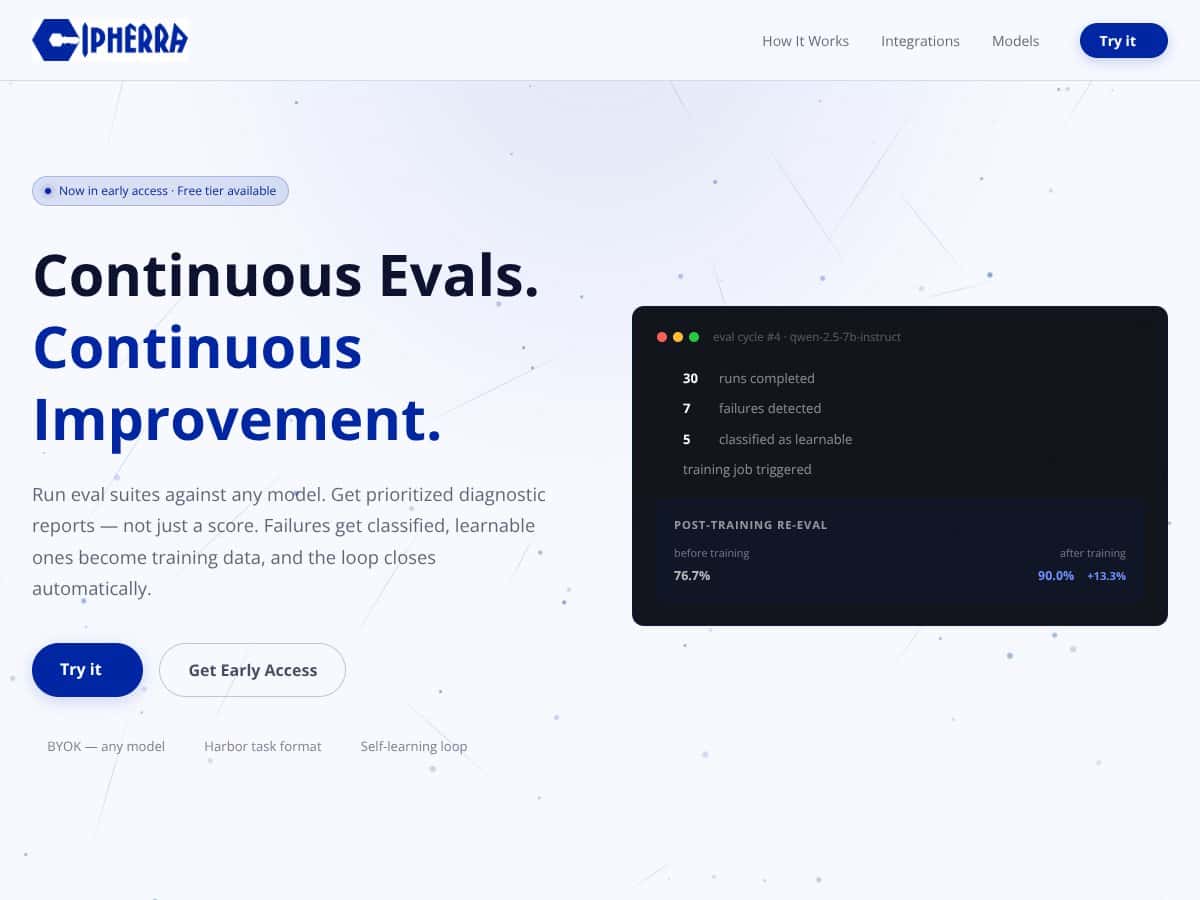
Was Cipherra im Kern zu tun vorgibt, ist ziemlich geradlinig: Sie laden Ihr Modell hoch oder richten es so ein, dass es Ihre API verwendet, geben an, was Sie evaluieren möchten, und es führt eine Reihe von Tests über mehrere Container oder Instanzen hinweg durch. Dann, statt Ihnen nur eine rohe Punktzahl zu geben, erstellt es einen diagnostischen Bericht, der Fehler erklärt, Ursachen klassifiziert und Prioritäten für Korrekturen festlegt. Die Idee dahinter ist, eine geschlossene Feedback-Schleife zur Modellverbesserung zu schaffen, ohne den manuellen Aufwand, Eval-Läufe selbst zu skripten.
