
OMGiftv
OMGiftv review: features, pricing, pros, cons, use cases, and alternatives to consider before trying this AI tool.
Read review
Owl Browser review: Great for stealth automation and fingerprint spoofing but not ideal for casual privacy. Here's my honest take after testing.
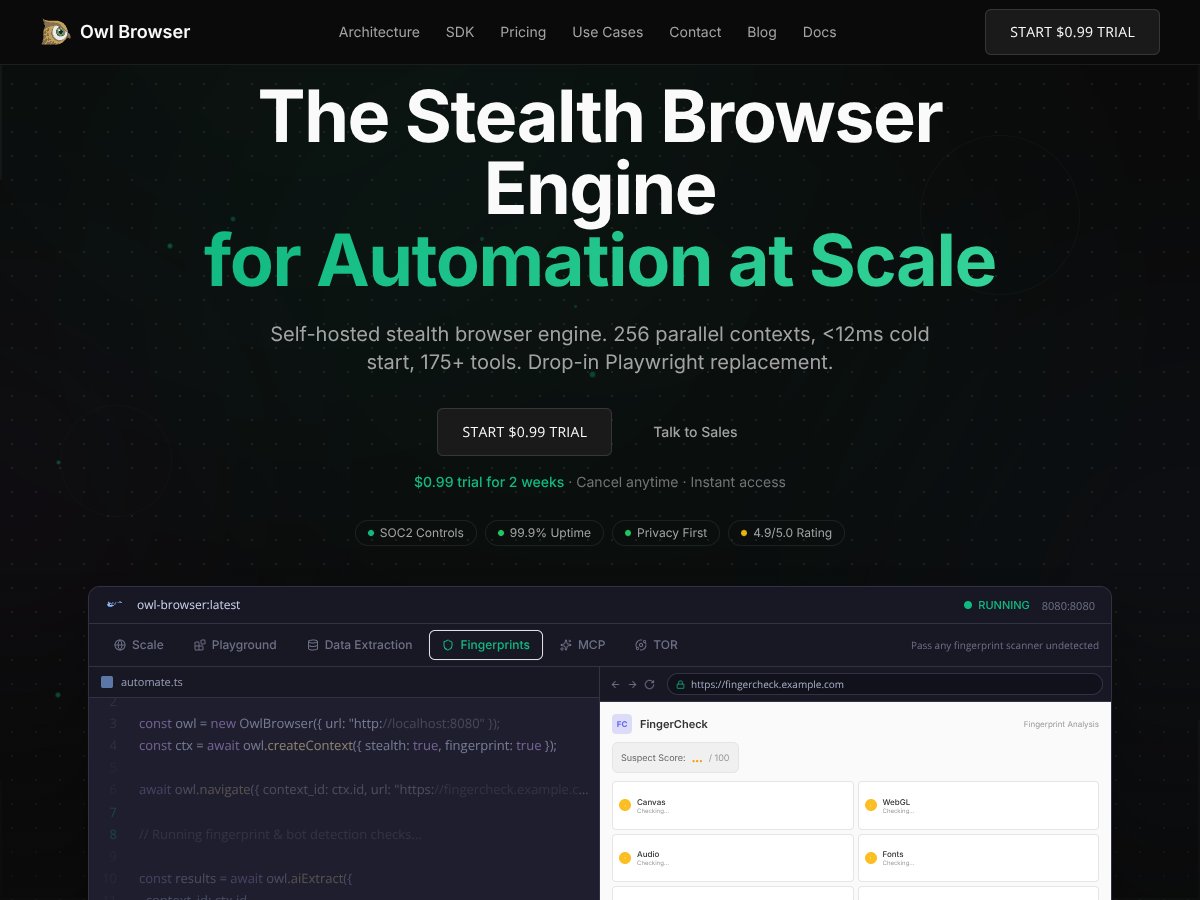
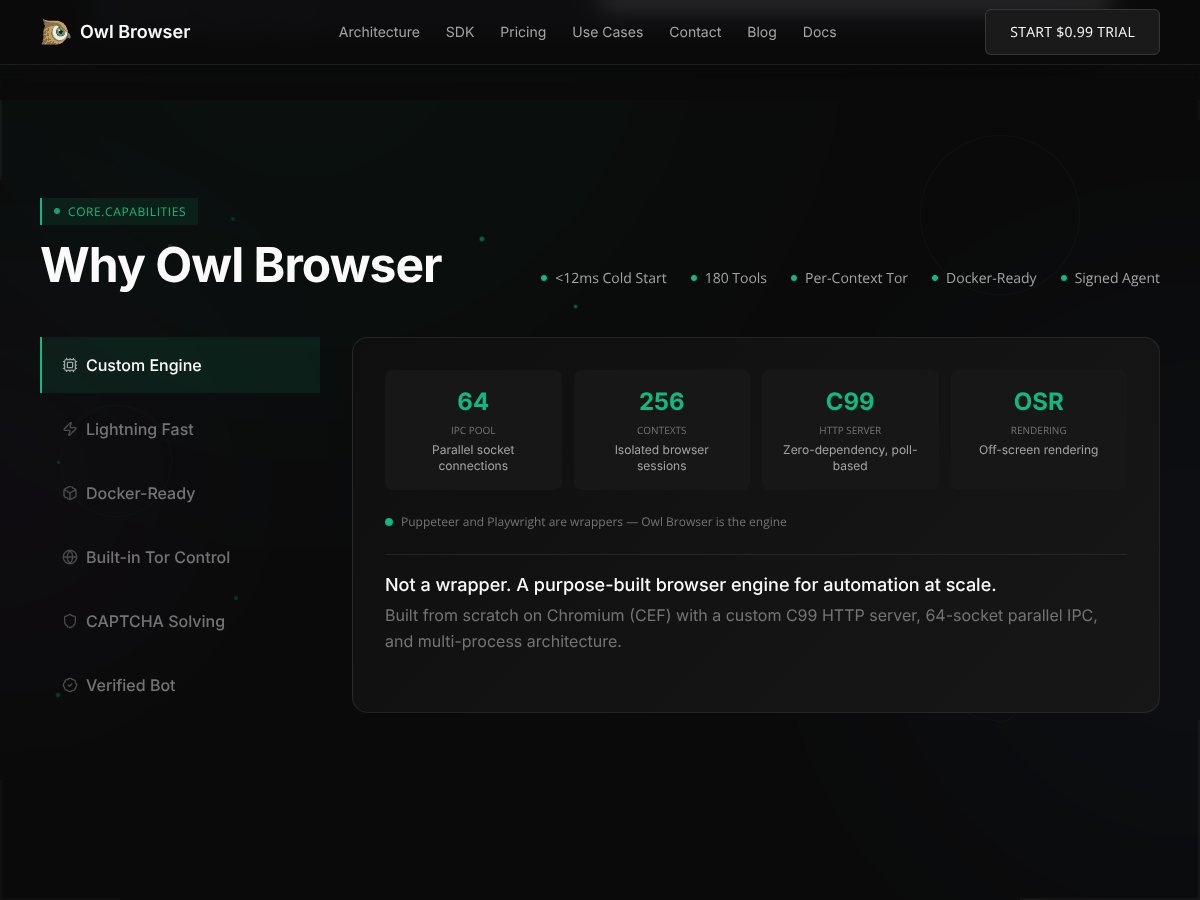
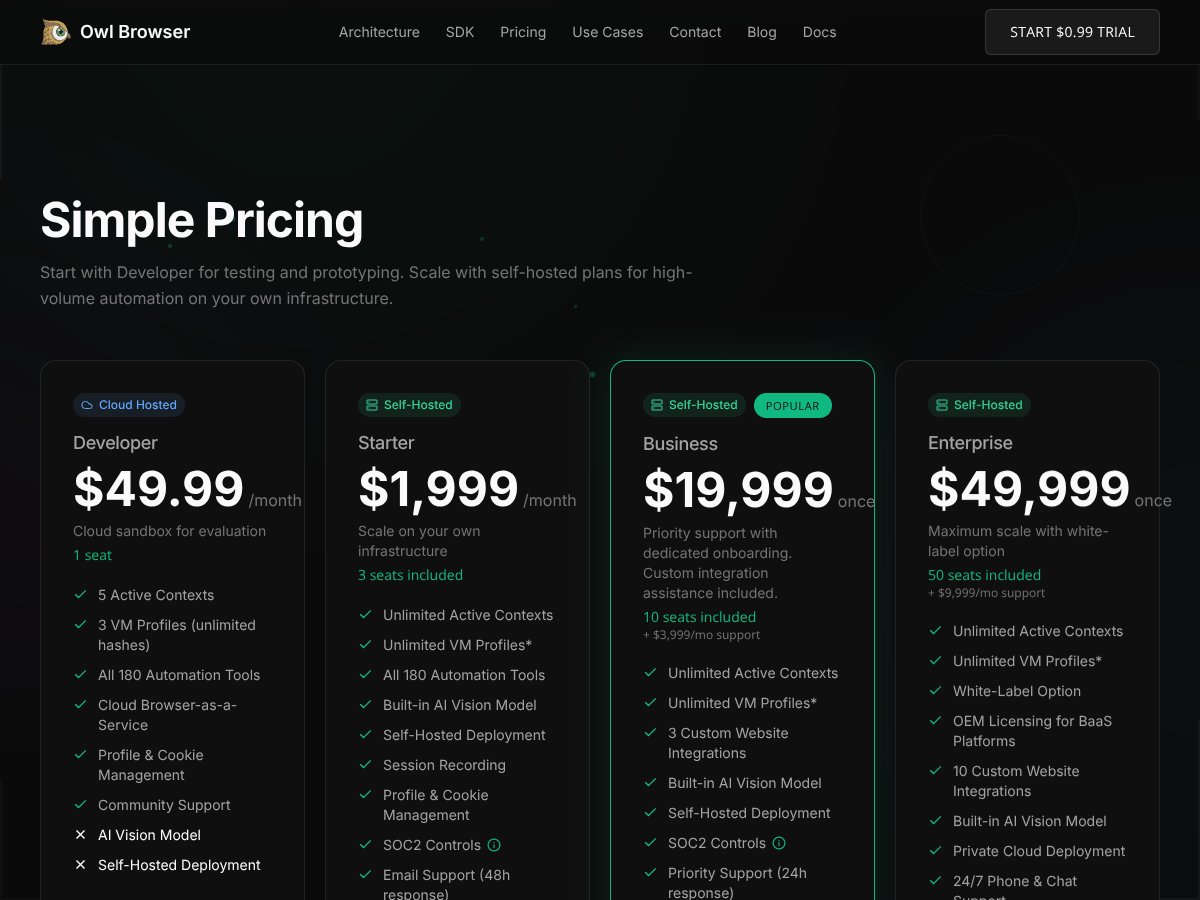
Owl Browser review: Great for stealth automation and fingerprint spoofing but not ideal for casual privacy. Here's my honest take after testing.
If you need undetectable automation and self-hosting, it’s a solid investment. For casual privacy, other tools might be cheaper.
Yes, but it’s limited. The paid plans unlock the full features and capacity.
Owl offers more customization and stealth at a lower cost, ideal for self-hosted stealth setups, while Multilogin is more enterprise-focused.
