Was ist Hyperterse?
Ehrlich gesagt war ich zunächst etwas skeptisch, als ich von Hyperterse hörte. Die Idee, KI-Agenten direkt mit Produktionsdatenbanken zu verbinden, klingt theoretisch nützlich, aber in der Praxis habe ich viele Tools gesehen, die eine vereinfachte Datenzugänglichkeit versprechen, am Ende aber zusätzliche Komplexität oder Sicherheitsprobleme verursachen. Also war ich neugierig: Erfüllt Hyperterse tatsächlich sein Versprechen?
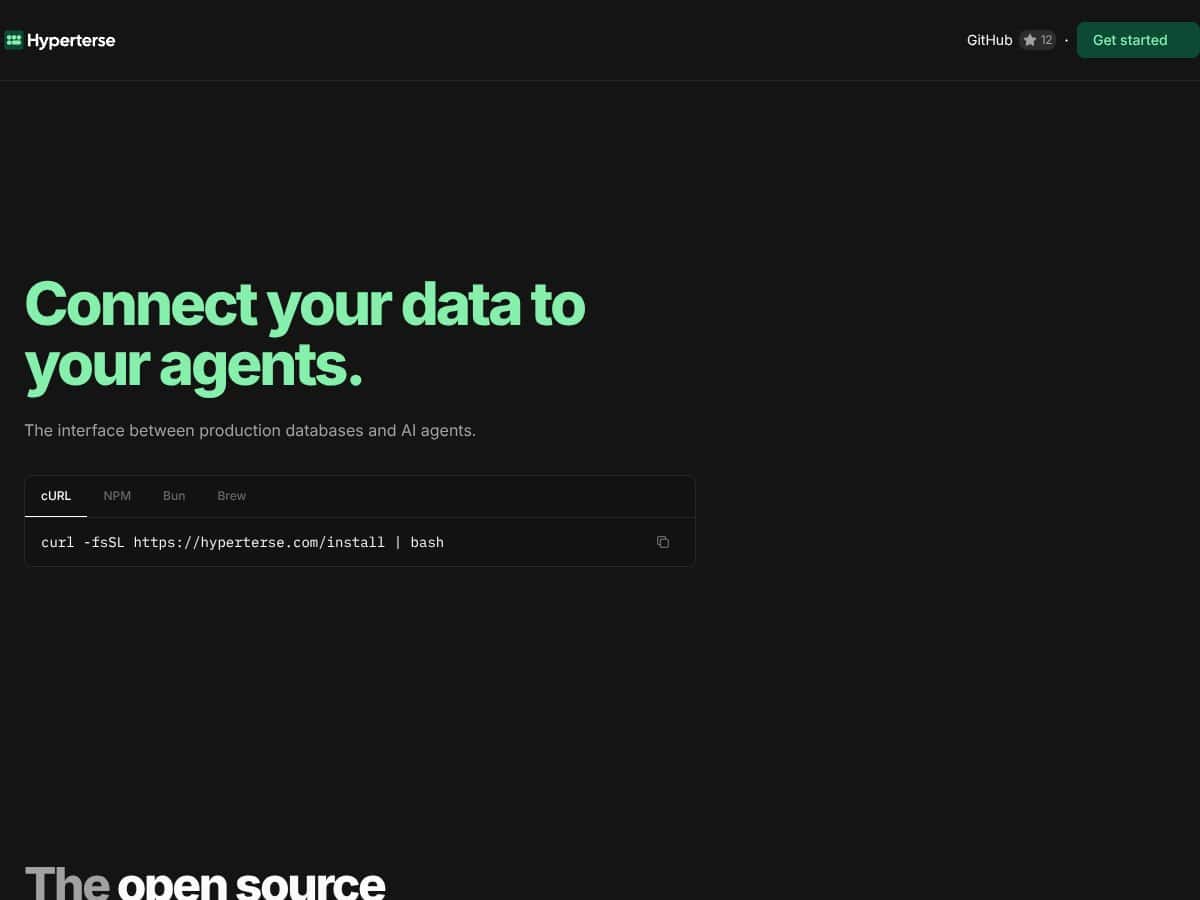
Einfach gesagt ist Hyperterse ein leistungsstarker Laufzeit-Server, der als Brücke zwischen Ihren Produktionsdatenbanken—wie PostgreSQL, MySQL oder Redis—und KI-Systemen oder Anwendungen fungiert. Die Kernidee besteht darin, Datenbankabfragen einmal in einer einfachen Konfigurationsdatei zu definieren und dann automatisch API-Endpunkte, Dokumentationen und Werkzeuge zu generieren, die KI-Agenten aufrufen können, ohne rohes SQL oder sensible Schemata offenzulegen. Es soll den unordentlichen, fehleranfälligen Boilerplate-Code beseitigen und den Datenzugriff für KI-Integrationen sicherer und vorhersehbarer machen.