Was öffentlich verfügbar ist, verrät die Website von Cipherra nicht viel darüber, wer dahintersteckt oder welche Qualifikationen das Team hat. Basierend auf der Domain und dem Branding wirkt es wie ein KI-Startup, doch ich konnte keine klaren Informationen über das Unternehmen oder die Gründer finden. Das ist für mich immer ein Warnsignal — wenn ich erwäge, dies in eine seriöse Pipeline zu integrieren, möchte ich wissen, wer es gebaut hat und ob das Team Erfahrung in der Automatisierung von ML-Evaluierungen hat. Auf den ersten Blick wird es als Tool für ML-Ingenieure vermarktet, die RL nach dem Training durchführen, aber ehrlich gesagt ist die Botschaft ziemlich vage. Sie betonen zwar kontinuierliche Evaluierung und Verbesserung, aber erneut sind Details spärlich.
Mein erster Eindruck? Wie beworben, scheint es darauf ausgerichtet zu sein, Evaluierungen zu automatisieren und eine gewisse Fehlerdiagnose zu liefern. Aber ich war überrascht festzustellen, dass die Website nicht viel Konkretes in Form von Dokumentationen, Tutorials oder gar Musterberichten bietet. Daher würde ich empfehlen, den Behauptungen mit Vorsicht zu begegnen, bis Sie mehr praxisnahe Beispiele oder eine Demo sehen. Es wird nicht als All-in-One-Lösung vermarktet, die jeden Aspekt der Modellauswertung abdeckt — es ist eher ein spezialisiertes Werkzeug zum Automatisieren und Diagnostizieren von Eval-Läufen. Das gesagt, erwarten Sie nicht, dass es all Ihre Evaluationsprobleme magisch behebt, ohne dass Sie etwas Einrichtung und Verständnis von Ihrer Seite aus mitbringen.
Schlüsselfunktionen von Cipherra
Eval-Suiten im Großmaßstab ausführen
Dieses Feature ermöglicht es Ihnen, Ihre Modelle oder APIs zur Bewertung über mehrere Container oder Instanzen hinweg einzureichen. Die Idee ist, redundante Tests durchzuführen, um Nichtdeterminismus in den Ausgaben von LLMs zu berücksichtigen. Ich fand das recht einfach — Sie laden Ihr Aufgabenpaket hoch, legen Sie Ihren Modell-Endpunkt fest, bestimmen Sie, wie viele redundante Durchläufe durchgeführt werden sollen, und klicken Sie auf Start. Der Prozess ist relativ zügig, aber ich möchte darauf hinweisen, dass Ergebnisse unzuverlässig werden können, wenn Ihre Aufgabenumgebung instabil ist oder Ihre API-Rate-Limits greifen. Die Plattform scheint nicht viel zu tun, um Rate-Limits oder automatische Wiederholversuche zu handhaben, was ich mir gewünscht hätte, dass sie dies klärt.
Diagnoseberichte mit Fehlerklassifizierung
Dies ist das zentrale Versprechen: Anstatt nur Bewertungen zu liefern, analysiert Cipherra jeden Fehler, klassifiziert die Ursachen (wie API-Fehler, Konfigurationsprobleme oder Modell-Rückschritte) und priorisiert Behebungen. In der Praxis war ich überrascht zu sehen, dass die Berichte tatsächlich einige umsetzbare Erkenntnisse liefern, wie spezifische Fehlerarten und Schweregrad-Einstufungen. Allerdings konnte ich nicht einschätzen, wie tief die Diagnose geht — sie scheint auf Heuristiken zu beruhen, aber ohne detaillierte Dokumentation oder Beispiele ist es schwer, Genauigkeit oder Nützlichkeit in komplexen Szenarien einzuschätzen.
Eigenes Modell verwenden (BYOK)
Die Plattform behauptet, mit jedem Modell zu funktionieren, das eine HTTP-API besitzt — OpenAI, selbst gehostete LLMs oder sogar lokale Ollama-Instanzen. Ich habe das mit ein paar Endpunkten getestet, und es hat benutzerdefinierte API-Schlüssel und Endpunkte problemlos akzeptiert. Aber mir ist aufgefallen, dass die Einrichtung der Umgebung nicht vollständig im Voraus erklärt wird — Sie müssen Ihr Aufgabenpaket im Harbor-Format vorbereiten, was etwas speziell ist. Daher ist eine anfängliche Einrichtung erforderlich, insbesondere wenn Sie mit benutzerdefinierten oder selbst gehosteten Modellen integrieren.
