Was ist Next.js Evals?
Ehrlich gesagt, als ich zum ersten Mal von Next.js Evals hörte, fragte ich mich, was genau dahintersteckt. Ich habe schon eine Menge KI-Benchmarking-Tools gesehen, aber dieses behauptet, zu bewerten, wie gut KI-Agenten bei Next.js-spezifischen Aufgaben wie Codegenerierung und Migration abschneiden. Das weckte sofort meine Neugier: Sind wir wirklich an einem Punkt, an dem wir die Fähigkeit der KI zuverlässig messen können, ein so beliebtes Framework wie Next.js zu bewältigen? Oder ist es nur eine weitere Statistik, die gut klingt, aber nicht die ganze Geschichte erzählt?
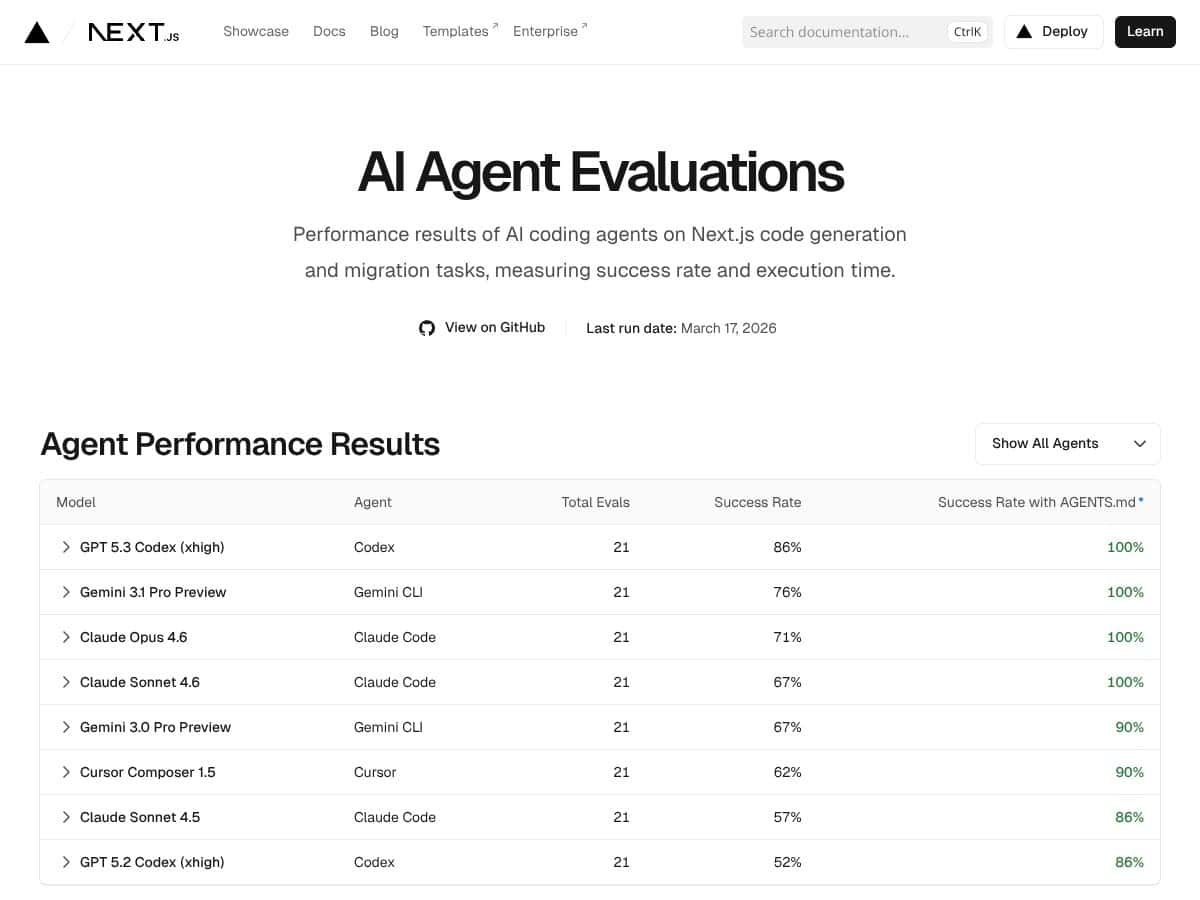
Was Next.js Evals tatsächlich tut, ist auf der Oberfläche gesehen ziemlich geradlinig: Es führt verschiedene KI-Modelle—wie GPT, Claude, Gemini—gegen eine Reihe vordefinierter Next.js-Codierungsaufgaben. Es misst Erfolgsquoten und wie lange jedes KI-Modell benötigt, um diese Aufgaben zu erledigen. Die Idee dahinter ist, Entwicklern einige Daten zu liefern, die ihnen helfen, zu entscheiden, welche KI-Tools es wert sind, beim Arbeiten mit Next.js-Code vertraut eingesetzt zu werden. Es ist also im Wesentlichen ein Benchmark, aber fokussiert auf Next.js-bezogene Code-Herausforderungen statt auf allgemeine KI-Leistung.
