¿Qué es Cipherra?
Honestamente, estaba bastante curioso acerca de Cipherra porque, como muchos ingenieros de ML, he pasado demasiado tiempo ejecutando manualmente conjuntos de evaluación y tratando de filtrar resultados inestables y difíciles de interpretar. La idea de una herramienta que promete automatizar este proceso — ejecutar evaluaciones a gran escala, diagnosticar fallos e incluso clasificar problemas — sonaba prometedora en teoría. Pero he aprendido a ser escéptico ante herramientas que hacen grandes promesas en la evaluación de IA, especialmente cuando no te dicen mucho sobre cómo funcionan realmente tras bambalinas.
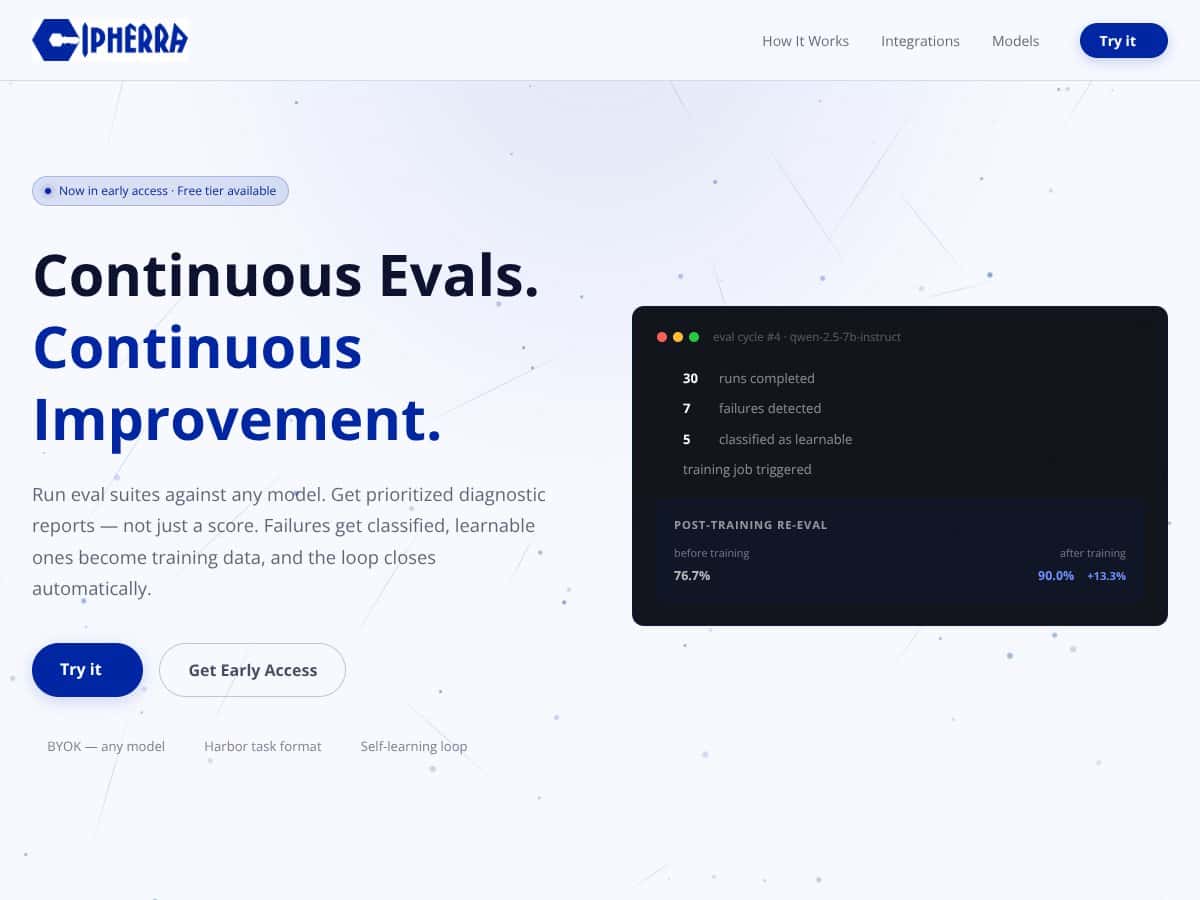
Lo que Cipherra afirma hacer, en su núcleo, es bastante directo: cargas tu modelo o lo diriges a tu API, especificas qué quieres evaluar, y ejecuta un montón de pruebas a través de múltiples contenedores o instancias. Luego, en lugar de darte solo una puntuación cruda, proporciona un informe diagnóstico que explica las fallas, clasifica las causas raíz y prioriza las correcciones. La idea es crear un bucle de retroalimentación cerrado para la mejora del modelo sin el dolor de cabeza manual de escribir scripts para las ejecuciones de evaluación por ti mismo.