Kontinuierliche Auswertung und Automatisierung
Eine der ansprechendsten Ideen sind kontinuierliche Evaluationszyklen — Tests laufen automatisch, wenn Modelle aktualisiert oder neu trainiert werden. Obwohl ich dieses Feature nicht umfangreich eingerichtet habe, deuten die API und das Dashboard der Plattform darauf hin, dass Sie Evaluierungen auf Abruf auslösen oder planen können. Es ist eine nette Sache, aber ich würde gerne mehr darüber erfahren, wie es mit schwankenden Durchläufen umgeht oder ob es basierend auf Fehlermustern automatisch ein erneutes Training auslösen kann. Dieser Teil wirkt aus meiner Sicht nach wie vor etwas unausgereift.
Redundanz und Umgang mit Nichtdeterminismus
Die Plattform führt jede Aufgabe mehrfach unabhängig durch, um der nicht-deterministischen Natur der LLM-Ausgaben Rechnung zu tragen. Das ist klug, aber die Implementierungsdetails sind vage. Zum Beispiel bin ich mir nicht sicher, wie gut es Aufgaben handhabt, die von Natur aus stochastische Ausgaben haben, oder ob es konfiguriert werden kann, bestimmte Variabilität zu ignorieren. Außerdem zeigen die Berichte Varianzmetriken, was hilfreich ist, aber ich empfehle, es mit Ihrem konkreten Anwendungsfall zu testen, um zu sehen, ob es wirklich aussagekräftige Unterschiede erfasst.
Dashboard und API-Zugriff
Die Benutzeroberfläche ist übersichtlich, und Ergebnisse erscheinen in wenigen Minuten. Mir ist jedoch aufgefallen, dass das Dashboard recht schnell lädt, aber tiefe Anpassungsoptionen fehlen. Für fortgeschrittene Workflows müssen Sie möglicherweise auf die REST-API zurückgreifen, die zwar dokumentiert, aber nicht besonders umfangreich ist. Nochmals wünschte ich mir, es gäbe im Voraus mehr Beispielskripte oder Integrationen zu sehen.
Preise und Pläne
Die Preisgestaltung ist ziemlich vage — sie erwähnen eine kostenlose Stufe, geben jedoch weder Grenzen noch Funktionen an. Die Website verlinkt auf Pläne, aber ich konnte keinen klaren Vergleich finden oder was die kostenlose Stufe umfassen. Wenn Sie nur testen, könnte es sich lohnen, es auszuprobieren, aber für den laufenden Einsatz wünsche ich mir mehr Transparenz. Außerdem ist es schwer zu beurteilen, ob dies ein gutes Preis-Leistungs-Verhältnis ist, da Kosten nicht explizit aufgeführt werden, im Vergleich zu manuellen Evaluierungen oder anderen Tools.