Die Sache ist: Vercel – das Unternehmen hinter Next.js – steht hinter diesem Projekt. Das verleiht ihm eine gewisse Glaubwürdigkeit; sie sind die Erfinder von Next.js selbst, daher macht es Sinn, dass sie sehen möchten, wie KI ihr Ökosystem unterstützen kann. Aber ich war etwas skeptisch, ob dieses Tool mehr ist als eine Ansammlung statischer Ergebnisse. Schließlich ist es eine Benchmarking-Seite, kein interaktives Umfeld oder ein Toolkit für echte Migrationen oder Code-Reparaturen.
Mein erster Eindruck? Es entspricht dem, was es verspricht — zumindest in Bezug auf das, was es zeigt: Leistungsdaten zu verschiedenen KI-Modellen bei bestimmten Next.js-Aufgaben. Erwarten Sie jedoch keine ausgefallenen Funktionen oder Möglichkeiten, eigene benutzerdefinierte Tests direkt auf der Website durchzuführen. Es ist eher eine Rangliste als ein Entwicklungstool. Außerdem möchte ich von vornherein klarstellen, dass es nicht für eine allgemeine KI-Bewertung entwickelt wurde. Wenn Sie nach einer umfassenden LLM-Bestenliste suchen oder etwas, um Modelle in mehreren Domänen zu vergleichen, ist dies nicht der richtige Ort. Es konzentriert sich eng auf Next.js-Aufgaben.
Next.js Evals Preisgestaltung: Lohnt es sich?
| Tarif | Preis | Was Sie erhalten | Meine Einschätzung |
|---|---|---|---|
| Kostenlose Stufe | Kostenlos | Zugriff auf grundlegende Auswertungsmetriken, aktuelle Benchmark-Ergebnisse und Leistungsdaten von KI-Agenten bei Next.js-Aufgaben. | Ehrlich gesagt ist die kostenlose Stufe wahrscheinlich ausreichend, wenn Sie einfach nur ein Gefühl dafür bekommen möchten, wie gut Ihre KI-Tools bei Next.js-Projekten abschneiden. Die Details sind jedoch spärlich, und es ist unklar, ob es Nutzungsbeschränkungen gibt oder ob die kostenlose Stufe alle Funktionen abdeckt. |
| Bezahlte Tarife | Nicht öffentlich aufgeführt | Möglicherweise detailliertere Berichte, historischer Datenzugang oder benutzerdefinierte Evaluationsoptionen—falls sie existieren. | Was die Preisgestaltung betrifft: Die Website gibt nicht an, was bezahlte Pläne umfassen oder kosten. Wenn Sie ernsthaft daran interessiert sind, diese Benchmarks in Ihren Arbeitsablauf zu integrieren, müssen Sie möglicherweise direkt mit Vercel Kontakt aufnehmen oder auf klarere Informationen warten. Dieses Fehlen an Transparenz könnte für manche ein K.O.-Kriterium darstellen. |
Ist es also zu einem fairen Preis erhältlich? Nun, wenn man bedenkt, dass es Open-Source ist und sich auf eine Nische – eine Next.js-spezifische KI-Evaluierung – konzentriert, ist es schwer zu sagen. Wenn Sie dies mit allgemeinen KI-Bewertungstools wie Hugging Face oder LangChain vergleichen, die oft Gebühren für Enterprise-Funktionen oder Hosting erheben, scheint dies eher eine gemeinschaftsorientierte Benchmark-Ressource zu sein. Aber Vorsicht: Ohne klare Preisgestaltung oder Funktionsübersicht ist es schwer, den Wert zu beurteilen. Wichtiger Hinweis: Wenn Sie robuste, anpassbare Evaluationswerkzeuge oder Integrationsmöglichkeiten benötigen, könnte dies nicht ausreichen, zumal die Plattform anscheinend nicht mehr als statische Benchmarking-Daten bietet.