En lo que está disponible públicamente, el sitio web de Cipherra no ofrece muchos detalles sobre quién está detrás ni las credenciales del equipo. Según el dominio y la marca, parece una startup de IA, pero no pude encontrar información clara sobre su empresa o fundadores. Eso siempre es una bandera roja para mí: si estoy considerando integrarlo en un flujo de trabajo serio, quiero saber quién lo construyó y si tienen experiencia en automatización de evaluaciones de ML. En mi impresión inicial, se comercializa como una herramienta para ingenieros de ML que realizan RL post-entrenamiento, pero, para ser honesto, el mensaje es bastante vago. Aunque destacan la evaluación continua y la mejora, los detalles son escasos.
¿Mi primera impresión? Según lo anunciado, parece centrarse en automatizar evaluaciones y proporcionar cierto nivel de diagnóstico de fallos. Pero me sorprendió descubrir que el sitio web no ofrece mucho en términos de documentación concreta, tutoriales o incluso informes de muestra. Por lo tanto, aconsejaría tomar las afirmaciones con pinzas hasta ver más ejemplos del mundo real o una demostración. No se comercializa como una solución todo-en-uno que cubra cada aspecto de la evaluación del modelo: es más bien una herramienta especializada para automatizar y diagnosticar ejecuciones de evaluación. Dicho esto, no esperes que solucione mágicamente todos tus dolores de cabeza de evaluación sin algo de configuración y comprensión de tu parte.
Características clave de Cipherra
Ejecutar suites de evaluación a gran escala
Esta función te permite enviar tus modelos o APIs para evaluación a través de múltiples contenedores o instancias. La idea es ejecutar pruebas redundantes para compensar el no determinismo en las salidas de los LLM. Encontré que esto es sencillo: subes tu paquete de tareas, configuras el endpoint de tu modelo, defines cuántas ejecuciones redundantes quieres y pulsas Iniciar. El proceso es relativamente rápido, pero advierto que si tu entorno de tareas no es estable o si entran en juego los límites de tasa de tu API, los resultados pueden volverse inestables. La plataforma parece no hacer mucho para gestionar límites de tasa o reintentos automáticamente, lo cual es algo que me gustaría que aclararan.
Informes de diagnóstico con clasificación de fallos
Esta es la promesa central: en lugar de solo puntuaciones, Cipherra analiza cada fallo, clasifica las causas raíz (como errores de API, problemas de configuración o regresiones del modelo) y prioriza las correcciones. En la práctica, me sorprendió descubrir que los informes sí ofrecen ideas útiles concretas, como modos de fallo específicos y clasificaciones de severidad. Sin embargo, no pude saber cuán profunda es el diagnóstico; parece que se basa en reglas heurísticas, pero sin documentación detallada o ejemplos, es difícil evaluar la precisión o la utilidad en escenarios complejos.