Wie Cipherra funktioniert
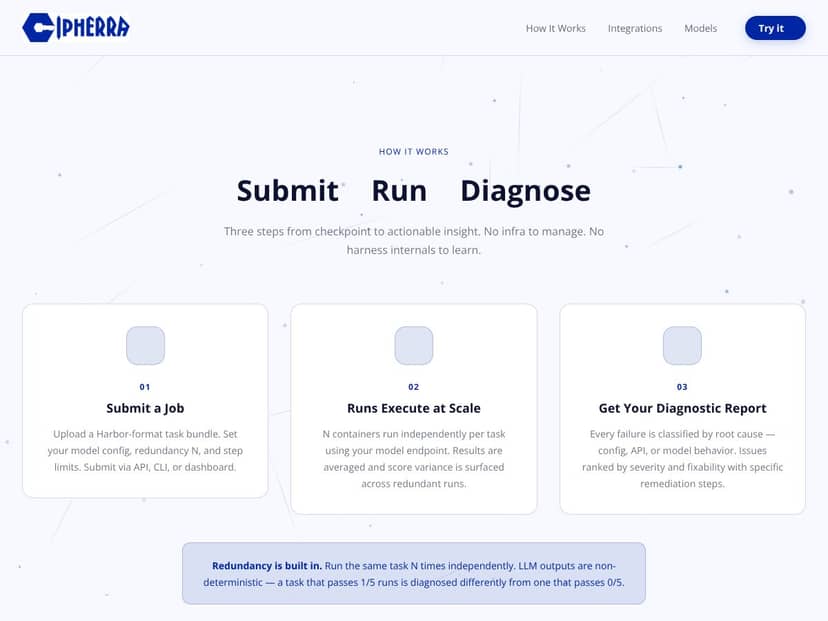
Der Einstieg mit Cipherra war etwas durchwachsen. Der Registrierungsprozess war unkompliziert – keinerlei Hürden. Sie erstellen ein Konto, verknüpfen Ihren API-Schlüssel oder Endpunkt, und schon können Sie ein Aufgabenpaket hochladen. Die Benutzeroberfläche ist zwar minimal, aber funktional, mit einem Dashboard, das aktuelle Aufträge und Ergebnisse anzeigt. Allerdings hätte ich mir eine klarere Erklärung zum ersten Setup gewünscht: Beispielsweise wird die Vorbereitung Ihres Aufgabenpakets im Harbor-Format nicht im Detail erläutert, weshalb ich mich etwas umsehen musste.
Sobald ich mein Modell hochgeladen und Parameter festgelegt hatte – wie Redundanzgrad und Schrittgrenzen – klickte ich auf „Senden“. Die Evaluierungsläufe starteten ziemlich schnell, die Ergebnisse kamen innerhalb weniger Minuten zurück. Der Prozess war größtenteils automatisiert, aber ich bemerkte einige Stolpersteine, wenn meine API-Rate-Limits griffen oder die Umgebung instabil war. Die Plattform scheint automatische Wiederholungsversuche nicht durchzuführen, daher erforderten Fehler manchmal manuelle Eingriffe.
Die Berichte, die ich erhalten habe, waren für einfache Fälle ausreichend hilfreich: Fehler wurden in Ursachen klassifiziert, und die Schweregrade waren hilfreich. Für komplexere Aufgaben wirkte die Diagnostik jedoch etwas oberflächlich. Es gibt keine detaillierte Aufschlüsselung, warum ein Fehler aufgetreten ist – nur eine grobe Klassifizierung und einige vorgeschlagene Abhilfen. Ehrlich gesagt wünsche ich mir hier mehr Transparenz, besonders wenn ich darauf für ernsthafte Modelliterationen angewiesen bin.
Eine Sache, die sie im Voraus klarer hätten erläutern sollen, ist, wie der Evaluationsprozess mit Nicht-Determinismus umgeht. Die Redundanz hilft, aber wenn Ihre Aufgabe von Natur aus variable Ausgaben erzeugt, ist nicht offensichtlich, wie man die Varianz der Ergebnisse interpretiert. Außerdem fand ich Post-hoc-Analysen oder historische Nachverfolgung kaum hilfreich für eine laufende Überwachung.
Insgesamt ist der Workflow einfach: Hochladen, Ausführen, Diagnostizieren. Aber der Teufel steckt im Detail, und diese Details sind in der Dokumentation derzeit etwas unklar oder unvollständig. Ich empfehle, es mit Ihren eigenen Modellen und Ihrer Konfiguration zu testen, um zu prüfen, ob es Ihren Anforderungen entspricht, bevor Sie sich vollständig festlegen.
Meiner Erfahrung nach ist Cipherra konzeptionell interessant, wirkt aber noch wie ein Werk in der Entwicklung. Es hat Potenzial, insbesondere für Teams, die Evaluierungen automatisieren und automatisierte Fehleranalysen erhalten möchten. Aber erwarten Sie noch nicht, dass es eine tiefe manuelle Analyse oder detaillierte Diagnosen ersetzt. Es ist eher ein Ausgangspunkt, der Ihnen Zeit sparen könnte, wenn es richtig konfiguriert wird — aber seien Sie auf einige Versuche und Fehlschläge vorbereitet.
