¿Qué es APIEval-20?
Sinceramente, cuando me topé por primera vez con APIEval-20, estaba bastante escéptico. La idea de un benchmark que evalúa si una IA puede realmente encontrar errores en APIs, solo a partir de un esquema y una única carga útil de muestra, suena interesante, pero también un poco de nicho. He visto muchas herramientas de prueba de API que generan casos de prueba, pero la mayoría se basan en gran medida en la documentación, el código fuente, o al menos algún conocimiento previo de la lógica de la API. Lo que llamó mi atención fue la afirmación de que APIEval-20 tiene como objetivo evaluar a los agentes de IA en un entorno de caja negra, similar a como suelen operar los testers del mundo real cuando cuentan con información limitada.
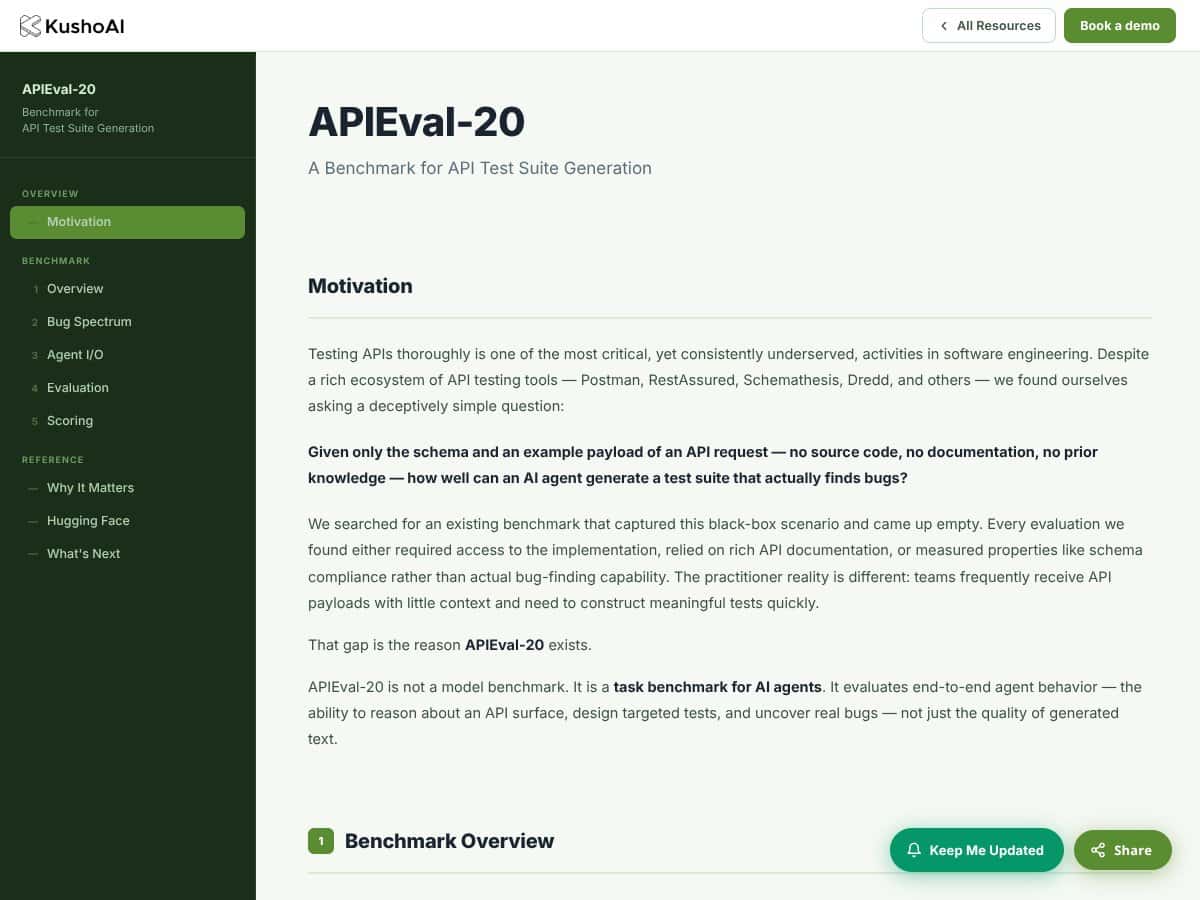
En lenguaje llano, se trata de un conjunto de 20 escenarios de API de diferentes dominios, cada uno con errores intencionados. La tarea de la IA es generar conjuntos de pruebas que descubran estos errores, basándose únicamente en el esquema y en una única carga útil de muestra. Sin código fuente, sin documentación interna — solo los detalles superficiales de la API. El objetivo no es simplemente producir scripts de prueba atractivos; es ver si la IA puede razonar lo suficiente para encontrar problemas reales que un tester humano podría descubrir.
