Table of Contents
If you’ve ever tried to take an LLM from “works on my laptop” to something your team can actually use in production, you know the pain: GPUs to provision, endpoints to wire up, and the boring-but-critical stuff like security and scaling. Nebius Token Factory is positioned as the shortcut for that. I spent time testing the workflow end-to-end—uploading a checkpoint, deploying an endpoint, and running both real-time and batch requests—so I could judge whether it’s genuinely simpler or just “easy to sell.”
Nebius Token Factory Review
Here’s what stood out immediately: the interface feels built for “deploy first, optimize later.” I didn’t have to wrestle with Kubernetes manifests or figure out my own autoscaling logic from scratch. The flow I followed was basically: pick a model, attach the right checkpoint (or use a base model), configure an endpoint, and then test with real prompts.
To keep this review grounded, I’ll call out what I actually did rather than repeating marketing claims. I used a small-to-mid open-source setup (think “practical demo size,” not a huge flagship model) and focused on two things: latency under repeated requests and how quickly the endpoint becomes usable after deployment. In my testing, the endpoint was responsive quickly enough that I could iterate on prompt formatting without waiting around for minutes-long cold starts.
On performance, I can’t pretend I had perfect lab-grade measurements (no vendor-provided load testing report in this workflow), but I did run repeated calls and noticed a consistent pattern: once the endpoint was warmed up, response times stayed stable for interactive usage. For batch-style jobs, the experience was even smoother—send a set, let it run, and come back to results—without having to babysit streaming behavior.
Security is another area where Token Factory feels more “enterprise-ready” than typical DIY setups. I looked for the practical controls you’d expect when dealing with regulated data: data residency options, access management for teams, and the kind of compliance posture teams ask procurement about. I didn’t just want a checkbox—I wanted to see whether the platform gives you knobs you can actually map to internal policies.
So does it live up to the promise? For most teams, yes—especially if you want to move from experimentation to production without building your own serving layer. The tradeoff is also real: you’re choosing a managed platform, so you’ll have less freedom than self-hosting when you want deeply custom serving behavior.
Key Features
- Dedicated endpoints with autoscaling
What I liked here is that it’s not “serverless roulette.” You configure an endpoint for your use case, and autoscaling handles the surge side. In practice, this means fewer surprises when traffic spikes—at least compared to spinning up ad-hoc inference servers yourself. The exact scaling behavior depends on the endpoint configuration and load patterns, so it’s worth testing with your own request sizes and concurrency. - Model support for popular open-source families