Trae tu propio Modelo (BYOK)
La plataforma afirma que funciona con cualquier modelo que tenga una API HTTP — OpenAI, modelos de lenguaje autoalojados (LLMs) o incluso instancias locales de Ollama. Probé esto con un par de endpoints, y aceptó claves de API y endpoints personalizados sin problemas. Pero noté que la configuración del entorno no se explica completamente desde el inicio: necesitas preparar tu paquete de tareas en formato Harbor, lo cual es un formato algo específico. Así que se requiere cierta configuración inicial, especialmente si te integrates con modelos personalizados o autoalojados.
Evaluación continua y automatización
Una de las ideas más atractivas es los ciclos de evaluación continuos: ejecutar pruebas automáticamente a medida que los modelos se actualizan o se reentrenan. Aunque no configuré esta función extensamente, la API y el panel de la plataforma sugieren que puedes activar evaluaciones bajo demanda o programarlas. Es un toque agradable, pero me gustaría ver más sobre cómo maneja ejecuciones inestables o si puede activar automáticamente el reentrenamiento basado en patrones de fallo. Esa parte todavía se siente algo incompleta desde mi perspectiva.
Redundancia y manejo del no determinismo
La plataforma ejecuta cada tarea varias veces de forma independiente para compensar la naturaleza no determinista de las salidas de los LLM. Es inteligente, pero los detalles de implementación son difusos. Por ejemplo, no estoy seguro de cuán bien maneja tareas que inherentemente tienen salidas estocásticas o si puede configurarse para ignorar cierta variabilidad. Además, los informes muestran métricas de varianza, lo cual es útil, pero te aconsejo probarlo con tu caso de uso específico para ver si realmente captura diferencias significativas.
Panel de control y acceso a la API
La interfaz de usuario es lo suficientemente limpia y los resultados aparecen en minutos. Sin embargo, noté que el panel se carga bastante rápido, pero carece de opciones de personalización profundas. Para flujos de trabajo más avanzados, quizá necesites apoyarte en la API REST, la cual está documentada pero no es muy amplia. De nuevo, me gustaría que hubiera más scripts de muestra o integraciones mostradas desde el inicio.
Precios y Planes
Los detalles sobre precios son bastante vagos: mencionan un nivel gratuito, pero no especifican límites ni características. El sitio web enlaza a planes, pero no pude encontrar una comparación clara o qué incluye el plan gratuito. Si solo estás probando, podría valer la pena intentarlo, pero para uso continuo querría más transparencia. Además, como no detallan los costos explícitamente, es difícil juzgar si esto ofrece una buena relación calidad-precio frente a realizar evaluaciones manualmente o con otras herramientas.
Cómo funciona Cipherra
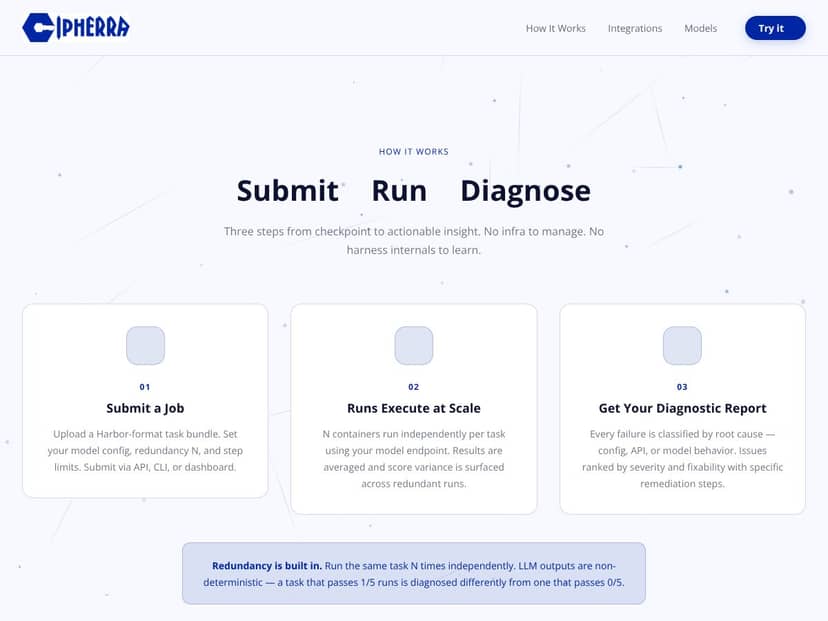
Comenzar con Cipherra fue una experiencia algo irregular. El proceso de registro en sí fue directo — no hubo fricción allí. Creas una cuenta, vinculas tu clave API o endpoint, y ya estás listo para subir un paquete de tareas. La interfaz es minimalista pero funcional, con un panel que muestra trabajos recientes y resultados. Sin embargo, me habría gustado que fueran más claros sobre la configuración inicial: por ejemplo, preparar tu paquete de tareas en formato Harbor no se explica con detalle, así que tuve que investigar un poco.