Según lo que pude encontrar, este proyecto está desarrollado por KushoAI, una empresa que parece enfocarse en soluciones de pruebas impulsadas por IA, aunque el equipo exacto detrás de APIEval-20 no se detalla explícitamente. Mi impresión inicial fue que es un esfuerzo serio para ir más allá de la simple generación de pruebas y, de hecho, medir la capacidad de detección de errores de forma realista.
Dicho eso, quiero ser claro sobre lo que no es: no es un conjunto de pruebas completo ni una plataforma de automatización. Es un benchmark, diseñado específicamente para evaluar a los agentes de IA, y no para reemplazar flujos de trabajo de pruebas integrales. Así que no esperes que maneje cosas como pruebas de interfaz de usuario, pruebas exploratorias o integraciones complejas. Está muy enfocado — lo cual no es necesariamente algo negativo, pero vale la pena mantener las expectativas realistas.
Precios de APIEval-20: ¿Vale la pena?
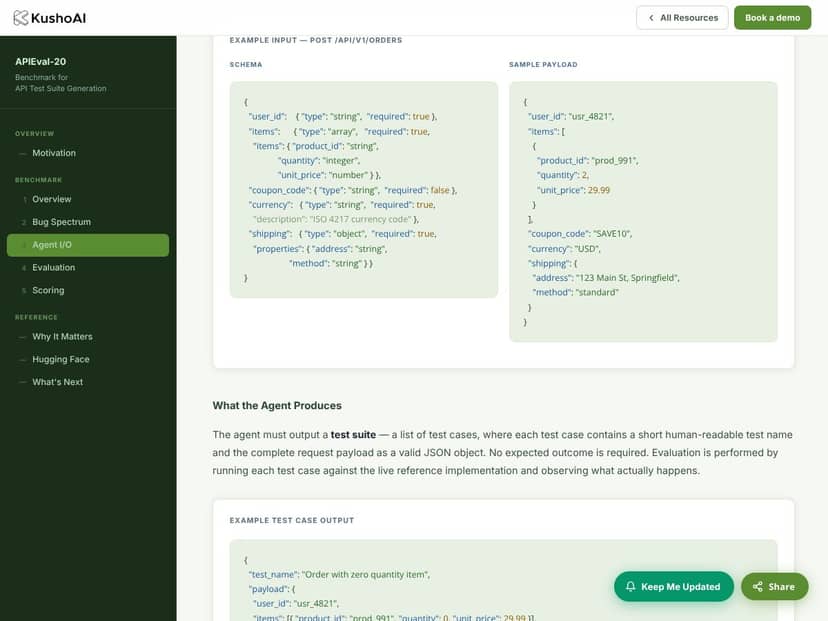
| Plan | Precio | Qué Obtienes | Mi Opinión |
|---|---|---|---|
| Gratis | Gratis | Acceso al conjunto de datos de referencia abierto, se pueden realizar evaluaciones locales, limitado a escenarios clave | Perfecto para experimentación e investigación, especialmente si estás probando modelos de IA o integrándolos en tus propios flujos de trabajo. Sin embargo, tiene un alcance limitado y puede carecer de funciones avanzadas o soporte. |
| Acceso Comercial/Extendido | Los detalles de precios no están disponibles públicamente | Acceso potencial a más escenarios, informes de puntuación detallados o pipelines de evaluación integrados, según las ofertas de KushoAI | Aviso justo: los detalles no están claros. Si estás considerando un plan de pago, ponte en contacto con KushoAI para aclararlo. Es probable que el valor principal esté en entornos empresariales o de investigación que requieren una evaluación comparativa constante. |
Esto es lo que hay que saber sobre los precios: a partir de lo que está disponible públicamente, APIEval-20 es básicamente gratuito de acceder y ejecutar localmente, lo que es una gran ventaja para equipos de investigación y desarrolladores que quieren experimentar sin costos iniciales. Dicho esto, si buscas funciones avanzadas, evaluaciones alojadas o integraciones, podrías necesitar revisar otros productos de pago de KushoAI — pero los detalles son escasos. Lo que no te dicen en la página de ventas es si existen límites de uso, topes de llamadas a la API o restricciones de funciones en la capa gratuita. Mi suposición es que, dado que está abierto y alojado en Hugging Face, el conjunto de datos de referencia principal y los scripts de evaluación son accesibles sin cargos, pero escalar o recibir soporte a nivel empresarial podría implicar costos. Entonces, ¿qué plan tiene sentido? Si eres investigador, un desarrollador que quiere probar las capacidades de detección de errores de tu agente de IA, o