Yes, it’s designed for automation, with AI features and multiple parallel contexts for complex workflows.
It requires some technical knowledge, especially for self-hosting, but detailed docs help streamline the process.
Refund policies vary; check the vendor’s terms before purchasing to be sure.
Continue with tools in the same category, including screenshots and published Automateed reviews.
OMGiftv review: features, pricing, pros, cons, use cases, and alternatives to consider before trying this AI tool.
Read review
Liner Write offers source-backed drafting but can be complex for new users. Here's my honest review after testing its pros and cons.
Read review
BlocPad offers real-time collaboration and integrated docs, but limited enterprise features. Read my honest review to see if it fits your team.
Read review
Xalvion review: Great for AI model selection but falls short on verified features and pricing. Here's my honest take after testing.
Read review
Auvylo offers personalized AI reflection from charts but lacks clear pricing. Good for astrology enthusiasts wanting deeper insights; limited...
Read review
Astropad Workbench review: Great for monitoring AI agents and headless Macs but limited free tier. Here's my honest assessment after testing.
Read review
Oasis Browser for Mac review: Great for privacy and AI workflows but still in beta. Here's my honest opinion after testing this promising new browser.
Read review
YourToolsKit offers free, privacy-focused browser tools for quick tasks but lacks advanced features. Here's my honest review after testing.
Read reviewAs featured on
Add this badge to your site