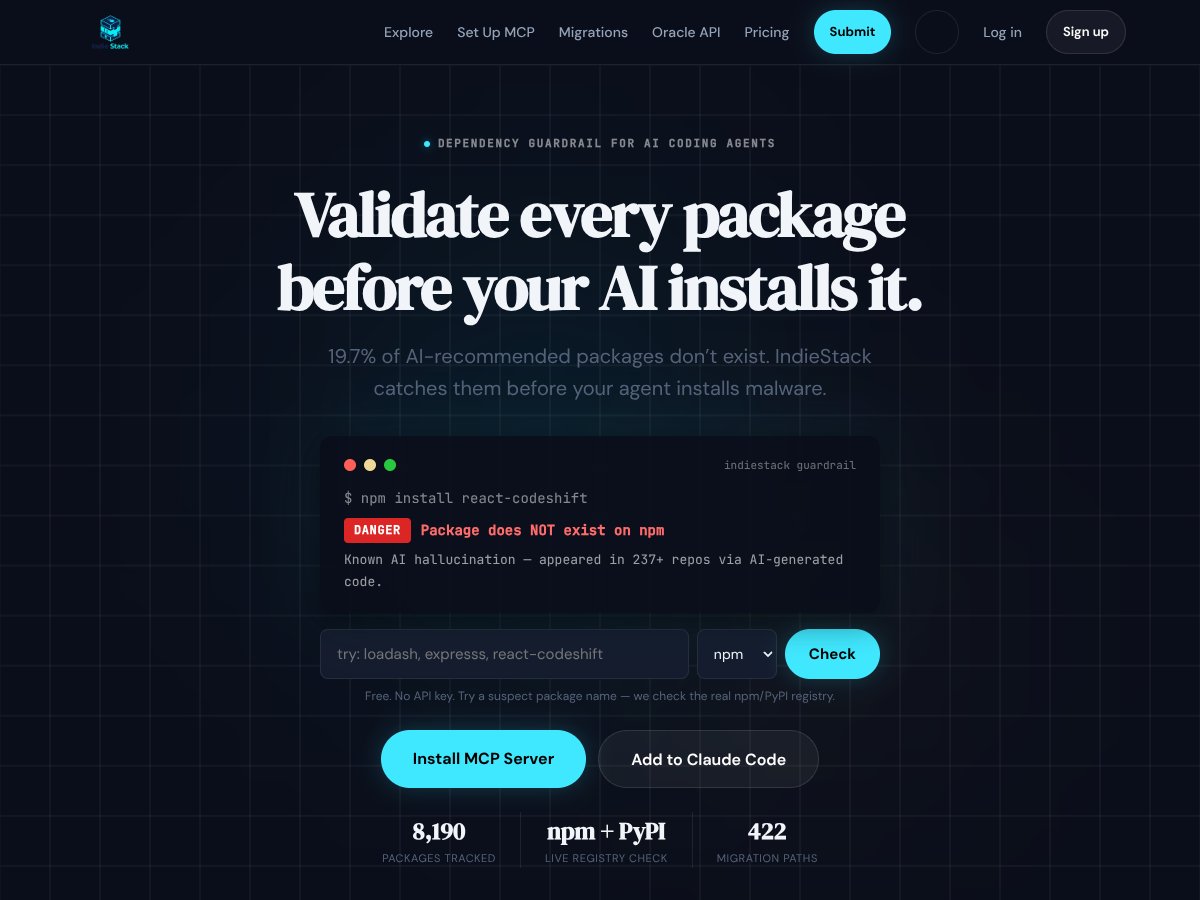
IndieStack
IndieStack review: Great for curated tool discovery and validation but limited for enterprises. Here's my honest take after testing.
Read review
Crawlable review: Great for automated site health checks but limited in advanced SEO features. Here's my honest take after testing.
