FixMyApp
FixMyApp review: Great for verified, production-ready fixes but limited transparency on pricing. Here's my honest assessment after testing.
Read review
Gemini 3.1 Pro offers advanced reasoning and multimedia tools but comes at a higher cost. Here's my honest review after testing in 2026.
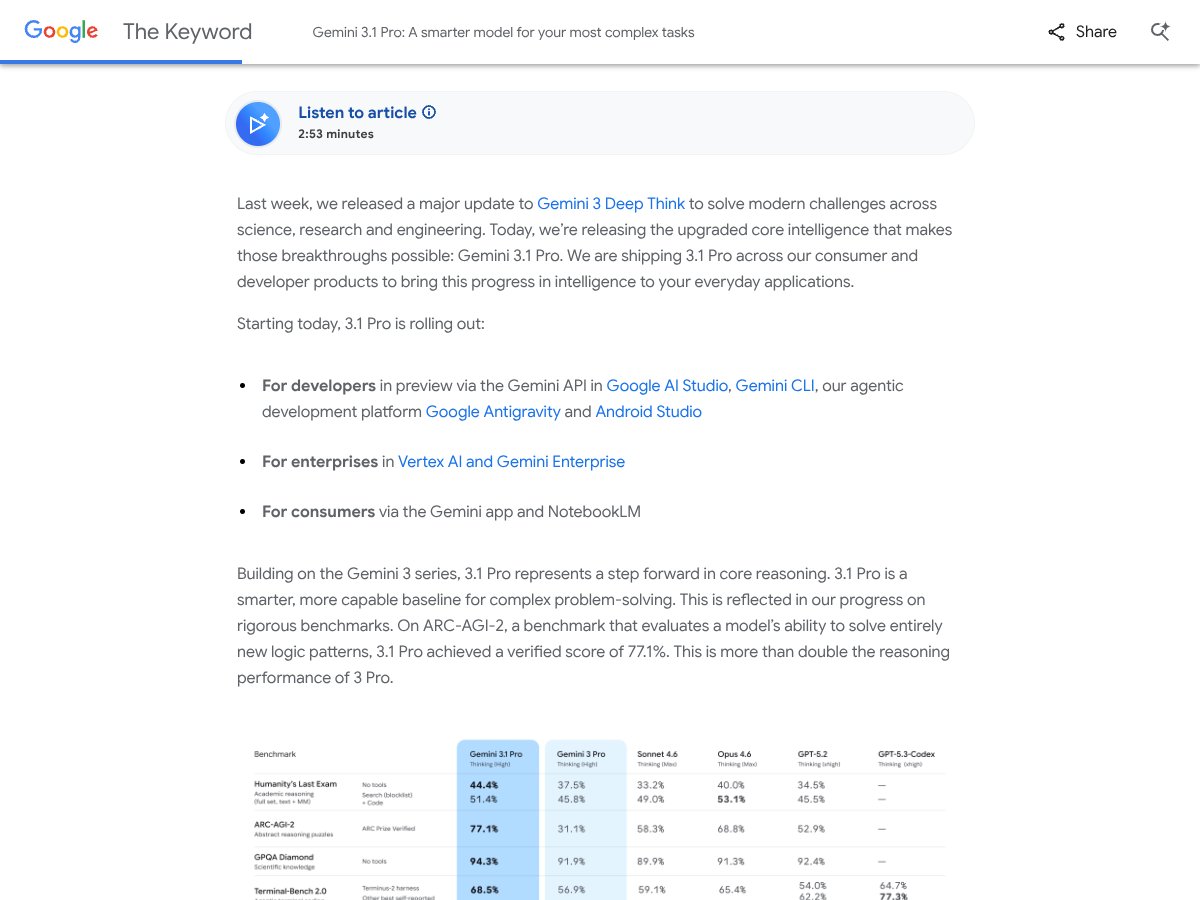
Gemini 3.1 Pro offers advanced reasoning and multimedia tools but comes at a higher cost. Here's my honest review after testing in 2026.
It’s worth it if you need long, detailed responses and multimedia features; otherwise, more affordable models might suffice.
Yes, US college students can access it free for 12 months through the Google AI Pro student trial, but a payment method is required.
GPT-5.2 is more versatile and cheaper per token for general use, but Gemini excels in multimodal outputs and extended reasoning.
Refund policies depend on your platform; check Google’s terms, but typically there’s a window within which refunds are possible.
Extended reasoning, 65K token limit, multimedia content generation, and integrated creative workflows.
Yes, via API, but note the $250 spend threshold and 30-day wait for production-level access.
Continue with tools in the same category, including screenshots and published Automateed reviews.
FixMyApp review: Great for verified, production-ready fixes but limited transparency on pricing. Here's my honest assessment after testing.
Read review
Ship Superfast review: Great for rapid MVPs with integrated features but limited customization. Here's my honest assessment after testing.
Read review
AskAIBase review: Great for structured AI solution management but with limited public adoption. Here's my honest assessment after testing.
Read review
Devin for Terminal offers fast local AI assistance with seamless terminal integration, but cloud handoff can add delays. Honest review after testing.
Read review
DronaHQ Agentic Platform review: Great for enterprise AI agents but can be complex for small teams. Here's my honest assessment after testing.
Read review
Code Arena review: Great for testing AI models in web apps but can be pricey. Here's my honest assessment after trying it out.
Read review
Quash review: Great for automating mobile QA with AI and bug context, but pricing details are unclear. Here's my honest assessment after testing.
Read review
Miniloop review: Great for automating complex workflows with AI and Python, but early-stage product may need some technical skill. Here's my honest...
Read reviewAs featured on
Add this badge to your site