Una vez que cargué mi modelo y configuré parámetros — como el nivel de redundancia y los límites de pasos — hice clic en Enviar. Las ejecuciones de la evaluación comenzaron bastante rápido, y los resultados regresaron en unos minutos. El proceso fue en su mayoría automático, pero sí noté algunos contratiempos cuando se activaron mis límites de tasa de API o cuando el entorno estaba inestable. La plataforma no parece realizar reintentos automáticamente, por lo que las fallas a veces requerían intervención manual.
Los informes que recibí fueron lo suficientemente útiles para casos simples: las fallas se clasificaron en causas raíz, y las puntuaciones de severidad fueron útiles. Pero descubrí que para tareas más complejas, el diagnóstico parecía un poco superficial. No hay un desglose detallado de por qué ocurrió una falla — solo una clasificación de alto nivel y algunas soluciones sugeridas. Honestamente, me gustaría ver más transparencia aquí, especialmente si voy a depender de esto para iterar modelos de forma seria.
Una cosa que me gustaría que aclararan desde el principio es cómo maneja el proceso de evaluación el no determinismo. La redundancia ayuda, pero si tu tarea genera salidas variables por su naturaleza, no es obvio cómo interpretar la variabilidad de los resultados. Además, no encontré mucho en cuanto a análisis post hoc o seguimiento histórico, lo cual sería útil para el monitoreo continuo.
En general, el flujo de trabajo es lo suficientemente simple: subir, ejecutar, diagnosticar. Pero el diablo está en los detalles, y esos detalles están actualmente algo confusos o incompletos en la documentación. Recomendaría probarlo con tus propios modelos y configuración para ver si se ajusta a tus necesidades antes de comprometerte por completo.
En mi experiencia, Cipherra es interesante en concepto, pero todavía se siente como un trabajo en progreso. Tiene potencial, especialmente para equipos que desean automatizar evaluaciones y obtener hallazgos de fallos automatizados. Pero no esperes que reemplace un análisis manual profundo o diagnósticos detallados todavía. Es más bien un punto de partida que podría ahorrarte tiempo si se configura correctamente — pero prepárate para algo de prueba y error en el camino.
Precios de Cipherra: ¿Vale la pena?
| Plan | Precio | Qué Obtienes | Mi Opinión |
|---|---|---|---|
| Plan Gratuito | Desconocido | Acceso limitado, ejecuciones de evaluación básicas, y posiblemente algunas restricciones en tipos de modelos o la complejidad de las tareas | Ya que los detalles del nivel gratuito no son públicos, es difícil decir si ofrece lo suficiente para ser útil. Es probable que sea adecuado para experimentación inicial o pruebas a pequeña escala, pero probablemente no para evaluaciones serias o a gran escala. |
| Planes de pago | Consultar en el sitio web | Ejecuciones de evaluación ilimitadas o escalables, soporte prioritario, diagnósticos avanzados, y posiblemente funciones para empresas | La falta de precios explícitos dificulta saber si esto es una ganga o está sobrevalorado. Por lo general, herramientas como esta cobran según el uso o el tamaño del equipo, así que espera costos que aumenten con tus necesidades de evaluación. Sin números concretos, te aconsejo precaución: asegúrate de que el ROI justifique el gasto. |
Lo que hay que saber sobre los precios: sin detalles disponibles al público, es difícil determinar si Cipherra ofrece una buena relación calidad-precio. Si lo estás considerando, la mejor estrategia es comenzar con el plan gratuito o una prueba (si está disponible) para ver qué características necesitas realmente frente a lo que ofrecen los planes. Ten cuidado con costos ocultos como tarifas elevadas por uso de la API o límites que podrían convertirse en cuellos de botella para tu flujo de trabajo.
