
OMGiftv
OMGiftv review: features, pricing, pros, cons, use cases, and alternatives to consider before trying this AI tool.
Read review
ChatSpread review: Great for comparing multiple AI responses but lacks detailed info. Here's my honest assessment after testing this emerging tool.
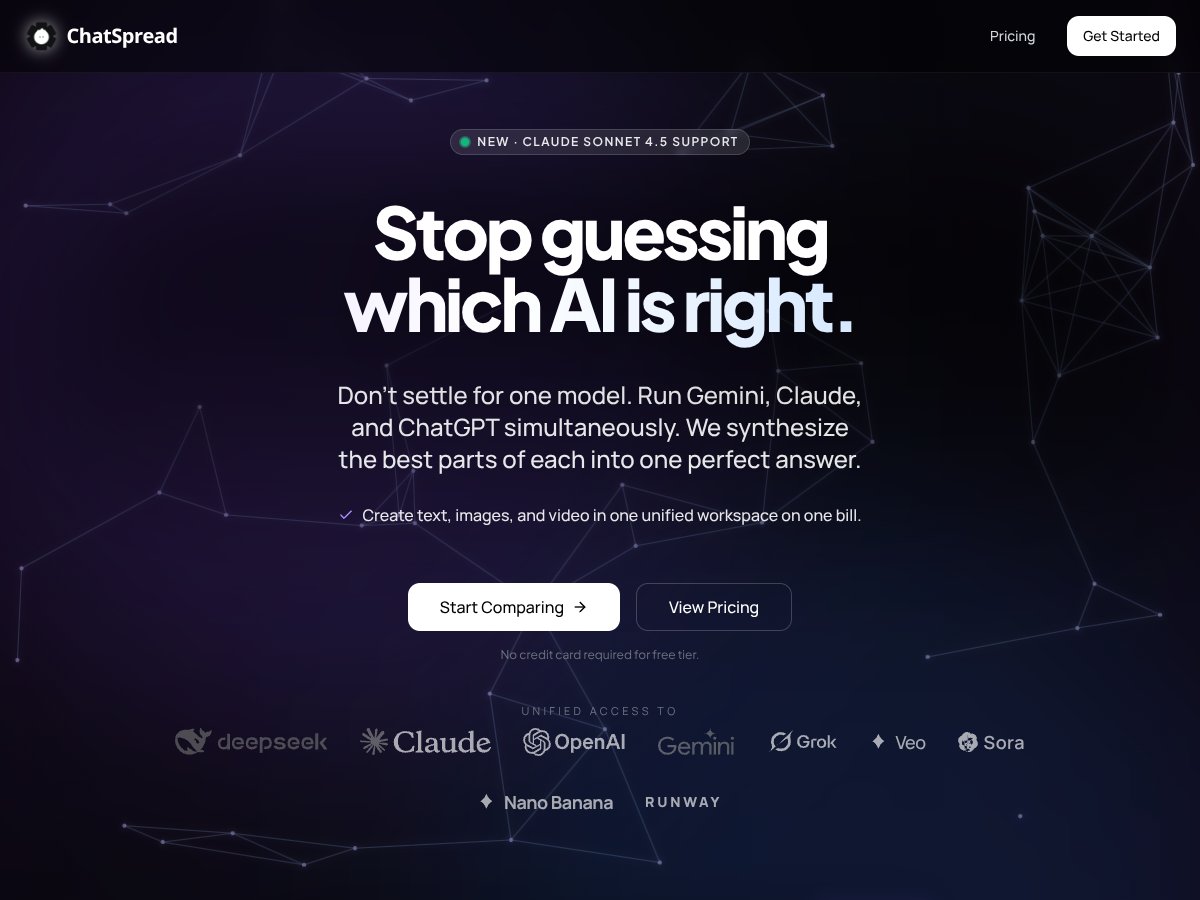
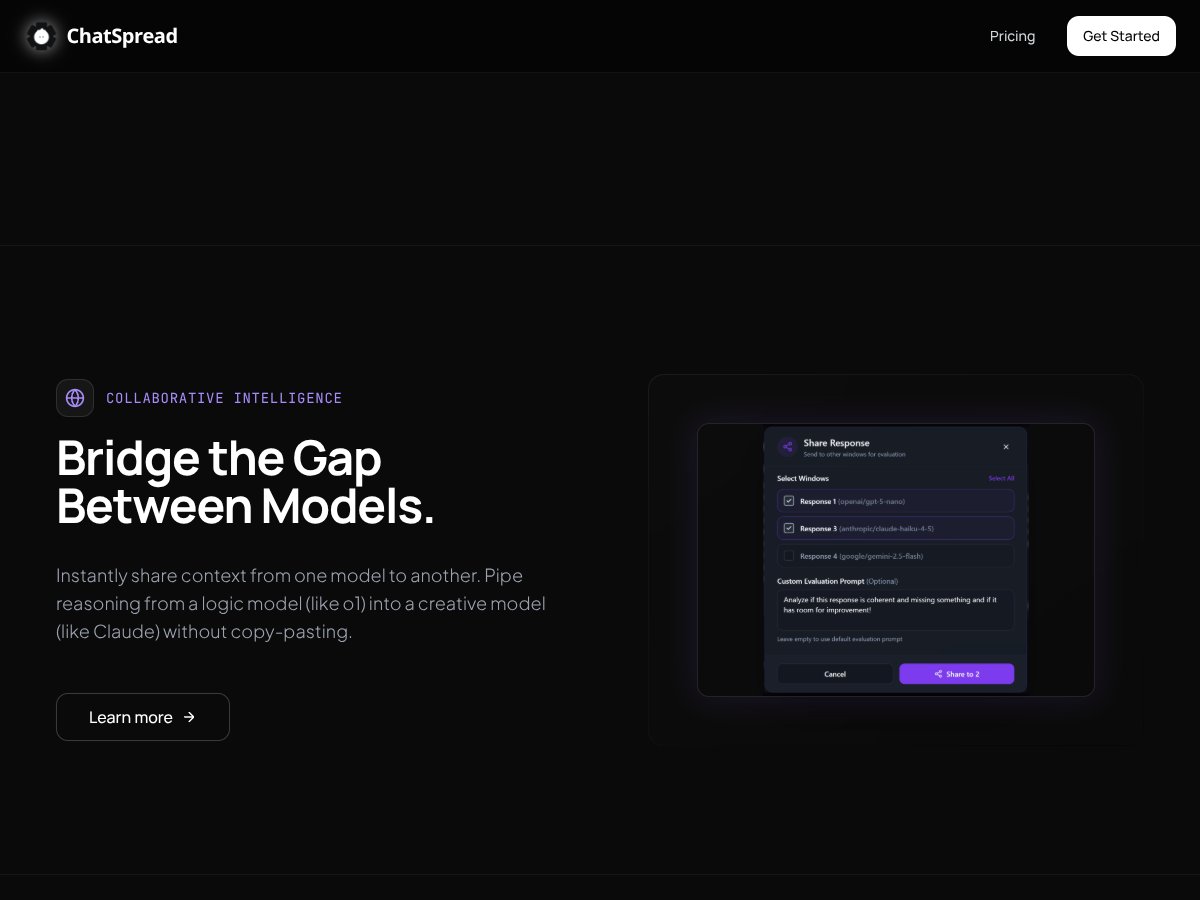