Das Gute und Das Schlechte
Was mir gefallen hat
- Objektive Benchmarks: Sie liefern konkrete Erfolgsquoten und Ausführungszeiten, was bei der Auswahl von KI-Tools für Next.js-Aufgaben unschätzbar ist. Kein Rätselraten mehr—nur Daten.
- Open-Source-Transparenz: Das GitHub-Repository ermöglicht es jedem, zu überprüfen, beizutragen und genau zu verstehen, wie die Benchmarks durchgeführt werden. Das ist ein großes Plus in meinem Buch.
- Regelmäßige Updates: Der letzte Lauf war im Februar 2026, daher sind die Daten nicht veraltet. Es zeigt ein Engagement, Benchmarks aktuell zu halten, was in diesem Bereich selten ist.
- Abdeckung der führenden Modelle: Zu sehen, wie GPT 5.3 Codex andere mit einer Erfolgsquote von 86–90 % übertrifft, vermittelt ein klares Bild davon, was mit aktueller KI-Technologie bei Next.js-Aufgaben erreichbar ist.
- Dokumentationsauswirkung: Die Erwähnung von AGENTS.md, die Erfolgsraten erhöht, deutet darauf hin, dass gut dokumentierte Agenten besser abschneiden—nützlicher Einblick für Entwickler, die ihre KI-Workflows optimieren.
Was könnte besser sein
- Begrenzter Umfang: Es bewertet ausschließlich Next.js-spezifische Aufgaben. Wenn Sie nach umfassenderem KI-Benchmarking oder frameworkübergreifenden Vergleichen suchen, genügt dies nicht.
- Fehlende Benutzeroberfläche oder interaktive Werkzeuge: Es gibt kein Dashboard, keinen Echtzeit-Runner und keine Möglichkeit, eigene Modelle direkt zu testen. Es handelt sich dabei nur um statische Ergebnisse, was Experimente einschränkt.
- Undurchsichtige Preispläne und Funktionen: Das Fehlen klarer kostenpflichtiger Optionen oder Premium-Funktionen könnte Teams frustrieren, die mehr Kontrolle oder Anpassungsmöglichkeiten wünschen.
- Keine Referenzen oder Fallstudien: Ohne Nutzerberichte lässt sich die reale Auswirkung oder Zuverlässigkeit jenseits der reinen Punktzahlen schwer einschätzen.
- Potenzial für veraltete Benchmarks: Zwar war der jüngste Durchlauf kürzlich, entwickeln sich KI-Modelle rasch weiter. Wenn die Plattform nicht regelmäßig aktualisiert wird, könnten die Benchmarks im Laufe der Zeit an Relevanz verlieren.
Für wen ist Next.js Evals tatsächlich gedacht?
Wenn Sie Entwickler oder ein Team sind, das stark mit Next.js und KI-Codegenerierung arbeitet—insbesondere wenn Sie KI-Agenten in Ihren Workflow integrieren—kann dieses Tool als nützlicher Orientierungspunkt dienen. Stellen Sie es sich wie eine Leistungs-Skala vor, die Ihnen hilft zu entscheiden, welche KI-Modelle zuverlässig Code im Next.js-Ökosystem generieren oder migrieren. Ideal ist es, wenn Sie konkrete Daten statt vager Behauptungen wünschen.
Zum Beispiel, wenn Sie bewerten, ob GPT 5.3 Codex eine Investition für Ihre Next.js-Projekte wert ist, liefern Ihnen diese Benchmarks Erfolgsquoten und Ausführungszeiten, die diese Entscheidung stützen. Es ist besonders hilfreich, wenn Sie Ihre KI-Workflows optimieren oder die Leistung verschiedener Modelle für spezifische Aufgaben wie Code-Migration oder -Generierung vergleichen.
Allerdings ist das nicht geeignet für jemanden, der eine vollständige Entwicklungsumgebung, Tests mit benutzerdefinierten Datensätzen oder Echtzeit-Tuning der KI-Leistung sucht. Es ist eher eine Benchmarking-Referenz als eine interaktive Plattform.
Wen sollten Sie woanders suchen?
Wenn Sie eine umfassende IDE-Erweiterung, eine Live-Testumgebung oder integriertes Modelltraining erwarten, ist dieses Tool nichts für Sie. Es geht ausschließlich um Leistungsmessung, daher, wenn Sie mehr Hands-on-, anpassbare oder Multi-Framework-Bewertungstools benötigen, ziehen Sie Alternativen wie LangChain Evals oder das Leaderboard von Hugging Face in Betracht.
