Global Issue Memory MCP
Global Issue Memory MCP offers persistent, cross-tool memory but can be complex to set up. Here's an honest review of its pros and cons after testing.
Read review
Hyperterse offers secure, high-performance database access for AI integration, but lacks advanced permissions and caching—here's my honest review after testing.
Hyperterse offers secure, high-performance database access for AI integration, but lacks advanced permissions and caching—here's my honest review after testing.
It depends on your needs. If you value security, speed, and easy AI integration, it’s worth exploring. For complex permissions or caching, you might need to wait.
The product was recently launched, and details about free tiers aren’t clear yet. Expect limited trial access initially.
Hyperterse emphasizes SQL safety and AI-readiness, while Hasura offers GraphQL with real-time features. Choose based on your preferred API style.
Refund policies aren’t publicly detailed yet; check their official support or terms once available.
Yes, it supports Postgres, MySQL, and Redis, making it versatile for different stacks.
Yes, especially if you’re familiar with configuration files—no complex boilerplate required.
Continue with tools in the same category, including screenshots and published Automateed reviews.
Global Issue Memory MCP offers persistent, cross-tool memory but can be complex to set up. Here's an honest review of its pros and cons after testing.
Read review
Clean review: Great for quick, AI-assisted data cleaning but limited for complex workflows. Here's my honest assessment after testing.
Read review
ExploreYC review: Great for YC insights but lacks verified features. Here's my honest assessment after testing this emerging platform.
Read review
DevPass by LLM Gateway review: Great for multi-model access but reliability is unproven. Here's my honest take after testing in 2026.
Read review
Mycelis review: Great for quick AI deployment with smart routing but limited transparency on pricing. Here's my honest assessment after testing.
Read review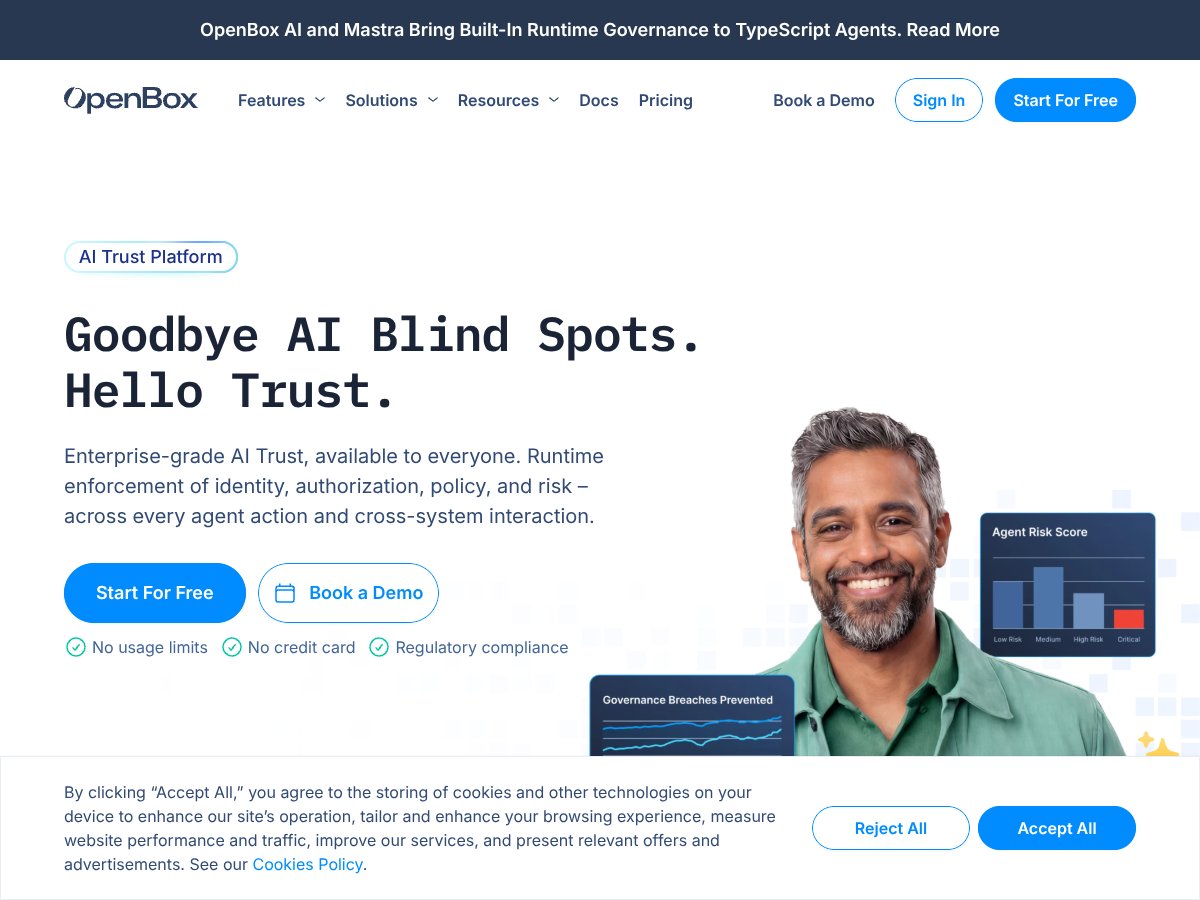
OpenBox offers enterprise-grade AI trust with cryptographic verification but focuses mainly on governance. Here's my honest review after testing.