Das Problem, das es adressiert, ist ziemlich klar: Viele Teams möchten, dass KI mit Live-Geschäftsdaten interagiert, werden aber durch Sicherheitsbedenken, die Komplexität beim Aufbau von APIs und das Risiko halluzinierter oder bösartiger Abfragen gehindert. Hyperterse zielt darauf ab, eine strukturierte, sichere Methode bereitzustellen, damit KI-Agenten auf Daten zugreifen können, ohne die typischen Fallstricke.
Was die Macher dahinter betrifft: Ich konnte kaum etwas über das Team oder das Unternehmen herausfinden — nur, dass es Anfang 2026 kürzlich auf Product Hunt gestartet ist. Das bedeutet, es ist noch ziemlich frisch, und ich vermute, dass es noch einige Stolpersteine ausräumen muss. Mein erster Eindruck war, dass es so funktioniert, wie es beworben wird — ein Infrastruktur-Tool, das den Datenzugriff für KI vereinfacht — aber mit einigen Vorbehalten.
Wichtig ist, die Erwartungen richtig zu setzen: Hyperterse ist KEIN vollwertiges ORM oder ein visuelles Dashboard. Es scheint derzeit weder eine Benutzeroberfläche noch integrierte Berechtigungssteuerungen zu haben. Es handelt sich primär um eine Kommandozeilen- oder konfigurationsbasierte Engine, die APIs und Dokumentationen basierend auf Ihren Eingaben erzeugt. Wenn Sie ein benutzerfreundliches Dashboard oder eine Plug-and-Play-Plattform erwarten, werden Sie enttäuscht sein. Es ist eher ein Entwickler-Tool, das sich in Ihre bestehende Architektur einfügen will, statt sie vollständig zu ersetzen.
Hyperterse-Preisgestaltung: Lohnt es sich?
| Plan | Preis | Was Sie bekommen | Meine Einschätzung |
|---|---|---|---|
| Kostenloser Tarif | Unbekannt | Begrenzter oder nicht spezifizierter Zugriff; Details nicht eindeutig angegeben | Ehrlich gesagt macht das Fehlen klarer Informationen es schwer zu beurteilen, ob der kostenlose Tarif nützlich ist oder nur ein Teaser. Wenn Sie testen oder prototypisieren, sollten Sie tiefer gehen oder sich für Klarstellung an den Anbieter wenden, bevor Sie Zeit investieren. |
| Pro-/Vollständige Pläne | Nicht öffentlich gelistet | Merkmale umfassen vermutlich vollen API-Zugang, höheren Durchsatz und möglicherweise Unternehmensfunktionen | Was den Preis betrifft: Da er nicht offen veröffentlicht wird, fliegen Sie quasi im Blindflug. Erwarten Sie Verhandlungen oder ein Angebot. Wenn Sie ein kleines Team oder Solo-Entwickler sind, stellen Sie sicher, dass die Kosten zu Ihrem Budget und Ihren Bedürfnissen passen. |
Was sie auf der Verkaufsseite nicht sagen, ist, ob Nutzungsbeschränkungen, Ratenbegrenzungen oder Funktionsgrenzen auftreten könnten. Vorabwarnung: Wenn Sie planen, viele Abfragen auszuführen oder zu skalieren, klären Sie diese Details im Voraus. Andernfalls könnten unerwartete Kosten oder Einschränkungen auftreten.