un equipo que explora conjuntos de datos de referencia, el acceso gratuito probablemente cubre tus necesidades. Si eres una empresa o una compañía que planea integrarlo en un pipeline CI/CD o pruebas de producto, necesitarás ponerte en contacto directamente con KushoAI y estar preparado para posibles costos. En resumen, los precios parecen razonables dada su naturaleza abierta y orientada a la investigación. Solo ten cuidado con posibles limitaciones ocultas si planeas escalar o depender mucho de ello en entornos de producción. Asegúrate de aclarar con KushoAI qué incluye la capa gratuita y qué costos adicionales podrían estar involucrados.
Lo Bueno y Lo Malo
Lo Que Me Gustó
- Puntuación Objetiva centrada en Errores Reales: A diferencia de muchos benchmarks que se basan en evaluaciones subjetivas o métricas sintéticas, APIEval-20 evalúa si el agente de IA realmente descubre un error plantado, lo que resulta mucho más significativo.
- Evaluación de Caja Negra: La configuración replica numerosos escenarios del mundo real en los que solo dispones de entradas limitadas — esquemas y muestras de cargas útiles — lo que hace que los resultados de la prueba sean más aplicables a los desafíos prácticos de pruebas de API.
- Cobertura Multidominio: Con escenarios que abarcan comercio electrónico, pagos, autenticación y más, ofrece una visión amplia de las capacidades de detección de errores de un agente de IA a través de diferentes estilos y complejidades de API.
- Conjunto de datos abierto y reproducible: Hospedado en Hugging Face, es accesible para investigadores y desarrolladores por igual, fomentando la transparencia y la validación por parte de la comunidad.
- Fomenta el razonamiento de extremo a extremo: El benchmark enfatiza la capacidad del agente para razonar sobre el comportamiento de la API y generar pruebas significativas, no solo producir fragmentos de código plausibles.
- Errores sembrados de complejidad variable: La inclusión de fallos simples a complejos ayuda a evaluar la profundidad de la comprensión de una IA y su capacidad para detectar errores, más allá de problemas superficiales.
Qué podría mejorar
- Conjunto de escenarios limitado: Con solo 20 escenarios, puede no capturar completamente la diversidad de APIs del mundo real, especialmente las de nicho o altamente especializadas. Esto podría limitar su aplicabilidad para algunas industrias.
- Falta de documentación o interfaz de usuario amigable: Como benchmark de investigación, es más un conjunto de datos sin procesar y un script de evaluación que un producto pulido. Para equipos sin experiencia en IA, la configuración podría no ser trivial.
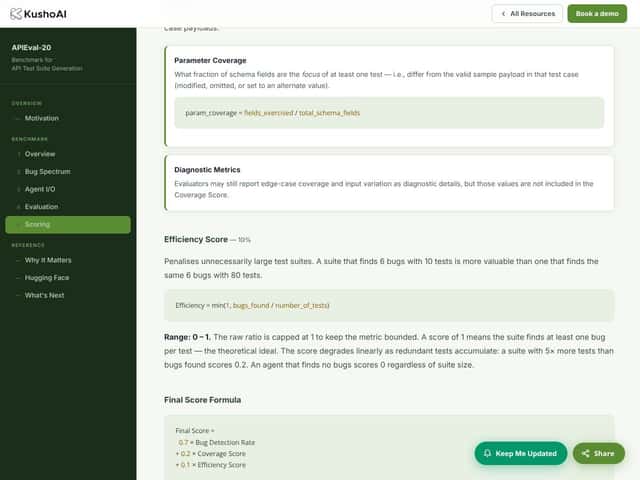
- Sin desglose de puntuación claro o medidas de confianza: Aunque evalúa la detección de errores, los detalles de cómo se maneja la cobertura parcial o los falsos positivos no son transparentes, lo que podría dificultar un análisis comparativo.