Read review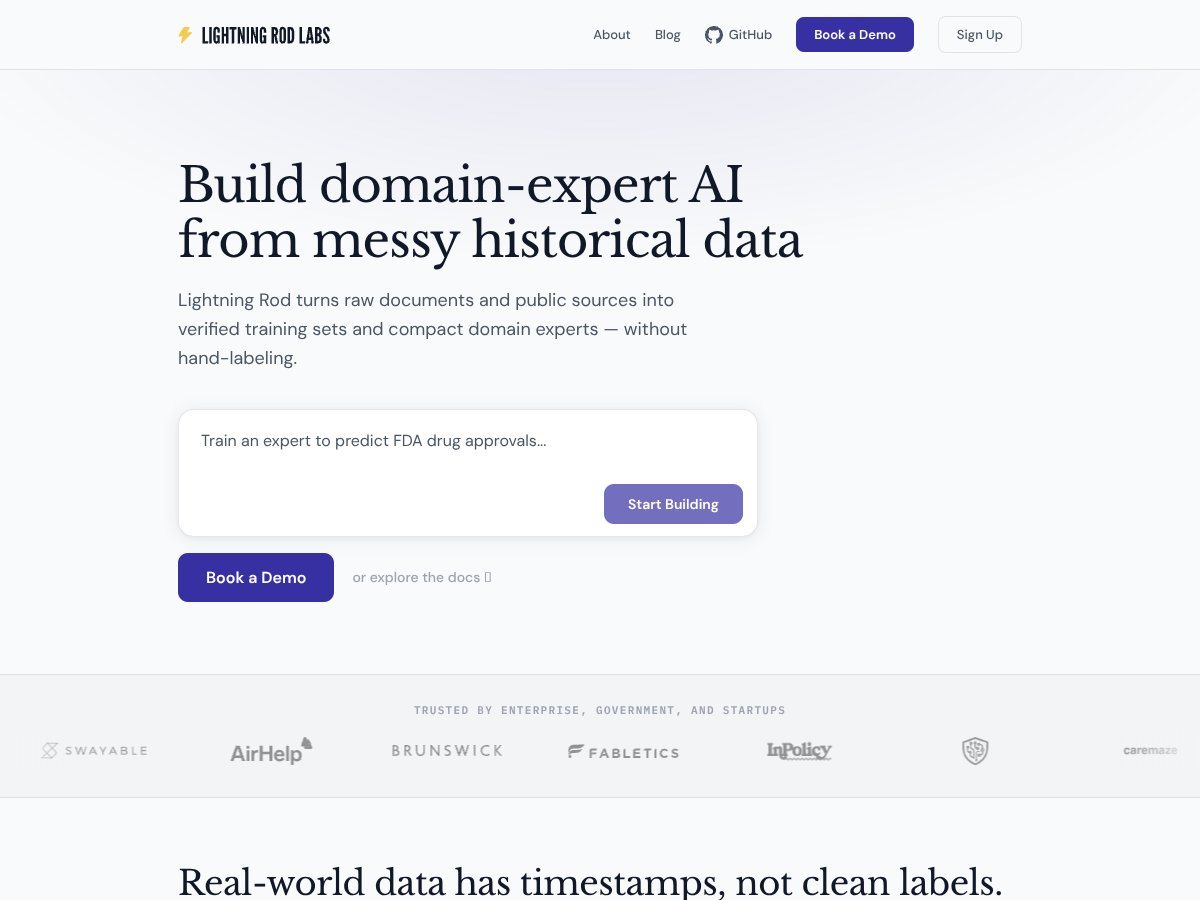
Lightning Rod review: Great for automating data verification but may fall short on manual control. Honest insights after testing.