Lo que no te dicen en la página de ventas es si los planes de pago incluyen características como remediación automatizada, integraciones con tus pipelines CI/CD existentes o herramientas de colaboración en equipo. Si eso es importante para tu flujo de trabajo, verifica de nuevo qué está incluido antes de comprometerte.
Advertencia: si eres un equipo pequeño o un ingeniero en solitario, el costo podría ser prohibitivo a menos que la herramienta agilice significativamente tu proceso de evaluación. Para organizaciones más grandes, el valor podría justificar la inversión, pero de nuevo verifica los precios primero.
En general, mi valoración honesta es que hasta que vea detalles de precios claros y transparentes, es difícil recomendarlo como una solución rentable. Realiza la debida diligencia y solicita una demostración o una prueba antes de tomar una decisión.
Lo Bueno y Lo Malo
Lo que me gustó
- Clasificación automática de fallos: La forma en que Cipherra categoriza los fallos en causas raíz ahorra horas de depuración manual, lo que supone un ahorro de tiempo real para los equipos de ML.
- Redundancia integrada: Ejecutar varias pruebas independientes ayuda a mitigar problemas de evaluaciones inestables, aumentando la confianza en los resultados.
- Trae tu propio modelo: La compatibilidad con cualquier endpoint de modelo basado en HTTP ofrece flexibilidad, ya sea que estés usando OpenAI, autoalojados o modelos personalizados.
- Informes diagnósticos: En lugar de solo puntajes, obtener ideas prácticas con clasificaciones de severidad y facilidad de corrección puede ayudar a priorizar tus correcciones de forma eficaz.
- Escalabilidad y automatización: La API y el panel de control permiten integrar ejecuciones de evaluación en tus pipelines CI/CD, reduciendo el esfuerzo manual.
Qué podría mejorar
- Información pública limitada: La carencia de documentación detallada, listas de funcionalidades y precios dificulta evaluar si vale la pena adoptarlo.
- Sin reseñas o testimonios de usuarios: Sin comentarios reales de usuarios, no queda claro qué tan bien funciona la herramienta en escenarios reales y diversos.
- Complejidad potencial: La configuración parece sencilla, pero sin un proceso de incorporación guiado o documentación detallada, los nuevos usuarios podrían tener dificultades para obtener el máximo valor rápidamente.
- Brechas de funcionalidades: Funciones críticas como la integración con control de versiones, colaboración multiusuario o analítica avanzada no se han mencionado, lo que podría limitar la usabilidad para equipos más grandes.
- Transparencia de precios: No conocer los costos por adelantado podría disuadir a usuarios que necesitan presupuestar con cuidado o comparar alternativas.
¿Para quién es realmente Cipherra?
Según lo que puedo reunir, Cipherra parece ideal para ingenieros y equipos de ML que están desplegando modelos de forma activa y necesitan una forma escalable y automatizada de evaluar su rendimiento tras el entrenamiento. Si estás experimentando con grandes modelos de lenguaje, ajuste fino o iteración de puntos de control, esta herramienta podría agilizar tu proceso de diagnóstico.
Específicamente, es más útil si:
- Estás gestionando múltiples modelos o puntos de control y quieres una evaluación consistente sin necesidad de scripts manuales.