- Retroalimentación comunitaria limitada: Como un benchmark nuevo, aún no existe una gran cantidad de reseñas independientes o estudios de caso que demuestren el impacto en el mundo real o las mejores prácticas para implementarlo a gran escala.
- Enfoque en la detección de errores, no en una suite de pruebas completa: Si tu objetivo es una prueba de API integral, que incluya pruebas de carga, escaneos de seguridad o verificaciones de cumplimiento, este benchmark no está diseñado para ese alcance.
¿Para quién es realmente APIEval-20?
Si eres un investigador o desarrollador que trabaja en herramientas de pruebas de API impulsadas por IA, APIEval-20 es un benchmark convincente. Está diseñado específicamente para quienes desean evaluar si sus modelos pueden razonar sobre el comportamiento de las API y descubrir errores reales con una entrada mínima. Por ejemplo, si has desarrollado un modelo de lenguaje grande (LLM) que afirma generar casos de prueba, pero necesitas una forma objetiva de medir su capacidad para encontrar errores, este benchmark ofrece una forma estandarizada de hacerlo.
También es ideal para equipos que exploran la integración de la IA en sus flujos de trabajo de pruebas existentes. Supongamos que tienes un agente de IA que, con solo un esquema de API y una carga útil de muestra, necesita generar pruebas focalizadas para encontrar errores en un entorno real. APIEval-20 puede servir como un paso de validación para cuantificar la mejora a lo largo del tiempo o comparar diferentes modelos.
En la práctica, esto funciona bien para ingenieros de QA, investigadores de IA y equipos de automatización que desean un reto repetible de caja negra que obligue a sus modelos a razonar sobre la lógica de la API en lugar de simplemente generar fragmentos de código plausibles. No está destinado a usuarios casuales ni a quienes buscan pruebas exhaustivas en los dominios de la interfaz de usuario, rendimiento o seguridad; es un punto de referencia específico para la detección de errores.
Quién debería buscar en otro lugar
Si tu objetivo es pruebas generales de API, como automatizar colecciones de Postman, o necesitas verificar flujos de la interfaz de usuario, APIEval-20 probablemente no sea la herramienta adecuada. Está centrado de forma estrecha en la detección de errores a partir de una entrada mínima, así que si buscas una suite de pruebas amplia, pruebas de carga o escaneos de seguridad, existen opciones mejores disponibles — como LoadRunner, OWASP ZAP o las funciones integradas de Postman.
Del mismo modo, si no trabajas en el desarrollo o investigación de modelos de IA y solo quieres una forma directa de probar tus APIs, este benchmark podría parecer demasiado abstracto o complejo. Requiere cierta familiaridad con configuraciones de evaluación de IA y puede que no ofrezca la usabilidad inmediata o la interfaz de usuario que un equipo típico de QA espera.
Para equipos que buscan una solución llave en mano con informes detallados, paneles de control o integraciones en los flujos CI/CD existentes, las ofertas comerciales de KushoAI (no detalladas aquí) podrían ser más adecuadas. Ten en cuenta que, como referencia de investigación, la fortaleza principal de APIEval-20 reside en experimentos controlados y comparativos, más que en plataformas de pruebas completas.