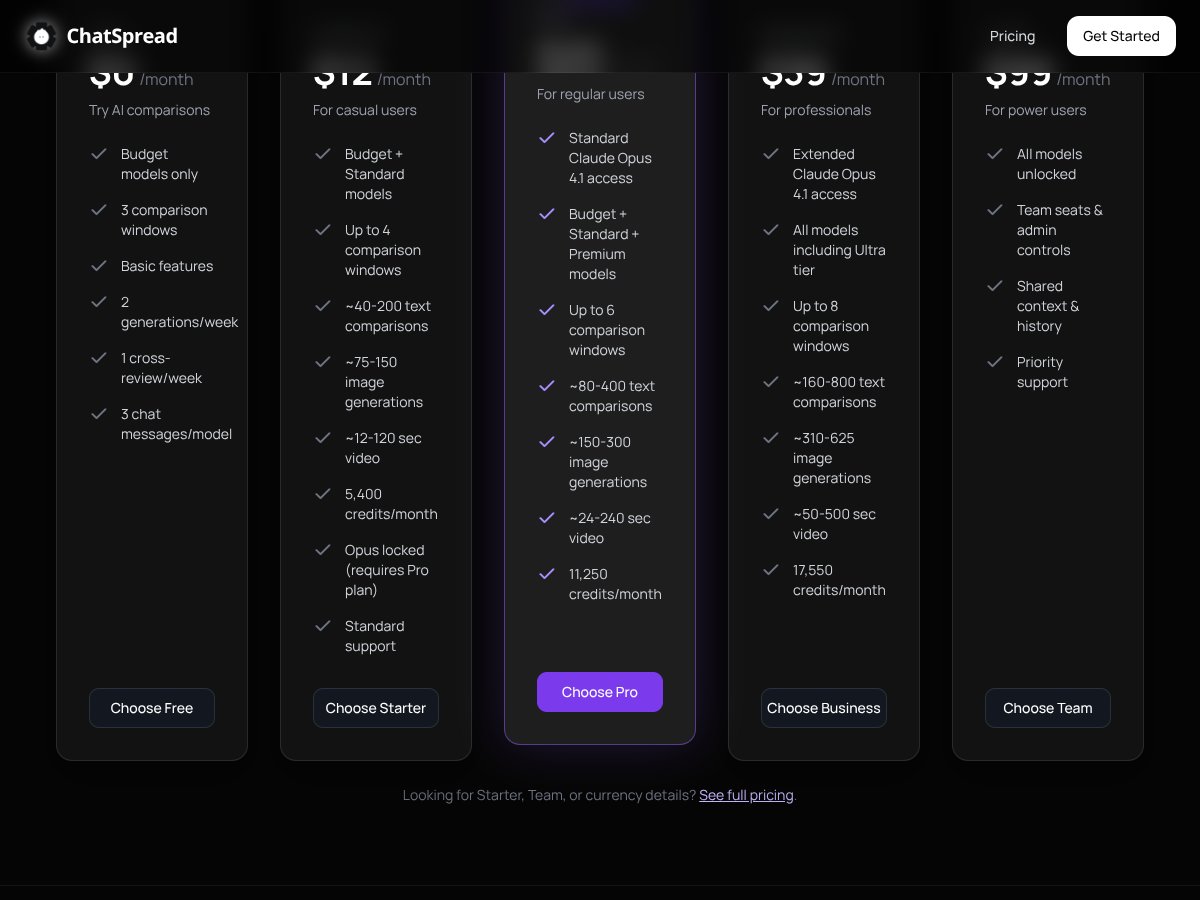
ChatSpread review: Great for comparing multiple AI responses but lacks detailed info. Here's my honest assessment after testing this emerging tool.
It's hard to tell without more info, but if you need to compare multiple AI responses regularly, it might be worth trying with a trial first.
No dedicated free tier has been announced, but look for demos or trial periods to evaluate it.
Unlike many tools that focus on chatbots or CRM, ChatSpread aims to compare responses from multiple AI models side by side, which is a unique feature.
Details about refunds aren’t publicly available; check their terms or contact support if needed.
Specific models aren’t confirmed, but the platform likely supports popular options like GPT-3, GPT-4, or similar APIs.