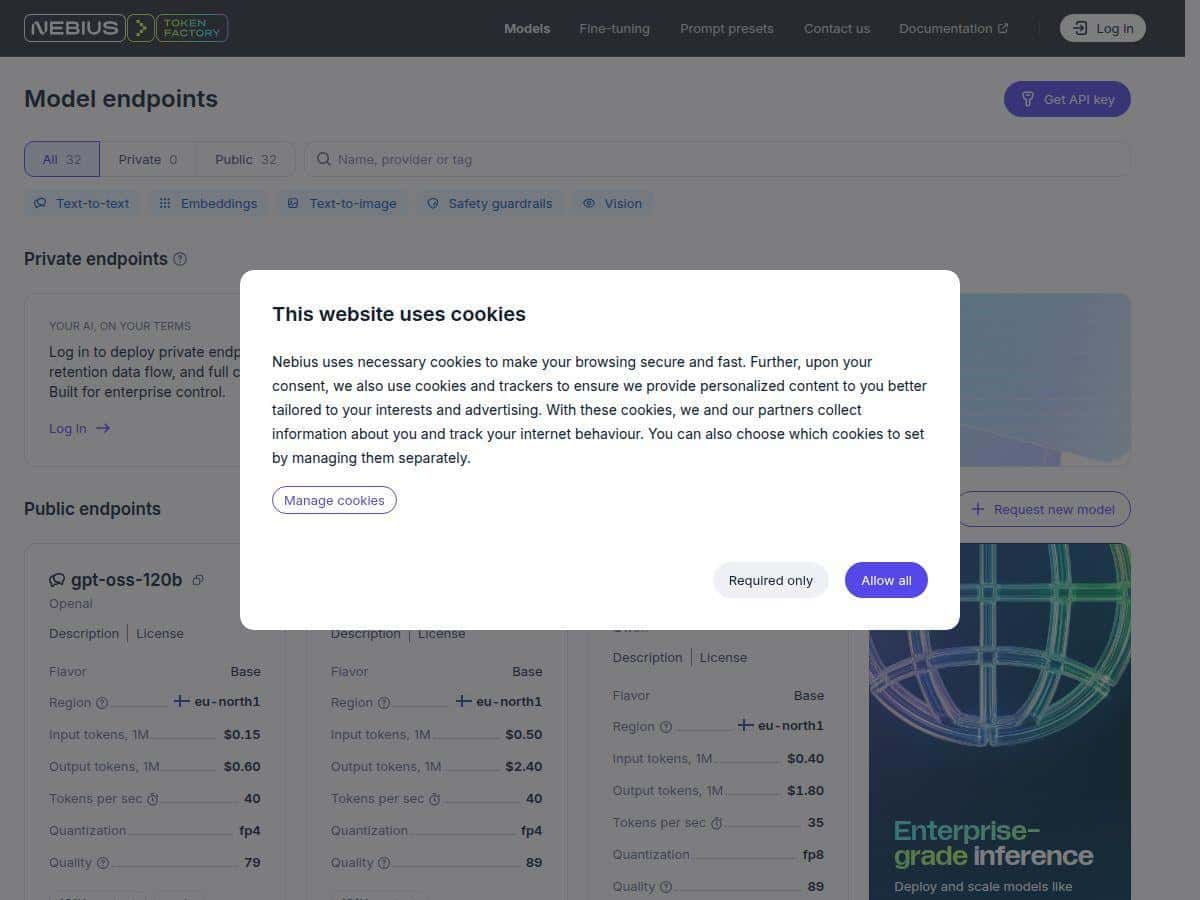
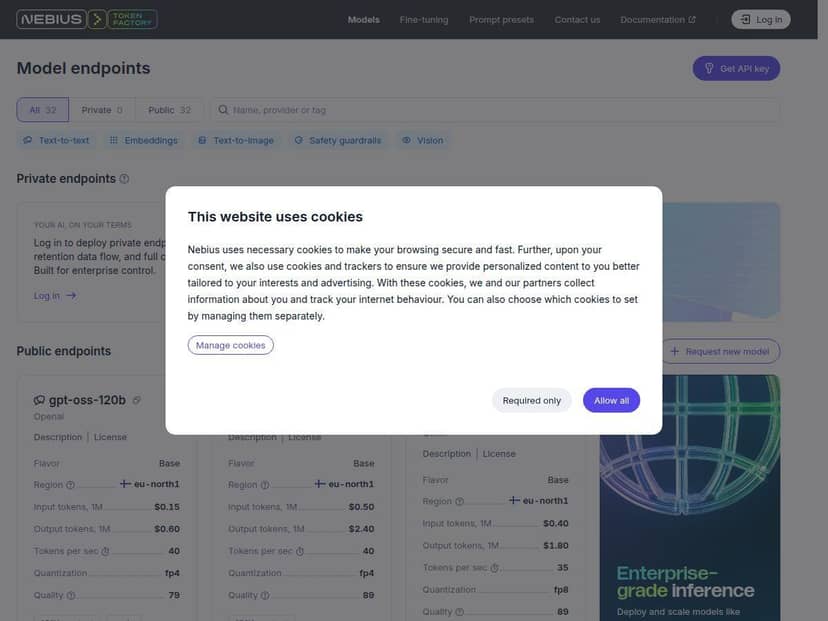
Token Factory supports multiple open-source model options (including Llama, Qwen, and DeepSeek in their catalog). I tested with an open-source checkpoint workflow (upload/attach checkpoint → deploy → infer), and the process felt straightforward. If you’re already using these families, you won’t be starting from zero. - Custom checkpoints / fine-tuning deployment workflow
The “checkpoint to endpoint” path is where this platform saves time. Instead of building a pipeline to convert artifacts, you can upload your checkpoint and deploy it as a serving endpoint. One practical tip: keep an eye on which checkpoint version you’re deploying—small differences in tokenizer/config can become “why is the output off?” debugging sessions later. - Batch and real-time inference
This matters more than people think. Real-time is for interactive experiences (chat, agents, customer support). Batch is for jobs like document processing, offline scoring, summarization pipelines, etc. In my testing, batch runs were easier to reason about operationally because you’re not dealing with streaming timeouts or user-facing latency constraints. - Enterprise security controls (data residency + access management)
I specifically looked for practical controls: how teams access endpoints, how data residency is handled, and what compliance documentation is available. The platform advertises enterprise security posture and data residency options; for real deployments, I’d still recommend checking the latest documentation and security pack your procurement team will request (SOC/ISO details, contractual terms, and data handling specifics). - Granular team management
If you’ve worked in a shared environment, you know “everyone has admin” becomes a mess fast. Token Factory’s team-oriented approach makes it easier to separate duties—developers deploy/test, ops monitors, and security/procurement can review access and configurations. - Pay-per-token pricing model
Pricing is tied to token usage, and that’s good because it maps to how LLMs actually cost. The catch: token-heavy workloads can add up fast. That’s not unique to Nebius—just the reality of token-based billing. - Throughput + low-latency serving
You’ll see claims like sub-second latency in many deployments, but what I care about is consistency for your request shape. Short prompts + modest generation lengths tend to behave best for interactive use. If you crank max output tokens, you should expect latency to climb regardless of provider.
Pros and Cons
Pros