Was die Fairness betrifft, könnte der Vergleich von Hyperterse mit ähnlichen API-Generierungs- oder Datenzugriffs-Tools – vorausgesetzt, die Preisgestaltung ist wettbewerbsfähig – knifflig sein, da es noch keine öffentlichen Informationen gibt. Mein ehrlicher Eindruck ist, dass ohne transparente Preisgestaltung der Wert schwer zu beurteilen ist. Für Early Adopters könnte das ein gutes Angebot bedeuten, wenn der Preis dem Wert entspricht; für andere bleibt es ein gewisses Wagnis.
Wer sollte jetzt investieren? Wahrscheinlich Teams, die bereits eine klare Vorstellung von ihren Datenbanklasten haben und einen schnellen, sicheren Weg benötigen, Daten für KI-Agenten bereitzustellen. Aber wenn Sie budgetsensibel sind oder konkrete ROI-Zahlen sehen möchten, warten Sie besser ab, bis mehr Informationen verfügbar sind.
Das Gute und Das Schlechte
Was mir gefallen hat
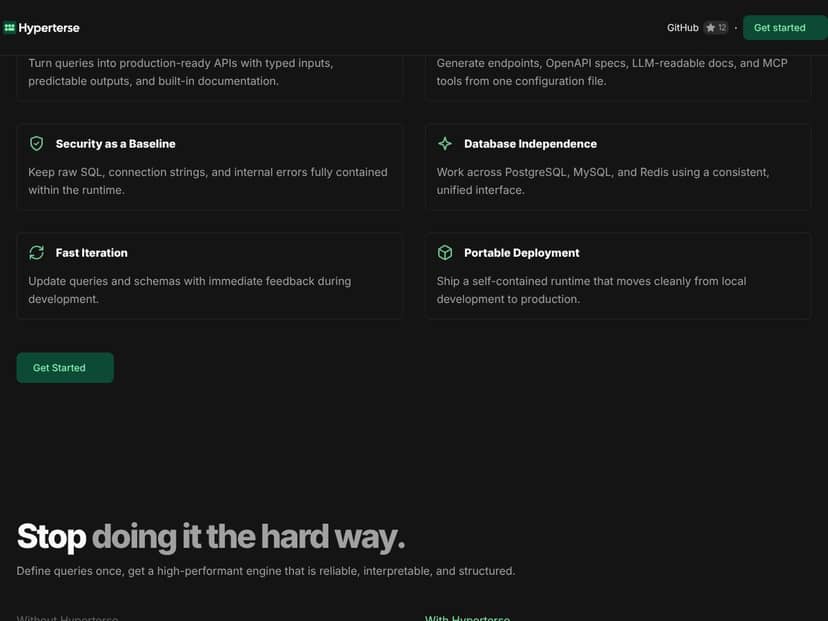
- Deklarative Daten-Schnittstellen: Abfragen einmal in einer Konfigurationsdatei festzulegen, spart enorm Zeit im Vergleich zur manuellen API-Programmierung oder ORM-Einrichtung. Es fühlt sich wie eine kluge Einschränkung an, die Bugs und Inkonsistenzen verhindert.
- Automatische Dokumentation: Die automatisch generierten OpenAPI-Spezifikationen und für LLMs lesbare Dokumentationen sind eine echte Erleichterung. Sie erleichtern das Onboarding neuer Entwickler oder KI-Agenten erheblich, zumal man keine Dokumentation mehr manuell schreiben oder aktualisieren muss.