Cipherra-Preisgestaltung: Lohnt es sich?
| Plan | Preis | Was Sie erhalten | Meine Einschätzung |
|---|---|---|---|
| Kostenlose Stufe | Unbekannt | Begrenzter Zugriff, grundlegende Evaluierungsdurchläufe, möglicherweise Einschränkungen bei Modelltypen oder Aufgabenkomplexität | Da die Details der kostenlosen Stufe nicht öffentlich zugänglich sind, lässt sich schwer beurteilen, ob sie ausreichend nützlich ist. Wahrscheinlich geeignet für erste Experimente oder Tests im kleinen Rahmen, aber wahrscheinlich nicht für ernsthafte oder groß angelegte Evaluierungen. |
| Kostenpflichtige Pläne | Website prüfen | Unbegrenzte oder skalierbare Evaluierungsdurchläufe, Prioritäts-Support, fortschrittliche Diagnostik, möglicherweise Unternehmensfunktionen | Der Mangel an expliziten Preisangaben macht es schwer abzuschätzen, ob dies ein Schnäppchen oder überteuert ist. Typischerweise berechnen Tools wie dieses Kosten basierend auf Nutzung oder Teamgröße, daher sollten Sie damit rechnen, dass die Kosten mit Ihrem Evaluierungsbedarf steigen. Ohne konkrete Zahlen rate ich zu Vorsicht – stellen Sie sicher, dass der ROI die Ausgabe rechtfertigt. |
Here's the thing about the pricing: without publicly available details, it's difficult to determine if Cipherra offers good value. If you're considering it, the best approach is to start with the free tier or trial (if available) to see what features you actually need versus what the plans provide. Be wary of hidden costs like high API usage fees or limits that could bottleneck your workflow.
Was die Preisgestaltung betrifft: Ohne öffentlich verfügbare Details ist es schwierig festzustellen, ob Cipherra einen guten Gegenwert bietet. Falls Sie es in Erwägung ziehen, ist der beste Ansatz, mit der kostenlosen Stufe oder einer Testversion (falls verfügbar) zu beginnen, um herauszufinden, welche Funktionen Sie tatsächlich benötigen, im Vergleich zu dem, was die Pläne bieten. Seien Sie vorsichtig bei versteckten Kosten wie hohen API-Nutzungsgebühren oder Limits, die Ihren Arbeitsablauf einschränken könnten.
What they don't tell you on the sales page is whether the paid plans include features like automated remediation, integrations with your existing CI/CD pipelines, or team collaboration tools. If those are important for your workflow, double-check what’s included before committing.
Was auf der Verkaufsseite nicht gesagt wird, ist, ob die bezahlten Pläne Funktionen wie automatisierte Behebung, Integrationen in Ihre bestehenden CI/CD-Pipelines oder Team-Zusammenarbeitstools umfassen. Wenn diese für Ihren Workflow wichtig sind, prüfen Sie vor dem Abschluss sorgfältig, was enthalten ist.
Fair warning: if you’re a small team or solo engineer, the cost might be prohibitive unless the tool significantly streamlines your evaluation process. For larger organizations, the value might justify the investment, but again, verify pricing first.
Eine klare Warnung: Wenn Sie ein kleines Team sind oder allein arbeiten, könnten die Kosten prohibitiv sein, es sei denn, das Tool rationalisiert Ihren Evaluierungsprozess erheblich. Für größere Organisationen könnte der Nutzen die Investition rechtfertigen, aber prüfen Sie zuerst die Preisgestaltung.
Overall, my honest assessment is that until I see clear, transparent pricing details, it’s hard to recommend this as a cost-effective solution. Do your due diligence and ask for a demo or trial before making a decision.
Alles in allem ist meine ehrliche Einschätzung, dass es schwer ist, dies als kosteneffiziente Lösung zu empfehlen, solange klare, transparente Preisinformationen fehlen. Führen Sie Ihre Due-Diligence durch und bitten Sie um eine Demo oder eine Testversion, bevor Sie eine Entscheidung treffen.
The Good and The Bad
What I Liked
- Automatisierte Fehlerklassifikation: Die Art und Weise, wie Cipherra Fehler in Grundursachen kategorisiert, spart Stunden manueller Debugging-Arbeit und ist damit eine echte Zeitersparnis für ML-Teams.