- Valoras diagnósticos detallados por encima de simples puntuaciones: quieres entender por qué un modelo falla o se degrada.
- Trabajas en un entorno CI/CD y necesitas automatización, redundancia y una entrega rápida.
- Te sientes cómodo usando tus propios modelos a través de endpoints de API e integrando los resultados de la evaluación en tu flujo de trabajo.
Por ejemplo, si eres un ingeniero de investigación probando diferentes puntos de control de aprendizaje por refuerzo (RL) o un ingeniero de producto desplegando modelos para uso en tiempo real, Cipherra podría ayudar a identificar problemas de forma temprana y priorizar las correcciones de manera eficiente. Es menos adecuado para las partes interesadas no técnicas o equipos que buscan paneles listos para usar con integraciones preconstruidas.
Quién debería buscar en otro lugar
Si eres una pequeña startup o un desarrollador independiente que solo necesita métricas de rendimiento rápidas y de alto nivel, esto podría ser excesivo. La falta de precios transparentes, orientación para la incorporación y comentarios de usuarios sugiere que podría estar más dirigido a equipos más grandes con recursos dedicados de MLOps.
Del mismo modo, si tu flujo de trabajo depende en gran medida de marcos de evaluación existentes como lm-eval o scripts personalizados y no buscas automatizar o escalar, el scripting tradicional podría seguir siendo tu mejor opción. Las fortalezas de Cipherra se encuentran en la automatización, el diagnóstico y la gestión de la complejidad a gran escala, lo cual podría ser innecesario para casos de uso más simples.
Y si no te sientes cómodo con integraciones de API o con traer tus propios modelos, o si necesitas una interfaz de usuario más pulida con integraciones preconstruidas (p. ej., con plataformas de ML o herramientas de gestión de datos), entonces esta plataforma podría no satisfacer tus necesidades.
En resumen, esto no es una solución única para todos. Está diseñado para equipos de ML con flujos de trabajo de evaluación complejos que buscan automatización y profundidad diagnóstica, en lugar de quienes buscan ideas rápidas y simplificadas o soluciones asequibles.
Cómo se compara Cipherra con las alternativas
Weights & Biases (W&B)
- Qué lo distingue: W&B ofrece un seguimiento completo de experimentos, versionado de modelos y herramientas de visualización adaptadas para equipos de ML. Se trata más de gestionar todo el ciclo de vida del ML que de centrarse en la evaluación de modelos a gran escala.
- Precio: Comienza con una versión gratuita con funciones básicas; los planes de pago comienzan alrededor de $49/mes para almacenamiento adicional y capacidades para equipos. Es más asequible, pero menos especializado para la evaluación post-entrenamiento.
- Elige esto si... Necesitas una plataforma de gestión de experimentos de ML todo en uno y quieres una integración fluida con tu código y tus conjuntos de datos.
- Quédate con Cipherra si... Te enfocas en ejecutar suites de evaluación a gran escala a través de puntos de control de modelos y necesitas informes diagnósticos detallados, no solo seguimiento de experimentos.
Herramientas de Evaluación de Modelos de OpenAI
- Qué lo distingue: Estas son suites de evaluación integradas que se utilizan dentro del ecosistema API de OpenAI, diseñadas principalmente para evaluar modelos GPT durante el desarrollo, con personalización limitada.
- Precio: Por lo general se incluye con el uso de la API, por lo que los costos dependen de tu plan de API; no hay tarifa dedicada para la plataforma de evaluación.
- Elige esto si... Tu trabajo está fuertemente integrado con modelos de OpenAI y prefieres evaluaciones rápidas y estandarizadas.
- Mantente con Cipherra si... Necesitas flexibilidad para evaluar cualquier modelo, a gran escala, con diagnósticos detallados que vayan más allá de las herramientas API estándar.
Pipelines de Evaluación de Modelos de Hugging Face
- Qué lo hace diferente: Hugging Face ofrece pipelines fáciles de usar para evaluar modelos en diversas tareas, con modelos y conjuntos de datos de la comunidad. Se centra más en evaluaciones rápidas que en diagnósticos a gran escala posteriores al entrenamiento.