- Security-by-Design: Raw SQL und Zugangsdaten innerhalb einer Laufzeitumgebung zu halten reduziert die Angriffsfläche – ein großer Pluspunkt für Produktionsbereitstellungen.
- Cross-Database-Unterstützung: Die Unterstützung von Postgres, MySQL und Redis mit einer konsistenten Schnittstelle bedeutet, dass Sie nicht auf eine einzelne Datenbanktechnologie festgelegt sind. Diese Flexibilität wird oft übersehen, ist aber sehr wertvoll.
Was könnte besser sein
- Begrenztes Nutzer-Feedback und Erfahrungsberichte: Da es neu ist, gibt es keine Fallstudien oder Nutzerbewertungen über die ersten Eindrücke hinaus. Das erschwert es, die Zuverlässigkeit in der Praxis einzuschätzen.
- Berechtigungen & Zugriffskontrolle: Der Mangel an einer detaillierten Berechtigungs-Ebene könnte für sensible Unternehmensumgebungen zum Ausschlusskriterium werden. Sie müssten möglicherweise Ihre eigene Lösung erstellen oder auf diese Funktion warten.
- Ergebnis-Caching & Leistungsoptimierung: Derzeit trifft jede Abfrage direkt auf die Datenbank, was bei großem Maßstab zu einem Engpass werden könnte. Geplante Caching-Funktionen könnten dies beheben, aber derzeit ist es eine potenzielle Sorge.
- Begrenzte Transparenz bei Preisgestaltung und Nutzungslimits: Ohne klare Pläne oder Vorgaben ist es schwierig, langfristige Kosten zu beurteilen oder festzustellen, ob es sich für Systeme mit hohem Traffic eignet.
- Lernkurve & Setup-Komplexität: Während der Konfigurationsansatz den Datenzugriff vereinfacht, könnte das Verständnis des Model Context Protocol (MCP) und die korrekte Systemkonfiguration insbesondere für Neueinsteiger herausfordernd sein.
Für wen ist Hyperterse eigentlich gedacht?
Wenn Sie ein Dateningenieur, KI-Entwickler oder ein kleines Team sind, das KI-gestützte Tools entwickelt, die zuverlässigen, sicheren und strukturierten Zugriff auf Produktionsdaten benötigen, könnte Hyperterse ein echter Game-Changer sein. Der ideale Nutzer ist jemand, der den Aufwand vermeiden möchte, API-Endpunkte manuell zu erstellen, Boilerplate-Validierung zu schreiben oder rohes SQL offenzulegen – insbesondere, wenn mehrere Datenbanktypen verwaltet werden.
Wenn Sie beispielsweise einen KI-Assistenten entwickeln, der sicher auf Ihre Kundendatenbank zugreifen muss, erleichtert der deklarative Ansatz von Hyperterse und die automatisch generierte Dokumentation die sichere Integration von KI-Agenten erheblich.
In ähnlicher Weise, wenn Sie Multi-Agenten-Systeme implementieren, die schnellen, zuverlässigen Zugriff auf Daten benötigen, ohne SQL-Injektionen oder Datenlecks zu riskieren, ist dieses Tool eine Überlegung wert.
Wenn Sie jedoch ein Startup oder ein Unternehmen sind, das detaillierte Berechtigungen, Caching oder ein komplexes Benutzermanagement benötigt, könnte Hyperterse noch zu roh oder begrenzt sein. Es eignet sich am besten für Teams, die sich mit der Systemkonfiguration auskennen und bereit sind, auf zukünftige Funktionen wie Caching und Verbesserungen der Berechtigungen zu warten.