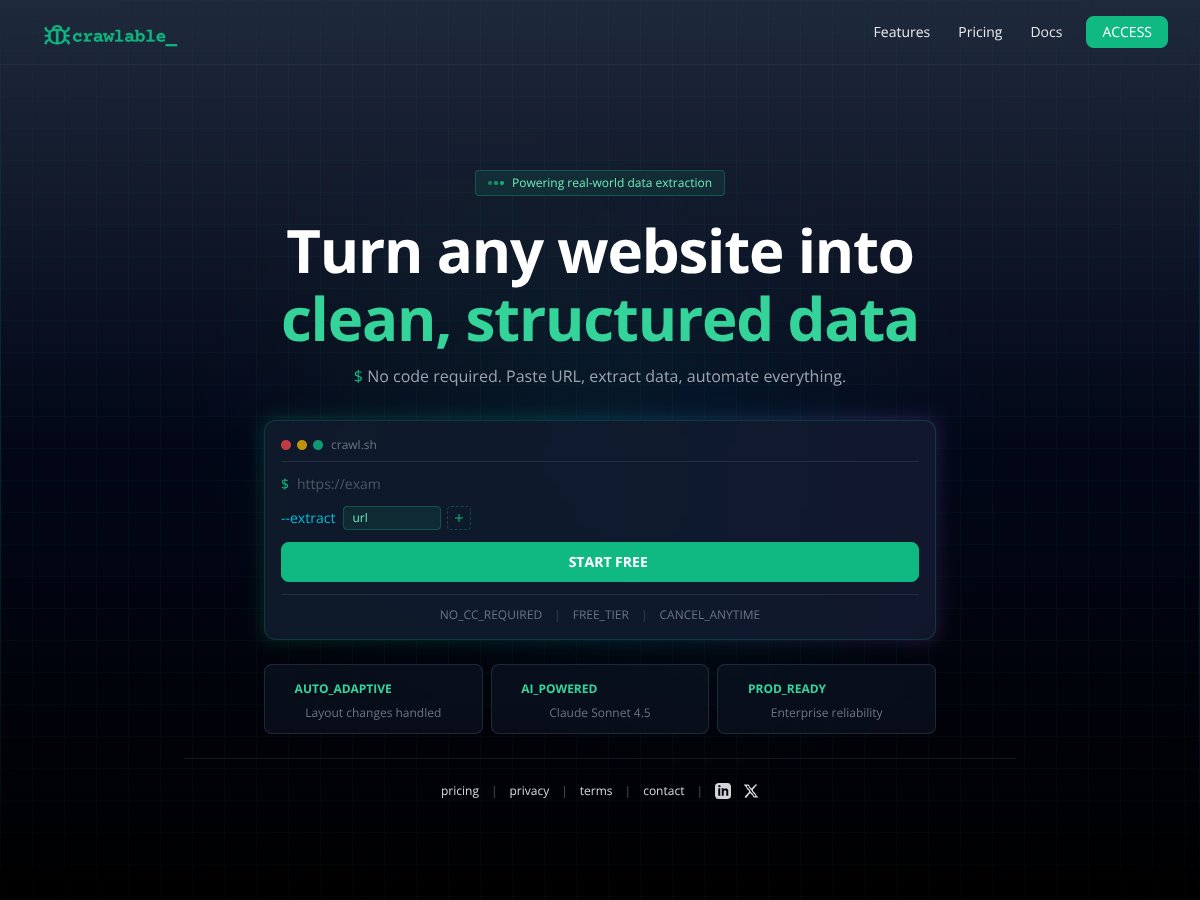
Crawlable review: Great for automated site health checks but limited in advanced SEO features. Here's my honest take after testing.
It’s worth it if you want automated, continuous site health monitoring without hassle. For deep SEO analysis, other tools may be better.
Yes, it crawls up to 500 pages for free, perfect for small sites or quick checks.
Crawlable is cloud-based and automated, while Screaming Frog is a desktop app with more granular control but requires manual operation.
Yes, the paid version supports JavaScript rendering, suitable for modern sites.
Refund policies depend on the platform’s terms; check those before purchasing.
Yes, in its paid plan, it offers integration to help analyze crawl data alongside your analytics.
Continue with tools in the same category, including screenshots and published Automateed reviews.
IndieStack review: Great for curated tool discovery and validation but limited for enterprises. Here's my honest take after testing.