- Precios: Principalmente gratuitos y de código abierto; las opciones en la nube pueden implicar costos, pero, en general, son accesibles.
- Elige esto si... Quieres un marco de evaluación de código abierto, flexible, con mucho soporte de la comunidad para diferentes tareas de PLN.
- Mantente con Cipherra si... Necesitas diagnósticos escalables, detallados e independientes del modelo que vayan más allá de las simples evaluaciones de pipelines.
Suite de Evaluación de Modelos de Google (p. ej., Vertex AI)
- Qué lo hace diferente: Ofrece evaluación de modelos integrada dentro de Google Cloud, enfocándose en el despliegue, monitorización y diagnósticos a gran escala para uso empresarial.
- Precios: Pago por uso basado en cómputo, almacenamiento y llamadas a API; puede ser costoso para equipos pequeños.
- Elige esto si... Ya estás invertido en GCP y necesitas herramientas robustas e integradas de evaluación y monitorización a gran escala.
- Mantente con Cipherra si... No estás atado a GCP y necesitas una herramienta de evaluación más flexible, independiente del modelo, diseñada para escenarios de RL post-entrenamiento.
Conclusión: ¿Deberías probar Cipherra?
Honestamente, calificaría Cipherra en aproximadamente 5 de 10 en este momento. El problema principal es la falta de información pública disponible y verificada, por lo que es difícil saber qué tan bien funciona en la práctica o si vale la pena la inversión. Si eres ingeniero de ML que trabaja intensamente en RL post-entrenamiento y quieres una herramienta que pueda ejecutar suites de evaluación a gran escala con diagnósticos detallados, podría valer la pena explorarlo una vez que aclaren sus ofertas.
Sin embargo, si solo buscas una evaluación rápida y confiable o gestión de experimentos, existen opciones más consolidadas como Weights & Biases o Hugging Face que cuentan con buen soporte y son ampliamente confiables. Cipherra parece prometedora, pero aún es bastante opaca en esta etapa.
¿Mi consejo? Prueba la capa gratuita si ofrecen una; si te da lo que necesitas, genial. Si no, o si necesitas herramientas probadas ahora, mantente con las alternativas. Personalmente no recomendaría invertir fuertemente en Cipherra hasta que surjan más comentarios de usuarios y detalles oficiales.
En resumen: si tienes curiosidad por probar una plataforma de evaluación potencialmente poderosa y te sientes cómodo con información limitada, dale una oportunidad. Si necesitas herramientas estables y probadas ahora mismo, es mejor gastar tu dinero en otro lugar.
Preguntas frecuentes sobre Cipherra
- ¿Vale la pena Cipherra por su precio? Es difícil decirlo sin precios verificados o comentarios de usuarios. Podría valer la pena si ofrece diagnósticos detallados a gran escala, pero actualmente la información es escasa.
- ¿Existe una versión gratuita? No hay una capa gratuita confirmada ni prueba disponible públicamente. Deberás consultar con el proveedor para obtener detalles.
- ¿Cómo se compara con Weights & Biases? W&B ofrece un seguimiento de experimentos y visualización más establecidos, mientras que Cipherra afirma centrarse en diagnósticos de evaluación a gran escala, aunque los detalles son limitados.
- ¿Qué modelos admite? La información oficial no lo especifica, pero afirma poder admitir cualquier modelo, suponiendo que esté diseñado para ingenieros de ML que trabajan con arquitecturas diversas.
- ¿Puedo obtener un reembolso? Las políticas de reembolso no están detalladas públicamente; es probable que dependan de los términos del proveedor.
- ¿Es adecuado para modelos que no son RL? Probablemente, pero su fortaleza parece estar en la evaluación posterior al entrenamiento de RL. Confirme con el proveedor para casos de uso específicos.