- Redundanz eingebaut: Mehrere unabhängige Tests helfen, instabile Auswertungsprobleme zu mildern, wodurch die Ergebnisse zuverlässiger werden.
- Eigenes Modell mitbringen: Die Kompatibilität mit jedem HTTP-basierten Modell-Endpunkt bedeutet Flexibilität – egal, ob Sie OpenAI, selbst gehostete oder benutzerdefinierte Modelle verwenden.
- Diagnoseberichte: Anstatt nur Bewertungen zu liefern, ermöglichen umsetzbare Einblicke mit Schweregrad- und Behebbarkeitsrankings eine effektive Priorisierung Ihrer Fehlerbehebungen.
- Skalierung und Automatisierung: Die API und das Dashboard ermöglichen es, Evaluationsläufe in Ihre CI/CD-Pipelines zu integrieren, und reduzieren dabei manuellen Aufwand.
Was könnte besser sein
- Begrenzte öffentliche Informationen: Das Fehlen detaillierter Dokumentationen, Funktionslisten und Preisangaben erschwert es, zu beurteilen, ob eine Einführung sinnvoll ist.
- Keine Nutzerbewertungen oder Erfahrungsberichte: Ohne reales Benutzerfeedback ist unklar, wie gut das Tool in vielfältigen realen Anwendungsfällen funktioniert.
- Potenzielle Komplexität: Die Einrichtung wirkt unkompliziert, doch ohne geführte Einarbeitung oder detaillierte Dokumentation könnten neue Nutzer Schwierigkeiten haben, schnell den vollen Nutzen zu ziehen.
- Funktionslücken: Wichtige Funktionen wie die Integration von Versionskontrolle, Mehrbenutzer-Zusammenarbeit oder fortgeschrittene Analytik wurden nicht erwähnt, was die Nutzbarkeit für größere Teams einschränken könnte.
- Transparente Preisgestaltung: Wenn die Kosten nicht im Voraus bekannt sind, könnte dies Nutzer abschrecken, die ihr Budget sorgfältig planen oder Alternativen vergleichen müssen.
Für wen ist Cipherra eigentlich gedacht?
Basierend auf dem, was ich beobachten kann, scheint Cipherra ideal für ML-Ingenieure und -Teams zu sein, die Modelle aktiv einsetzen und eine skalierbare, automatisierte Möglichkeit benötigen, ihre Leistung nach dem Training zu bewerten. Wenn Sie mit großen Sprachmodellen, Feinabstimmung oder Checkpoint-Iterationen experimentieren, könnte dieses Tool Ihren Diagnoseprozess optimieren.
Genau genommen ist es besonders nützlich, wenn:
- Sie verwalten mehrere Modelle oder Checkpoints und wünschen eine konsistente Evaluierung ohne manuellen Scriptaufwand.
- Sie legen Wert auf detaillierte Diagnostik statt einfacher Scores – möchten verstehen, warum ein Modell scheitert oder sich verschlechtert.
- Sie arbeiten in einer CI/CD-Umgebung und benötigen Automatisierung, Redundanz und eine schnelle Bearbeitungszeit.
- Sie sind damit vertraut, eigene Modelle über API-Endpunkte bereitzustellen und Evaluierungsergebnisse in Ihren Workflow zu integrieren.
Zum Beispiel, wenn Sie ein Forschungsingenieur/in sind, der verschiedene RL-Checkpoints testet, oder ein Produktingenieur/in, der Modelle für den Echtzeiteinsatz bereitstellt, könnte Cipherra helfen, Probleme frühzeitig zu identifizieren und Korrekturen effizient zu priorisieren. Es eignet sich weniger für nicht-technische Stakeholder oder Teams, die nach fertigen Dashboards mit vorgefertigten Integrationen suchen.
Wer woanders hinschauen sollte
Wenn Sie ein kleines Start-up oder Solo-Entwickler sind, der nur schnelle, grobe Leistungskennzahlen benötigt, könnte dies übertrieben sein. Das Fehlen transparenter Preisgestaltung, Einweisungshinweise und Nutzer-Feedback deutet darauf hin, dass es eher für größere Teams mit dedizierten MLOps-Ressourcen geeignet sein könnte.