No user reviews are out yet, but it’s expected to have a straightforward interface for comparing responses.
Continue with tools in the same category, including screenshots and published Automateed reviews.
OMGiftv review: features, pricing, pros, cons, use cases, and alternatives to consider before trying this AI tool.
Read review
Liner Write offers source-backed drafting but can be complex for new users. Here's my honest review after testing its pros and cons.
Read review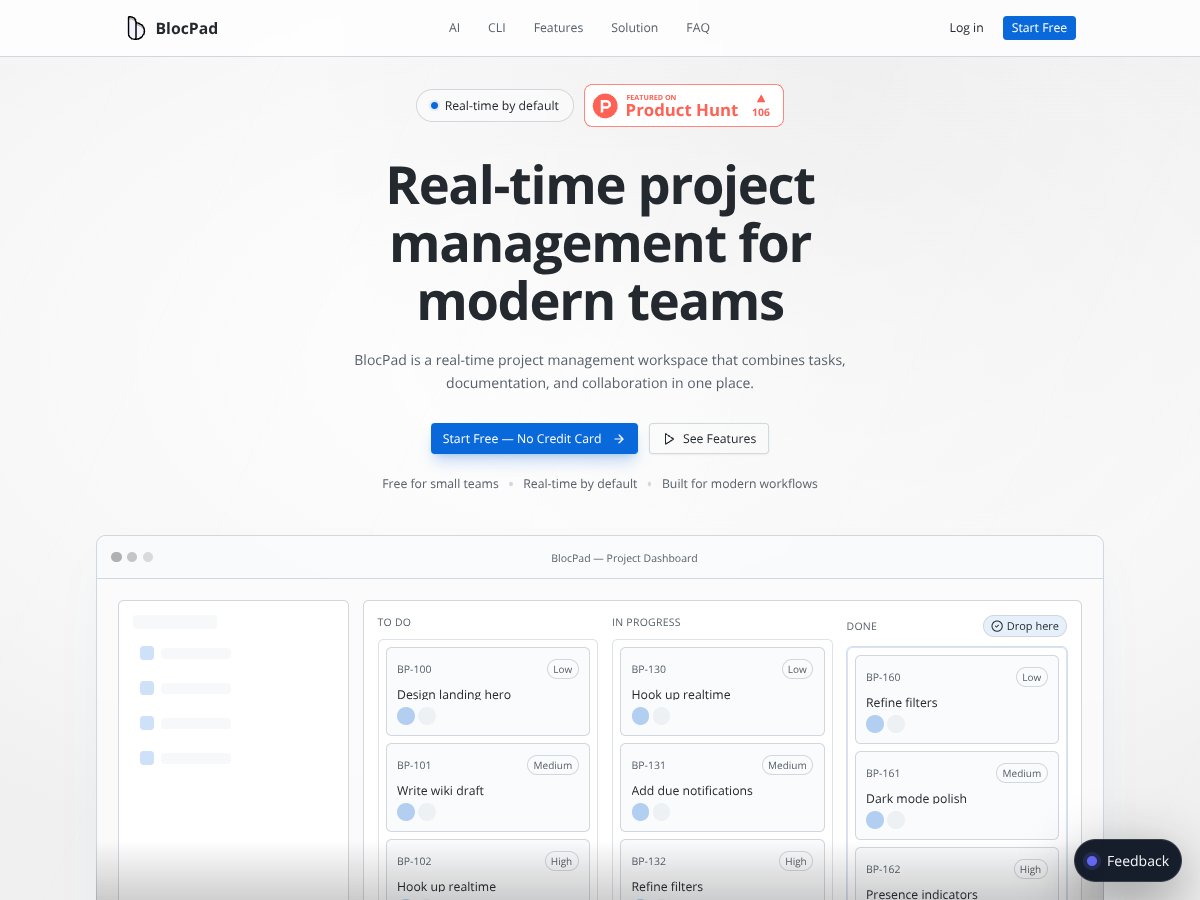
BlocPad offers real-time collaboration and integrated docs, but limited enterprise features. Read my honest review to see if it fits your team.