Außerdem, wenn Sie Anfänger sind oder gerade erst mit KI in Next.js arbeiten, kann es unzureichend sein, sich ausschließlich auf statische Benchmarks zu verlassen, um das volle Bild dessen zu erfassen, was möglich ist. Realwelt-Szenarien beinhalten oft Nuancen, die diese Benchmarks nicht abdecken, also rechnen Sie nicht damit, dass dies praktisches Ausprobieren ersetzt.
Schließlich, wenn Transparenz bei Preisen oder detaillierten Funktionspaketen für Ihr Team unverzichtbar ist, beachten Sie, dass der derzeitige Mangel an Informationen zu Überraschungen oder unerfüllten Erwartungen führen könnte.
Wie sich Next.js Evals im Vergleich zu Alternativen schlägt
LangChain Evals
LangChain Evals konzentriert sich stärker darauf, Sprachmodelle im Kontext von Chain-of-Thought-Schlussfolgerungen und mehrstufigen Arbeitsabläufen zu bewerten. Es bietet eine breitere Auswahl an Benchmarks, die nicht speziell auf Next.js ausgerichtet sind, aber nützlich für allgemeine KI-Modellbewertungen. Preislich ist es Open-Source und kostenlos wie Next.js Evals, aber flexibler für vielfältige KI-Aufgaben.
Wählen Sie dies, wenn Sie ein vielseitiges, allgemeines Evaluierungs-Framework benötigen, das komplexe Schlussfolgerungsaufgaben jenseits der Web-Entwicklung bewältigen kann. Bleiben Sie bei Next.js Evals, wenn sich Ihr Hauptfokus darauf richtet, KI-Agenten speziell für Next.js-Code-Generierung und Migration zu benchmarken, da es zielgerichtetere und aktuellere Benchmarks für diese Aufgaben bietet.
OpenAI Evals
OpenAI Evals ist darauf ausgelegt, OpenAI-Modelle speziell zu bewerten, mit Schwerpunkt auf ihren API-basierten Modellen. Es bietet eine Möglichkeit, benutzerdefinierte Benchmarks zu erstellen und sie gegen OpenAI-Modelle laufen zu lassen, aber es geht weniger um standardisierte Benchmarks und mehr um individuelle Bewertungen, die Sie selbst einrichten. Es ist kostenlos, wenn Sie die OpenAI-API verwenden, aber die Kosten können je nach Nutzung ansteigen.
Wählen Sie dies, wenn Sie eine enge Integration mit OpenAI-Modellen benötigen und Ihre eigenen Benchmarks anpassen möchten. Bleiben Sie bei Next.js Evals, wenn Sie fertige, Next.js-spezifische Benchmarks und Leistungsdaten wünschen, insbesondere, wenn Sie nicht ausschließlich mit OpenAI-Modellen arbeiten.
Hugging Face Open LLM Leaderboard
Diese Plattform bietet einen breiten Vergleich verschiedener Sprachmodelle über verschiedene Benchmarks hinweg, darunter auch solche, die mit Programmieraufgaben zusammenhängen. Es geht eher darum, die Gesamtfähigkeiten der Modelle zu vergleichen, als Ihre spezifischen KI-Agenten oder Aufgaben wie Migration oder Codegenerierung in Next.js zu bewerten. Sie ist kostenlos und von der Community getragen.
Wählen Sie dies, wenn Sie die allgemeine Leistungsfähigkeit mehrerer Modelle über verschiedene Aufgaben hinweg vergleichen. Bleiben Sie bei Next.js Evals, wenn Ihr Ziel ist, KI-Agenten speziell in Next.js-Workflows und bei der Codegenerierung zu benchmarken.
SWE-Bench und BigCodeBench
Dies sind spezialisierte Benchmarks, die sich auf Software-Engineering-Codeaufgaben konzentrieren und häufig in der Forschung eingesetzt werden. Sie bewerten Modelle bei Codevervollständigung, Bugfixing und ähnlichen Aufgaben, sind jedoch weniger auf Web-Frameworks wie Next.js zugeschnitten. Sie gelten eher als akademische Werkzeuge mit Open-Source-Zugriff.
Wählen Sie diese, wenn Sie sich für tiefe Forschung im Bereich KI beim Programmieren interessieren oder Modelle bei reinen Code-Aufgaben benchmarken möchten. Next.js Evals ist praktischer, wenn Sie direkte Einblicke in Next.js-spezifische Arbeitsabläufe und Migrationserfolg wünschen.
