Table of Contents
Looking for an easy way to access powerful AI models without the hassle? Nebius AI Studio promises enterprise-grade performance with zero MLOps skills required. I’ve tested this platform and found it to be a game-changer for both beginners and professionals. In this review, I’ll share my honest experience, key features, and what you can expect. Ready to discover how Nebius AI Studio can elevate your AI projects? Let’s dive in and see what this platform has to offer.
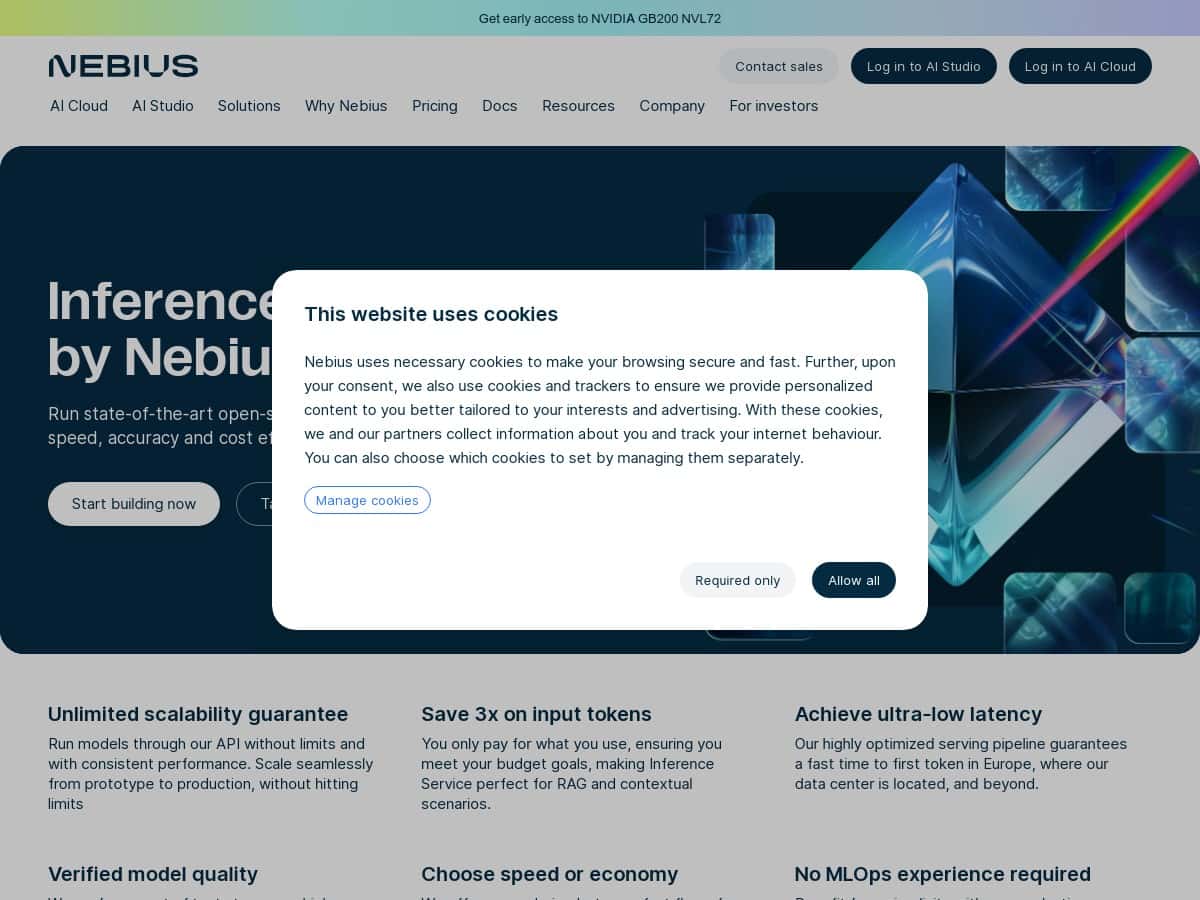
Nebius AI Studio Review
By trying Nebius AI Studio firsthand, I was pleasantly surprised by how straightforward and efficient it is. The setup was simple, and I could start testing models almost immediately—thanks to their user-friendly interface and ready-to-use infrastructure. Whether I wanted quick responses or cost savings, the platform offered flexible options. The ultra-low latency response times, especially in Europe, really stood out during my testing sessions. I could run unlimited model predictions through their API, making it ideal for both prototypes and large-scale deployment. Overall, it’s a robust solution that makes AI accessible without sacrificing performance.
Key Features
- Unlimited Scalability Guarantee supports unlimited model runs through an API, ensuring no performance drops as your project grows.
- Cost Efficiency helps you save on tokens, with pay-as-you-go pricing tailored for RAG and context-heavy use cases.
- Ultra-Low Latency delivers fast response times, especially in Europe, perfect for time-sensitive applications.
- Verified Model Quality ensures high accuracy through thorough testing of open-source models.
- Choice of Processing Options allows switching between fast processing for urgent needs or economical options for cost savings.
- No MLOps Required provides a ready-to-use infrastructure, removing the complexity of managing AI models.
Pros and Cons
Pros
- User-friendly interface that simplifies AI model usage
- Cost-effective pricing structure making AI accessible to many
- No MLOps expertise needed, suitable for all users
- Highly scalable for small projects and enterprises
- Optimized for speed and low latency performance
Cons
- Some specialized models might not be available
- Basic knowledge of API integration could be needed for advanced users
Pricing Plans
Starting with free credits worth $1, new users can explore the platform via the Playground or API without any upfront costs. The platform offers a no-code web interface to try various models easily. You can choose between two service flavors—fast processing for quick results or economical options for lower costs. For detailed pricing, visit the official Nebius website, as plans are tailored to different project needs and usage levels.
Wrap up
In summary, Nebius AI Studio stands out as a powerful, user-friendly platform for accessing open-source AI models efficiently. Its flexibility, scalability, and cost-effectiveness make it suitable for hobbyists, startups, and large enterprises alike. While there may be some limitations on specialized models, its ease of use and performance benefits outweigh these concerns. If you’re looking to integrate AI into your projects without complicated setup or MLOps skills, Nebius AI Studio is definitely worth exploring.