Read review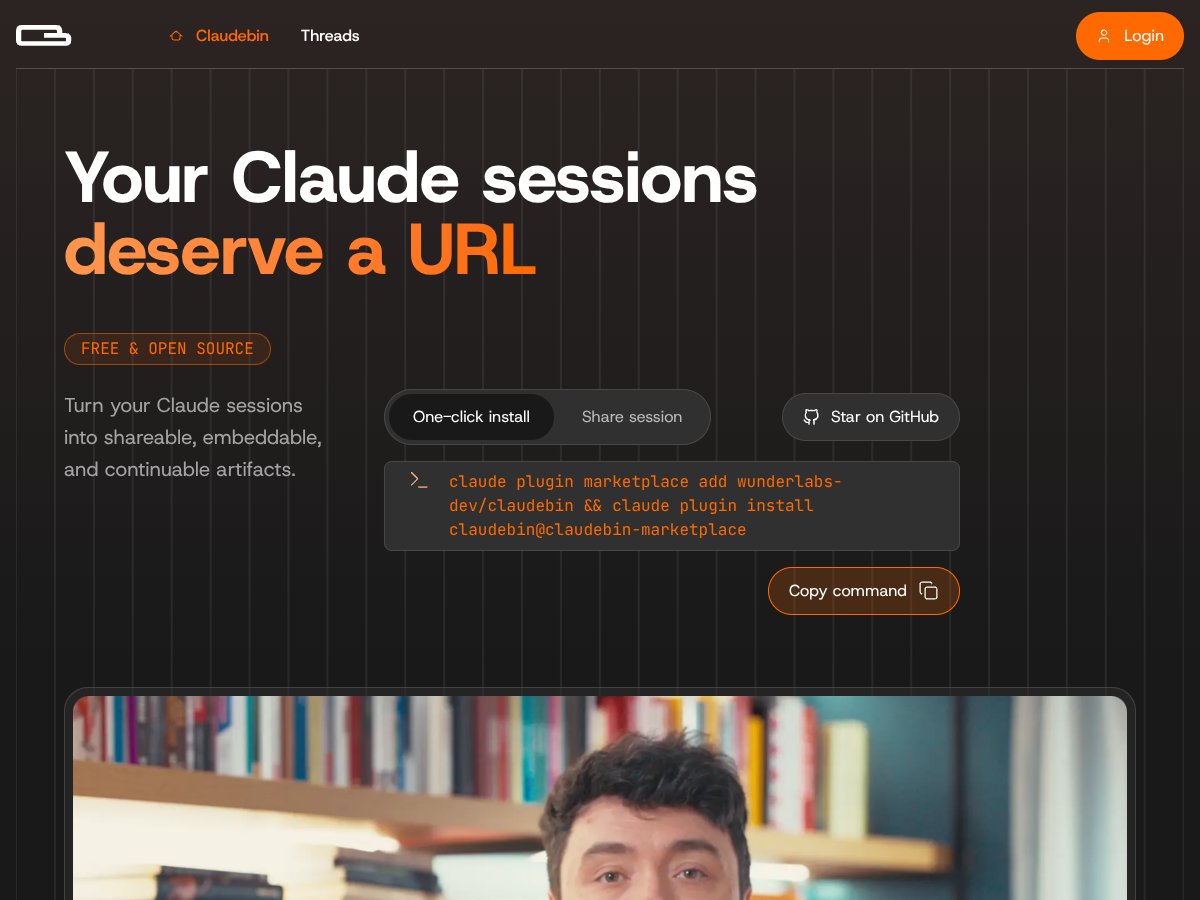
Claudebin review: Great for sharing and resuming Claude Code sessions but limited in editing features. Here's my honest assessment after testing.
Read reviewAs featured on
Add this badge to your site