Read review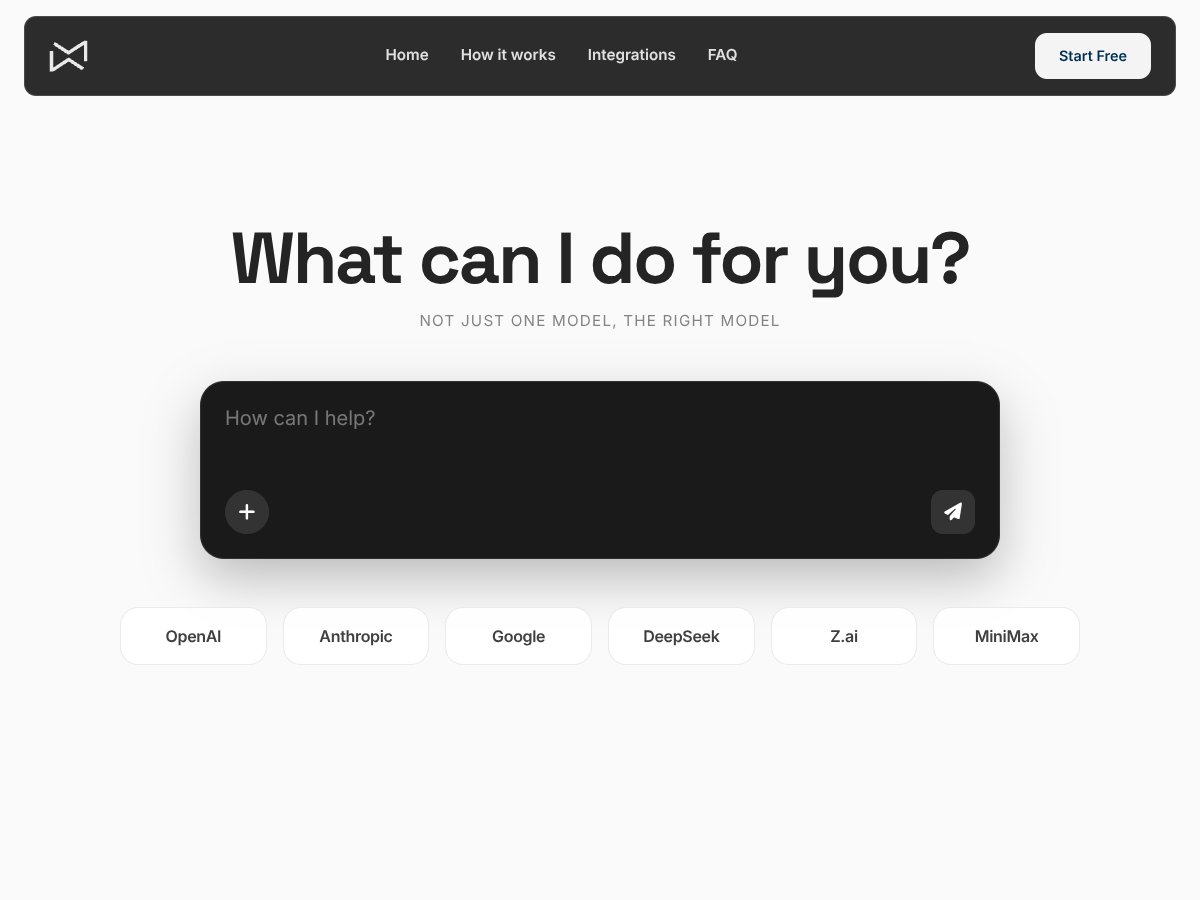
Xalvion review: Great for AI model selection but falls short on verified features and pricing. Here's my honest take after testing.