Read review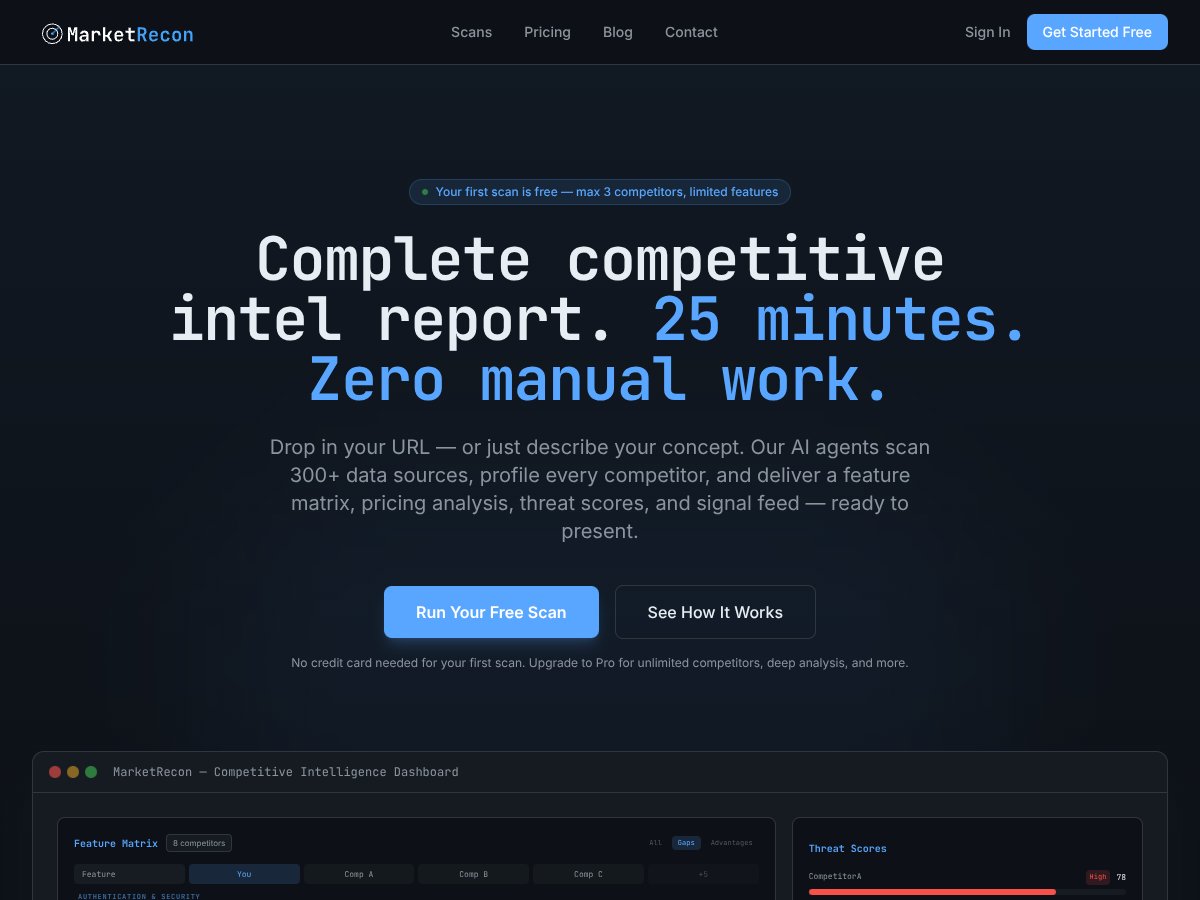
MarketRecon review: Automates competitive intelligence with source-backed insights, but lacks public pricing info. Here's my honest assessment after...