Fazit: Sollten Sie Next.js Evals ausprobieren?
Insgesamt würde ich sagen, dass Next.js Evals solide 7 von 10 Punkten verdient. Es ist ein Nischenwerkzeug, aber eines, das wirklich nützlich ist, wenn Sie speziell mit Next.js arbeiten und sehen möchten, wie verschiedene KI-Agenten bei Codegenerierung oder Migrationsaufgaben abschneiden. Es ist transparent, Open-Source und wird regelmäßig aktualisiert, was ein großer Vorteil ist.
Wer sollte es ausprobieren? Wenn Sie ein Next.js‑Entwickler sind, der mit KI-unterstütztem Codieren oder Migrationswerkzeugen experimentiert, ist das eine klare Sache. Es liefert Ihnen klare, datenbasierte Einblicke darin, wie gut verschiedene Modelle in Ihren üblichen Arbeitsabläufen abschneiden.
Wen sollten Sie überspringen? Wenn Ihr Fokus nicht auf Next.js oder Webentwicklungs-Frameworks liegt, oder wenn Sie einfach nach allgemeinen KI-Benchmarks suchen, ist dies nicht das richtige Werkzeug. Es ist sehr speziell, also ziehen Sie für eine breitere KI‑Bewertung Alternativen wie Hugging Face Leaderboard oder LangChain Evals in Betracht.
Der kostenlose Tarif ist definitiv einen Versuch wert, da er Open-Source ist und leicht zugänglich ist. Wenn Sie ernsthaftes Benchmarking betreiben und sehen möchten, wie Modelle wie GPT 5.3 Codex in Ihren Next.js‑Projekten abschneiden, kann sich der Zeitaufwand lohnen. Ein Upgrade oder Beitrag zum Open-Source-Repo könnte sich lohnen, wenn Sie maßgeschneiderte Einblicke wünschen oder die Benchmarks verbessern helfen möchten.
Würde ich es persönlich empfehlen? Wenn Sie sich für Next.js‑Entwicklung interessieren und die KI‑Leistung in diesem Bereich im Blick behalten möchten, ja. Es ist nicht perfekt und hat Einschränkungen, aber es ist eine wertvolle Ressource für spezifische Anwendungsfälle. Wenn Sie nach breiteren KI-Fähigkeiten suchen oder gerade erst anfangen, könnten andere Tools besser zu Ihnen passen.
Wenn Sie stark in Next.js investiert sind und die Zuverlässigkeit von KI-Agenten in Ihren Arbeitsabläufen testen möchten, probieren Sie es aus. Wenn Ihre Bedürfnisse allgemeiner sind oder Sie nach Benchmark-Lösungen für mehrere Frameworks suchen, investieren Sie Ihre Zeit und Ihr Geld besser in Alternativen wie Hugging Face oder LangChain.
Häufige Fragen zu Next.js Evals
- Ist Next.js Evals das Geld wert? Es ist kostenlos, daher entstehen keine Kosten. Es lohnt sich, wenn Sie maßgeschneiderte Benchmarks für Next.js-Aufgaben wünschen, aber der Umfang ist begrenzt.
- Gibt es eine kostenlose Version? Ja, es ist Open-Source und kostenlos über GitHub und die Next.js-Website nutzbar.
- Wie vergleicht es sich mit [Konkurrent]? Im Vergleich zu Hugging Face oder OpenAI Evals ist Next.js Evals stärker auf Next.js‑Workflows spezialisiert, während andere breiter gefächert oder anpassbarer sind.
- Gibt es eine Rückerstattung? Nicht anwendbar, da es Open-Source und kostenlos ist.
- Welche Modelle werden unterstützt? Es unterstützt Modelle wie GPT, Gemini CLI, Claude Code und Cursor, wobei aktuelle Benchmarks zeigen, dass GPT 5.3 Codex am besten abschneidet.
- Wie oft werden Benchmarks aktualisiert? Der jüngste Durchlauf war am 18. Februar 2026, und Updates hängen von Beiträgen der Community ab.
- Kann ich Benchmarks beitragen oder anpassen? Ja, es ist Open-Source, und Sie können zum GitHub‑Repository beitragen oder Benchmarks nach Bedarf anpassen.
- Ist es einfach zu verwenden? Es ist für Entwickler konzipiert, die mit KI und Next.js vertraut sind, aber es ist einfach zu handhaben, wenn Sie der Dokumentation folgen.