Wen es sich lohnt, nach Alternativen zu suchen
Das ist nicht die richtige Lösung, wenn Sie robuste Zugriffskontrollen, Benutzerverwaltung oder detaillierte Berechtigungen direkt benötigen. Falls Ihr Anwendungsfall komplexe Mehrbenutzerumgebungen mit strengen Compliance-Anforderungen umfasst, könnte der aktuelle Funktionsumfang von Hyperterse unzureichend und potenziell riskant sein, ohne zusätzliche Sicherheitsebenen.
In ähnlicher Weise, wenn Ihr Projekt umfangreiches Caching, hohe Parallelität oder detaillierte Protokollierung erfordert, warten Sie, bis diese Funktionen veröffentlicht werden, oder ziehen Sie alternative Lösungen wie traditionelle API-Gateways in Verbindung mit ORM-Schichten oder verwalteten Daten-API-Diensten in Betracht.
Schließlich, wenn Sie sich nicht wohl dabei fühlen, ein neues System zu konfigurieren, ein neues Protokoll (MCP) zu erlernen oder die Umgebung selbst einzurichten, könnte dies eine steile Lernkurve bedeuten. Es ist besser geeignet für technisch versierte Teams, die Probleme lösen und sich an den Produktfortschritt anpassen können.
Wie sich Hyperterse im Vergleich zu Alternativen schlägt
PostgreSQL mit eigener API-Schicht
- Viele Teams bauen eigene API-Ebenen über PostgreSQL mithilfe von Frameworks wie Express.js oder FastAPI und schreiben individuellen Code für jeden Endpunkt. Dieser Ansatz bietet maximale Flexibilität, erfordert jedoch erheblichen Boilerplate- und Wartungsaufwand. - Die Preisgestaltung deckt oft nur die Kosten für Hosting und Entwicklerzeit ab – keine zusätzlichen Tool-Kosten. - Wählen Sie dies, wenn Sie hochgradig angepasste Endpunkte oder komplexe Geschäftslogik benötigen, die sich nicht leicht abstrahieren lässt. - Bleiben Sie bei Hyperterse, wenn Sie schnellen, sicheren und standardisierten Datenzugriff wünschen, ohne Boilerplate-Code schreiben zu müssen – insbesondere, wenn Ihre Datenanforderungen einfach sind.Hasura
- Hasura erzeugt GraphQL-APIs automatisch direkt aus Ihrer Datenbank und nutzt die Flexibilität von GraphQL für Echtzeit- und komplexe Abfragen. - Die Preisgestaltung reicht von kostenlos für kleine Projekte bis zu Enterprise-Plänen; grundsätzlich steigt der Preis, wenn Sie skalieren. - Wählen Sie dies, wenn Sie GraphQL bevorzugen und Echtzeitfunktionen direkt von Haus aus benötigen. - Bleiben Sie bei Hyperterse, wenn Sie REST-APIs, SQL-Sicherheit und KI-Integration priorisieren – insbesondere für Produktionsumgebungen.Supabase
- Eine Open-Source-Alternative zu Firebase, die PostgreSQL-Datenbanken mit automatisch generierten APIs, Authentifizierung und Speicher bietet. - Die Preisgestaltung umfasst kostenlose Stufen mit großzügigen Limits; bezahlte Pläne skalieren basierend auf der Nutzung. - Wählen Sie dies, wenn Sie nach einem All-in-One-Backend mit schneller Einrichtung und Echtzeitfunktionen suchen. - Bleiben Sie bei Hyperterse, wenn Ihr Fokus auf sicherem KI-fähigem Datenzugriff, typisierten Endpunkten und der Vermeidung von Vendor-Lock-in liegt.Direktes SQL mit ORM (z. B. Prisma, SQLAlchemy)
- Entwickler schreiben rohes SQL oder verwenden ORM-Tools, um direkt mit Datenbanken zu interagieren, oft eigene API- und Validierungsschichten aufbauen. - Die Kosten bestehen hauptsächlich aus der Arbeitszeit der Entwickler; Tools wie Prisma bieten kostenlose Tarife oder Open-Source-Optionen. - Wählen Sie diese Option, wenn Sie maximale Kontrolle benötigen und damit einverstanden sind, Sicherheit und Datenvalidierung selbst zu verwalten. - Bleiben Sie bei Hyperterse, wenn Sie den Datenzugriff vereinfachen, Sicherheit gewährleisten und das Offenlegen von rohem SQL vermeiden möchten – bei gleichzeitig guter Leistung.Fazit: Sollten Sie Hyperterse ausprobieren?