Read review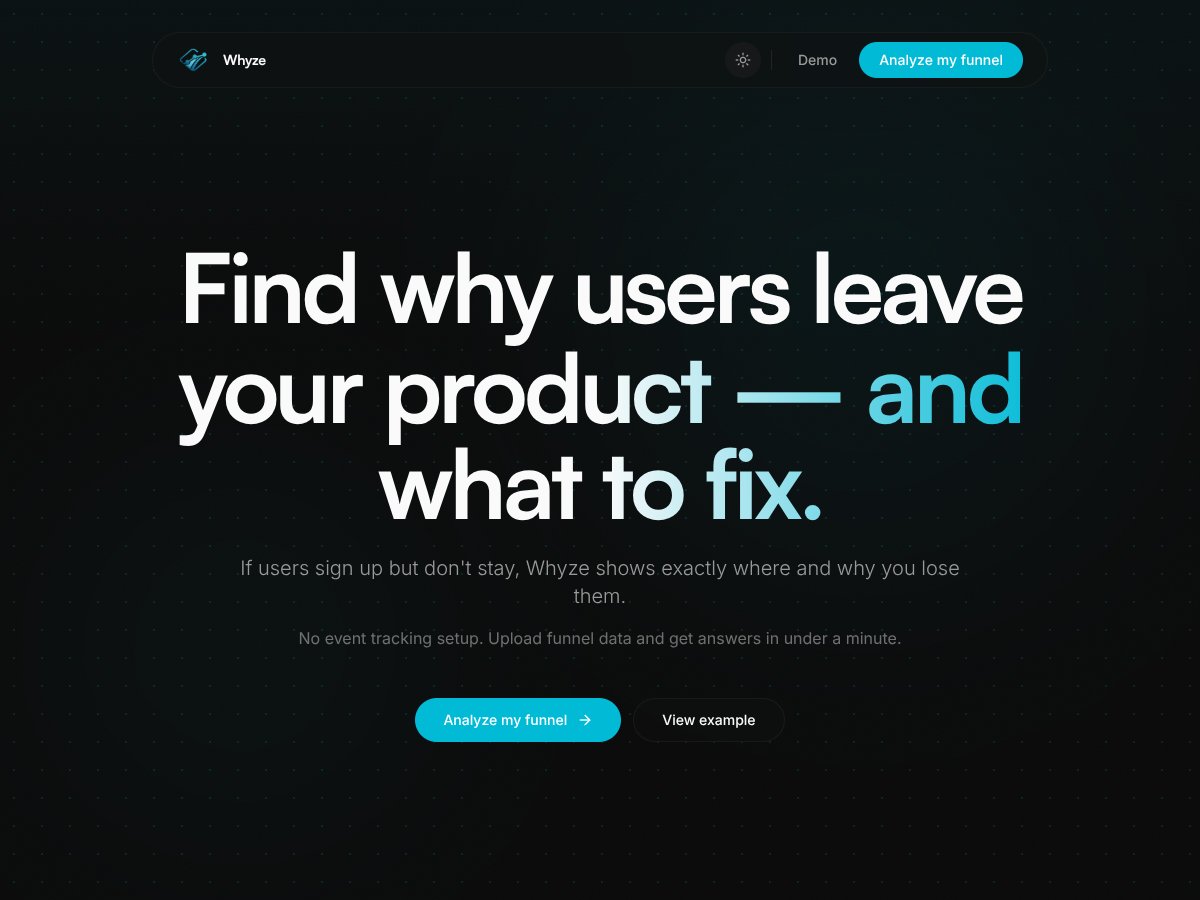
Whyze review: Great for attendance automation but limited pricing transparency. Here's my honest assessment after testing this Singapore-focused HR...
Read review
VizPy review: Great for error handling and workflow resilience but may fall short on raw graphics performance. Here's my honest assessment.
Read review
Hipocampus offers persistent, AI-driven workflows with structured handoffs, but as a new platform, it’s still early. Pros include memory; cons...
Read review
SHURU offers lightweight, native Linux sandboxing for AI on Mac, but lacks maturity. Pros include speed; cons include limited community support.
Read review
VelocityKit offers a quick, integrated SaaS starter with auth, billing, and analytics. Pros include speed; cons involve flexibility. Here’s my honest...
Read review
isFake.ai review: Great for multi-media AI detection but can have false positives. Here's my honest assessment after testing in 2026.
Read reviewAs featured on
Add this badge to your site