Read review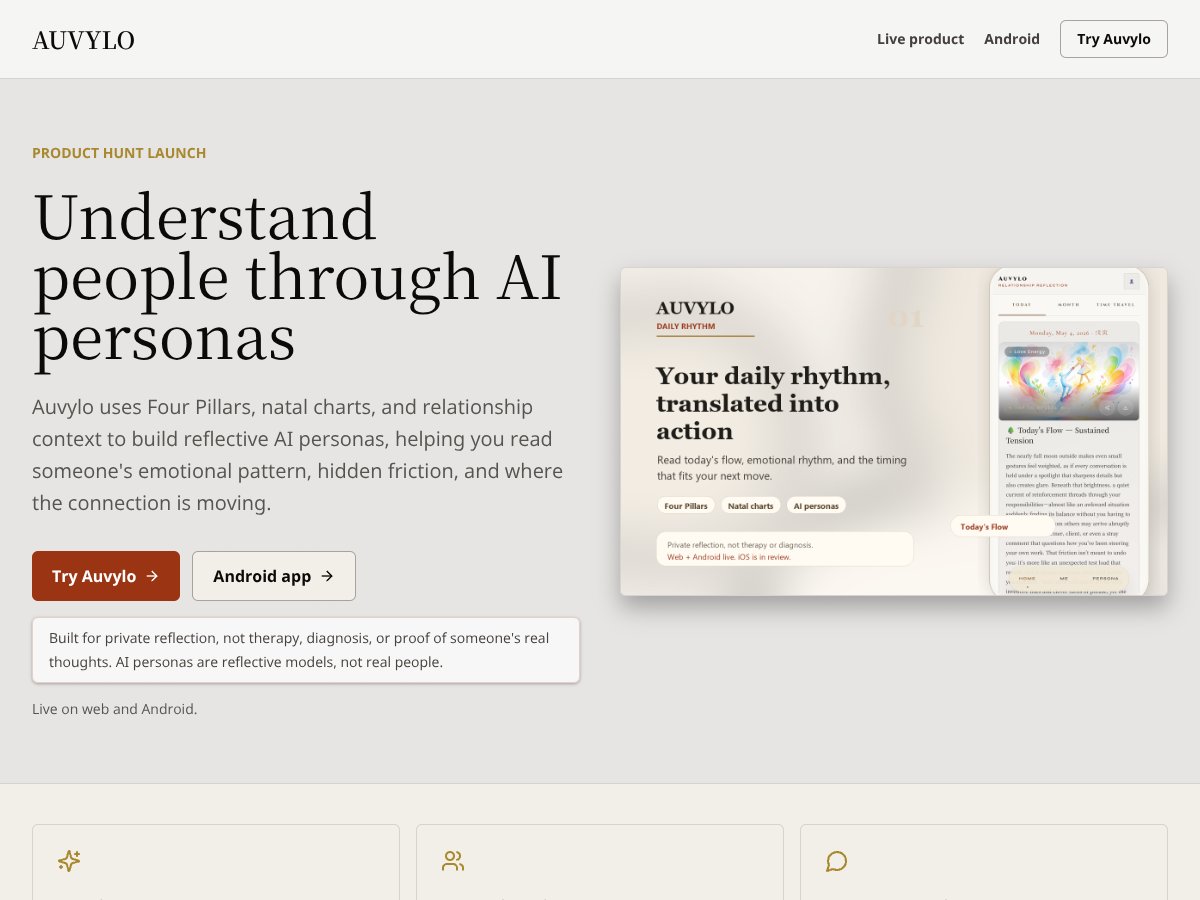
Auvylo offers personalized AI reflection from charts but lacks clear pricing. Good for astrology enthusiasts wanting deeper insights; limited...