Ebenso, wenn Ihr Workflow stark auf vorhandene Evaluierungs-Frameworks wie lm-eval oder benutzerdefinierte Skripte setzt und Sie keine Automatisierung oder Skalierung anstreben, könnte traditionelles Scripting dennoch Ihre beste Option sein. Cipherras Stärken liegen in Automatisierung, Diagnostik und der Verwaltung von Komplexität in großem Maßstab, was für einfachere Anwendungsfälle möglicherweise unnötig ist.
Und wenn Sie sich nicht mit API-Integrationen oder dem Einsatz eigener Modelle wohlfühlen, oder wenn Sie eine ausgereiftere Benutzeroberfläche mit vorgefertigten Integrationen benötigen (z. B. mit ML-Plattformen oder Tools zur Datenverwaltung), erfüllt diese Plattform möglicherweise nicht Ihre Anforderungen.
Zusammenfassend lässt sich sagen, dass dies kein All-in-One-Ansatz für jedermann ist. Es richtet sich an ML-Teams mit komplexen Evaluationsabläufen, die Automatisierung und tiefe Diagnostik wünschen, statt an diejenigen, die schnelle, vereinfachte Einsichten oder budgetfreundliche Lösungen suchen.
Wie Cipherra im Vergleich zu Alternativen abschneidet
Weights & Biases (W&B)
- What it does differently: W&B bietet umfassende Experimentverfolgung, Modellversionierung und Visualisierungstools, die speziell für ML-Teams entwickelt wurden. Es geht eher um das Management des gesamten ML-Lebenszyklus als um fokussierte Modellbewertung im großen Maßstab.
- Pricing: Beginnt kostenlos mit Basisfunktionen; kostenpflichtige Pläne beginnen bei ca. 49 USD/Monat für zusätzlichen Speicher und Team-Funktionen. Es ist erschwinglicher, aber weniger spezialisiert auf Auswertungen nach dem Training.
- Choose this if... Sie benötigen eine All-in-One-Plattform zur Verwaltung von ML-Experimenten und wünschen eine nahtlose Integration mit Ihrem Code und Ihren Datensätzen.
- Stick with Cipherra if... Sie sich darauf konzentrieren, große Evaluations-Suiten über Modell-Checkpoints hinweg auszuführen und detaillierte Diagnostikberichte benötigen, nicht nur Experimentverfolgung.
OpenAI's Tools zur Modellauswertung
- What it does differently: Diese integrierten Evaluierungs-Suiten, die innerhalb des OpenAI-API-Ökosystems verwendet werden, sind in erster Linie dafür konzipiert, GPT-Modelle während der Entwicklung zu bewerten, mit begrenzter Anpassungsmöglichkeit.
- Pricing: In der Regel in der API-Nutzung enthalten, daher hängen die Kosten von Ihrem API-Plan ab; keine dedizierte Evaluierungsplattformgebühr.
- Choose this if... Ihre Arbeit ist stark in OpenAI-Modelle integriert und Sie bevorzugen schnelle, standardisierte Auswertungen.
- Bleiben Sie bei Cipherra, wenn... Sie Flexibilität benötigen, jedes Modell skalierbar zu evaluieren, mit detaillierten Diagnosen jenseits der Standard-API-Tools.
Hugging Face's Modell-Evaluierungspipelines
- Worin es sich unterscheidet: Hugging Face bietet einfach zu bedienende Pipelines zur Evaluierung von Modellen in verschiedenen Aufgaben, mit Community-Modellen und Datensätzen. Es geht eher um schnelle Bewertungen als um groß angelegte, Post-Training-Diagnostik.
- Preisgestaltung: Überwiegend kostenlos, Open-Source; Cloud-Optionen können Kosten verursachen, sind aber in der Regel zugänglich.
- Wählen Sie dies, wenn... Sie ein Open-Source-Framework zur flexiblen Evaluierung mit umfangreicher Community-Unterstützung für verschiedene NLP-Aufgaben suchen.
- Bleiben Sie bei Cipherra, wenn... Sie nicht an GCP gebunden sind und ein flexibleres, modellagnostisches Auswertungswerkzeug benötigen, das speziell auf RL-Post-Training-Szenarien zugeschnitten ist.