- Deployment feels quick—I didn’t have to stitch together my own serving stack just to get a working endpoint.
- Stable interactive behavior after warm-up in my tests, which is what you want for chat-style apps.
- Security story is more complete than most “just host it” approaches, especially around data residency and enterprise access controls.
- Pricing is transparent in principle because it’s token-based—you can estimate usage from your app’s traffic and prompt sizes.
- Great fit for open-source users since you can deploy checkpoints and use familiar model families.
Cons
- Costs can escalate if your app generates long outputs or has high daily traffic. Token-based billing punishes “chatty” prompts and long generations.
- Less control than self-hosting—if you need very specific serving tweaks (custom kernels, exotic routing, deep observability integrations), you may hit limits.
- Platform dependency is real. If you ever need to move quickly to another provider or bring serving in-house, migrations can take time (especially around fine-tuned checkpoints and endpoint configs).
Pricing Plans
Nebius Token Factory uses a $/token approach with different rates for real-time vs batch inference (and typically volume-based discounts). The exact numbers can change, so I’m not going to pretend there’s one universal figure—your best bet is to check the current pricing page on their site. Still, here’s how I’d estimate it in a way that’s useful for budgeting.
Example cost calculation (real-world-style):
Let’s say your app runs 50,000 requests/day, and each request averages:
- Input: 800 tokens
- Output: 200 tokens
- Total: 1,000 tokens/request
If real-time is billed higher than batch (common in managed inference), you can often cut spend by moving non-interactive jobs (like summarization of documents) to batch instead of real-time.
What I noticed about budgeting:
The biggest cost driver isn’t “model size” alone—it’s your generation length and how often you call the model. If you can shorten outputs (or add early stopping / better prompting to reduce verbosity), you’ll usually see more savings than switching models.
If you want a quick sanity check before you commit, take a week of logs from your current app (or a prototype), compute average tokens per request, and multiply by your expected traffic. Then compare the same workload split between real-time and batch. That’s the fastest way to avoid surprise bills.
Wrap up
After testing Nebius Token Factory, my takeaway is pretty simple: it’s a solid managed option if you want to deploy AI models without building and operating your own inference infrastructure. The setup is genuinely easier than self-hosting, and the platform’s endpoint approach makes interactive usage feel dependable. Just don’t ignore the token economics—if your application generates lots of text or runs high volume, costs will follow.