Read review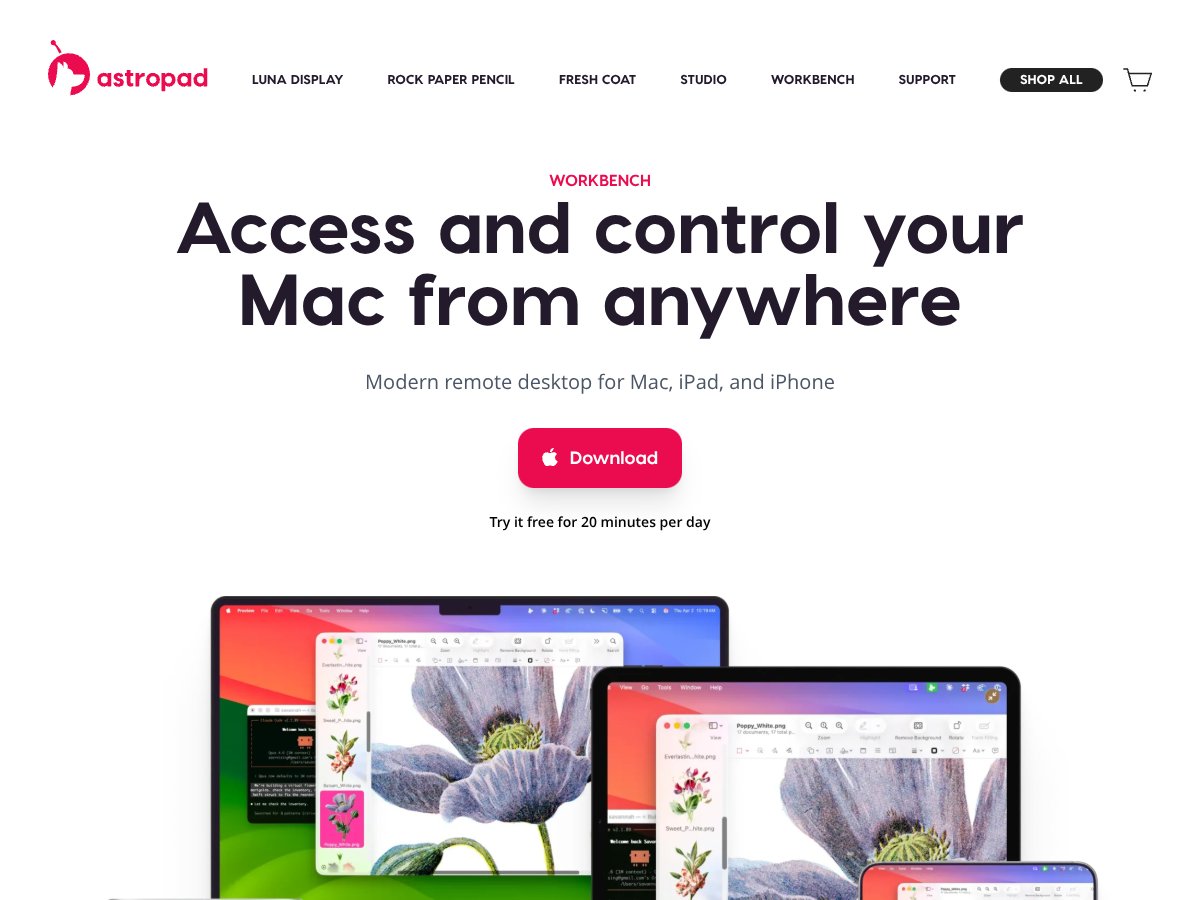
Astropad Workbench review: Great for monitoring AI agents and headless Macs but limited free tier. Here's my honest assessment after testing.
Read review
Oasis Browser for Mac review: Great for privacy and AI workflows but still in beta. Here's my honest opinion after testing this promising new browser.
Read review
YourToolsKit offers free, privacy-focused browser tools for quick tasks but lacks advanced features. Here's my honest review after testing.
Read reviewAs featured on
Add this badge to your site