Googles Model Evaluation Suite (z. B. Vertex AI)
- Worin es sich unterscheidet: Bietet integrierte Modellbewertung innerhalb von Google Cloud, mit Fokus auf Bereitstellung, Überwachung und Diagnostik in großem Maßstab für den Unternehmenseinsatz.
- Preisgestaltung: Nach-Nutzung abgerechnet basierend auf Rechenleistung, Speicher und API-Aufrufen; kann für kleine Teams kostspielig sein.
- Wählen Sie dies, wenn... Sie bereits in GCP investiert sind und robuste, integrierte Evaluierungs- und Überwachungswerkzeuge in großem Maßstab benötigen.
- Bleiben Sie bei Cipherra, wenn... Sie nicht an GCP gebunden sind und ein flexibleres, modellagnostisches Auswertungswerkzeug benötigen, das speziell auf RL-Post-Training-Szenarien zugeschnitten ist.
Fazit: Sollten Sie Cipherra ausprobieren?
Offen gesagt würde ich Cipherra derzeit mit etwa 5 von 10 bewerten. Das Hauptproblem ist der Mangel an öffentlich verfügbaren, verifizierten Informationen – daher ist es schwierig zu sagen, wie gut es tatsächlich funktioniert oder ob es die Investition wert ist. Wenn Sie als ML-Ingenieur stark an RL-Post-Training arbeiten und ein Tool suchen, das Evaluations-Suiten im großen Maßstab mit detaillierter Diagnostik ausführen kann, könnte es sich lohnen, es zu erkunden, sobald sie ihre Angebote klären.
Wenn Sie jedoch nur eine schnelle, zuverlässige Evaluierung oder Experimenten-Verwaltung benötigen, gibt es etabliertere Optionen wie Weights & Biases oder Hugging Face, die gut unterstützt und weit verbreitet vertrauenswürdig sind. Cipherra wirkt vielversprechend, ist aber zu diesem Zeitpunkt noch recht undurchsichtig.
Mein Rat? Probieren Sie die kostenlose Stufe aus, falls es eine gibt – wenn sie Ihnen das bietet, was Sie benötigen, großartig. Wenn nicht, oder wenn Sie jetzt bewährte Tools benötigen, bleiben Sie bei den Alternativen. Persönlich würde ich nicht empfehlen, stark in Cipherra zu investieren, bevor weiteres Nutzer-Feedback und offizielle Details veröffentlicht werden.
Kurz gesagt: Wenn Sie neugierig darauf sind, eine potenziell leistungsstarke Evaluierungsplattform zu testen und mit begrenzten Informationen zurechtkommen, geben Sie ihr eine Chance. Wenn Sie jetzt stabile, bewährte Tools benötigen, ist Ihr Geld besser woanders investiert.
Häufig gestellte Fragen zu Cipherra
- Ist Cipherra das Geld wert? Es ist schwer zu sagen, ohne verifizierte Preisangaben oder Nutzerfeedback. Es könnte sich lohnen, wenn es detaillierte Diagnostik im großen Maßstab liefert, aber derzeit sind die Informationen spärlich.
- Gibt es eine kostenlose Version? Es gibt weder eine bestätigte kostenlose Stufe noch eine öffentliche Testversion. Die Details erfahren Sie beim Anbieter.
- Wie schneidet es sich im Vergleich zu Weights & Biases? W&B bietet eine ausgereiftere Verfolgung von Experimenten und Visualisierung, während Cipherra behauptet, sich auf Diagnostik bei großangelegten Evaluationen zu konzentrieren – Details sind jedoch begrenzt.
- Welche Modelle unterstützt es? Offizielle Informationen geben dazu nichts Konkretes an, aber es wird behauptet, jedes Modell unterstützen zu können — vorausgesetzt, es ist für ML-Ingenieure konzipiert, die mit unterschiedlichen Architekturen arbeiten.
- Kann ich eine Rückerstattung erhalten? Rückerstattungsrichtlinien sind nicht öffentlich detailliert aufgeführt; wahrscheinlich hängen sie von den Bedingungen des Anbieters ab.
- Ist es auch für Nicht-RL-Modelle geeignet? Wahrscheinlich, aber seine Stärke liegt offenbar in der RL-Evaluierung nach dem Training. Bestätigen Sie dies beim Anbieter für konkrete Anwendungsfälle.