Insgesamt würde ich Hyperterse mit etwa 7 von 10 bewerten. Es ist eine solide Wahl, wenn Sie nach einer leichten, sicheren Lösung suchen, um KI-Agenten mit Ihren Produktionsdatenbanken zu verbinden, ohne den Aufwand traditioneller APIs oder Boilerplate-Code. Die Leistung ist beeindruckend, und die automatische Dokumentation für LLMs ist eine echte Zeitersparnis.
Es ist perfekt für kleine bis mittelgroße Teams, die eine schnelle Einrichtung und zuverlässigen Datenzugang wünschen—insbesondere, wenn Sicherheit und KI-Integration Priorität haben. Allerdings ist es noch neu und fehlen einige Funktionen wie Caching und eine detaillierte Berechtigungsverwaltung, falls Ihr Projekt diese Funktionen jetzt benötigt, sollten Sie eventuell noch warten.
Probieren Sie definitiv die kostenlose Stufe aus, falls verfügbar, da sie Ihnen ein Gefühl für die Geschwindigkeit vermittelt und wie gut sie in Ihren Workflow passt. Ein Upgrade macht Sinn, wenn Sie auf Limits stoßen oder Funktionen wie Caching später benötigen. Persönlich würde ich es empfehlen, wenn Ihr Ziel darin besteht, KI-Interaktionen sicher zu optimieren – es lohnt sich, es auszuprobieren.
Wenn Sie komplexe benutzerdefinierte Logik oder ein ausgereiftes Berechtigungsmanagement benötigen, sollten Sie vorerst woanders schauen. Aber für unkomplizierten, sicheren KI-Datenzugriff ist Hyperterse ein vielversprechendes Werkzeug.
Häufige Fragen zu Hyperterse
- Ist Hyperterse das Geld wert? Es hängt von Ihren Bedürfnissen ab. Wenn Sie Sicherheit, Geschwindigkeit und einfache KI-Integration schätzen, lohnt es sich, es zu prüfen. Bei komplexen Berechtigungen oder Caching müssen Sie eventuell warten.
- Gibt es eine kostenlose Version? Das Produkt wurde kürzlich eingeführt, und Details zu kostenlosen Tarifen sind noch nicht klar. Erwarten Sie zunächst eingeschränkten Testzugang.
- Wie schneidet es im Vergleich zu Hasura ab? Hyperterse legt Wert auf SQL-Sicherheit und KI-Bereitschaft, während Hasura GraphQL mit Echtzeit-Funktionen bietet. Wählen Sie basierend auf Ihrem bevorzugten API-Stil.
- Gibt es eine Rückerstattung? Rückerstattungsrichtlinien sind noch nicht öffentlich detailliert angegeben; prüfen Sie den offiziellen Support oder die Nutzungsbedingungen, sobald sie verfügbar sind.
- Unterstützt es andere Datenbanken? Ja, es unterstützt PostgreSQL, MySQL und Redis – und ist damit vielseitig für verschiedene Tech-Stacks.
- Ist es einfach einzurichten? Ja, besonders wenn Sie mit Konfigurationsdateien vertraut sind – kein komplexer Boilerplate erforderlich.
- Wird es hohen Durchsatz bewältigen? Erste Tests sind vielversprechend mit geringer Latenz, aber umfangreichere Benchmarking-Untersuchungen stehen noch aus.