Cómo se compara APIEval-20 con alternativas
SWE-bench
- Qué hace de manera diferente: SWE-bench se centra más en evaluar habilidades generales de ingeniería de software, incluyendo la corrección de código, pruebas y depuración en varios lenguajes. Es más completo en la evaluación de la capacidad de codificación que en la detección de errores específicos de API. - Comparación de precios: SWE-bench suele ser un servicio de pago con opciones de suscripción, que a menudo cuesta cientos de dólares al mes dependiendo del uso. - Elige esto si... necesitas una evaluación amplia de ingeniería de software que incluya codificación y depuración además de pruebas de API. - Mantente con APIEval-20 si... tu objetivo principal es medir objetivamente la capacidad de una IA para encontrar errores específicos de API usando solo el esquema y las cargas útiles.APIBench
- Qué hace de forma diferente: APIBench ofrece una suite de escenarios de pruebas de API basados en colecciones reales de API, a menudo integradas con herramientas como Postman. Enfatiza flujos de trabajo de pruebas manuales y semiautomatizadas. - Comparación de precios: Muchas colecciones de APIBench son gratuitas o están incluidas con herramientas como Postman, pero las versiones empresariales completas pueden costar cientos al mes. - Elige esto si... quieres un entorno de pruebas práctico y práctico que se integre con las herramientas de pruebas de API existentes. - Mantén APIEval-20 si... buscas una evaluación objetiva y comparativa de la detección de errores de IA en lugar de un entorno de pruebas.HumanEval
- Qué hace de forma diferente: HumanEval está diseñado para evaluar modelos de generación de código por su capacidad de producir soluciones correctas a problemas de programación, centrándose en la corrección del código más que en las pruebas. - Comparación de precios: Generalmente gratis como parte de conjuntos de datos de investigación abiertos o limitado a benchmarks específicos. - Elige esto si... tu enfoque está en la precisión de la generación de código, no en la detección de errores de API. - Mantén APIEval-20 si... necesitas un benchmark específicamente para pruebas de API y detección de errores.Postman Collections / Postman AI
- Qué hace de forma diferente: Postman ofrece una interfaz fácil de usar para pruebas de API manuales y semiautomatizadas, incluida la generación de pruebas asistida por IA, pero no está diseñado como benchmark ni para una evaluación objetiva de detección de errores. - Comparación de precios: Nivel gratuito disponible; los planes de pago comienzan alrededor de 8 USD por usuario/mes para funciones adicionales. - Elige esto si... quieres una plataforma fácil de usar para pruebas manuales de API y colaboración. - Mantén APIEval-20 si... necesitas un benchmark objetivo y reproducible para la detección de errores de IA, no solo una herramienta de pruebas.Veredicto final: ¿Deberías probar APIEval-20?
En general, calificaría APIEval-20 alrededor de 7/10. Es un paso sólido hacia adelante para medir objetivamente la capacidad de una IA para encontrar errores reales en APIs, especialmente dada la naturaleza nicho de esta área. La configuración de caja negra y el enfoque en la detección real de errores lo hacen un benchmark significativo, pero todavía es relativamente nuevo y su alcance se limita a 20 escenarios. Si tu equipo está explorando herramientas de pruebas de IA o investigando capacidades de detección de errores, merece la pena echarle un vistazo.
Definitivamente, si trabajas en un entorno técnico donde la fiabilidad de las API es crucial y quieres ver cuán cerca están tus herramientas de IA de un ingeniero de QA, pruébalo. La capa gratuita es una buena manera de probarlo sin compromiso. Si necesitas una cobertura amplia de QA, pruebas de UI o depuración de sistemas de extremo a extremo, conviene complementarlo con otras herramientas.
Personalmente, lo recomendaría si tu objetivo es evaluar específicamente la detección de errores de IA. Si apenas comienzas o necesitas un conjunto de pruebas más completo, podrías encontrar mayor valor en herramientas establecidas como Postman o SWE-bench. Pero para la detección pura de errores en APIs, APIEval-20 es una opción prometedora y abierta.
Preguntas comunes sobre APIEval-20
¿Vale la pena APIEval-20 el dinero?
Sí, especialmente porque es gratis y de código abierto. Se trata más del valor de la evaluación comparativa y la investigación que de la inversión comercial directa.
¿Existe una versión gratuita?
Sí, el conjunto de datos y la evaluación comparativa están alojados abiertamente en Hugging Face y pueden ejecutarse localmente sin costo. No se requieren planes de pago para acceder.
¿Cómo se compara con otros benchmarks?
En comparación con benchmarks de código generales como HumanEval, APIEval-20 es más especializado y práctico para pruebas de API. Es más realista que las pruebas sintéticas, pero tiene un alcance más limitado.
¿Puede evaluar flujos de API de varios pasos?
Sí, incluye escenarios con procesos de múltiples pasos, probando la capacidad de un agente para manejar interacciones complejas.
¿Prueba la gestión de errores y los casos límite?
Absolutamente, muchos escenarios se centran en respuestas de error, restricciones de esquema y cargas útiles inusuales para desafiar la robustez de la IA.
¿Puedo obtener un reembolso?
Dado que la referencia es gratuita y abierta, los reembolsos no son aplicables. Para productos comerciales, consulta las políticas específicas del proveedor.
