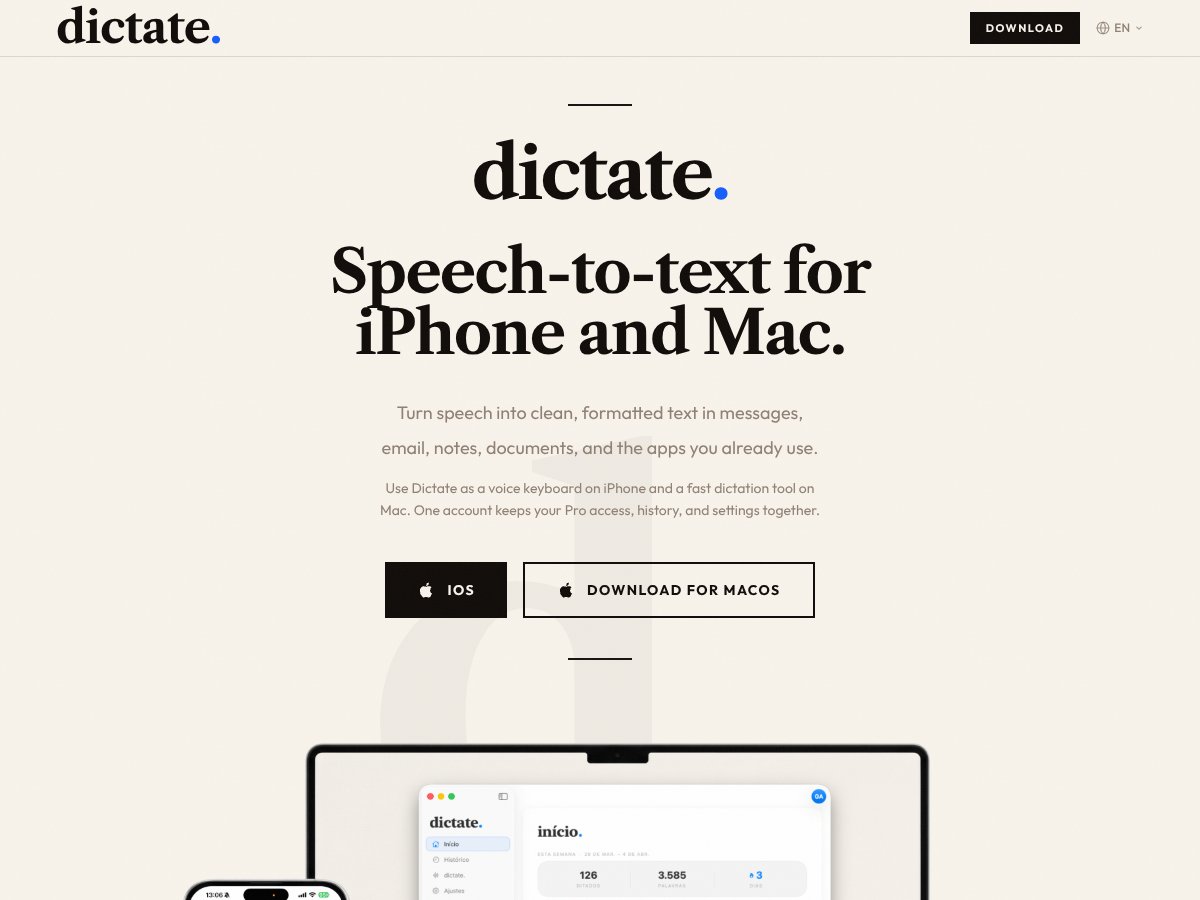
dictate.
dictate. review: Great for quick voice-to-text on Apple devices but uncertain accuracy may limit professional use. Here's my honest take after...
Read review
NeuroBlock review: Great for private AI model development but lacks transparent pricing. Here's my honest take after testing this enterprise AI platform.
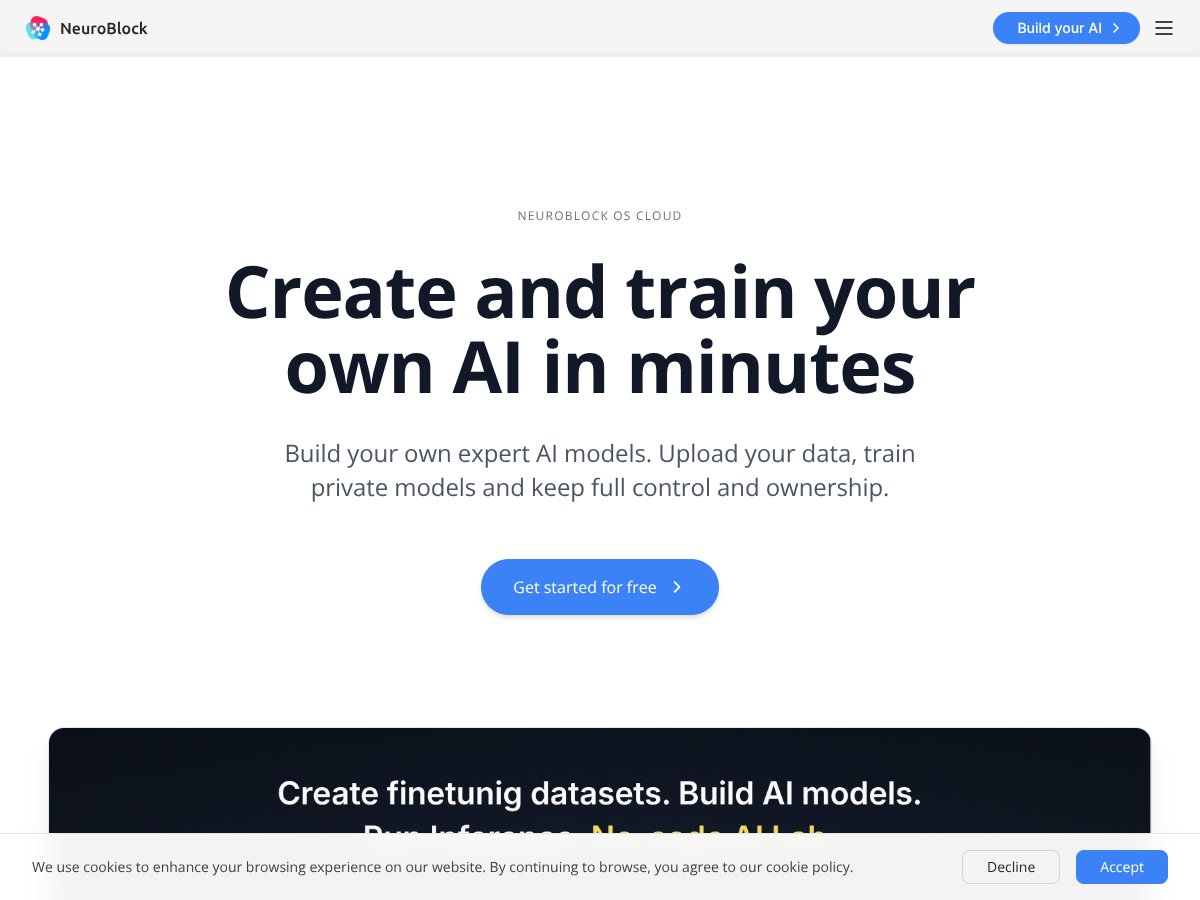
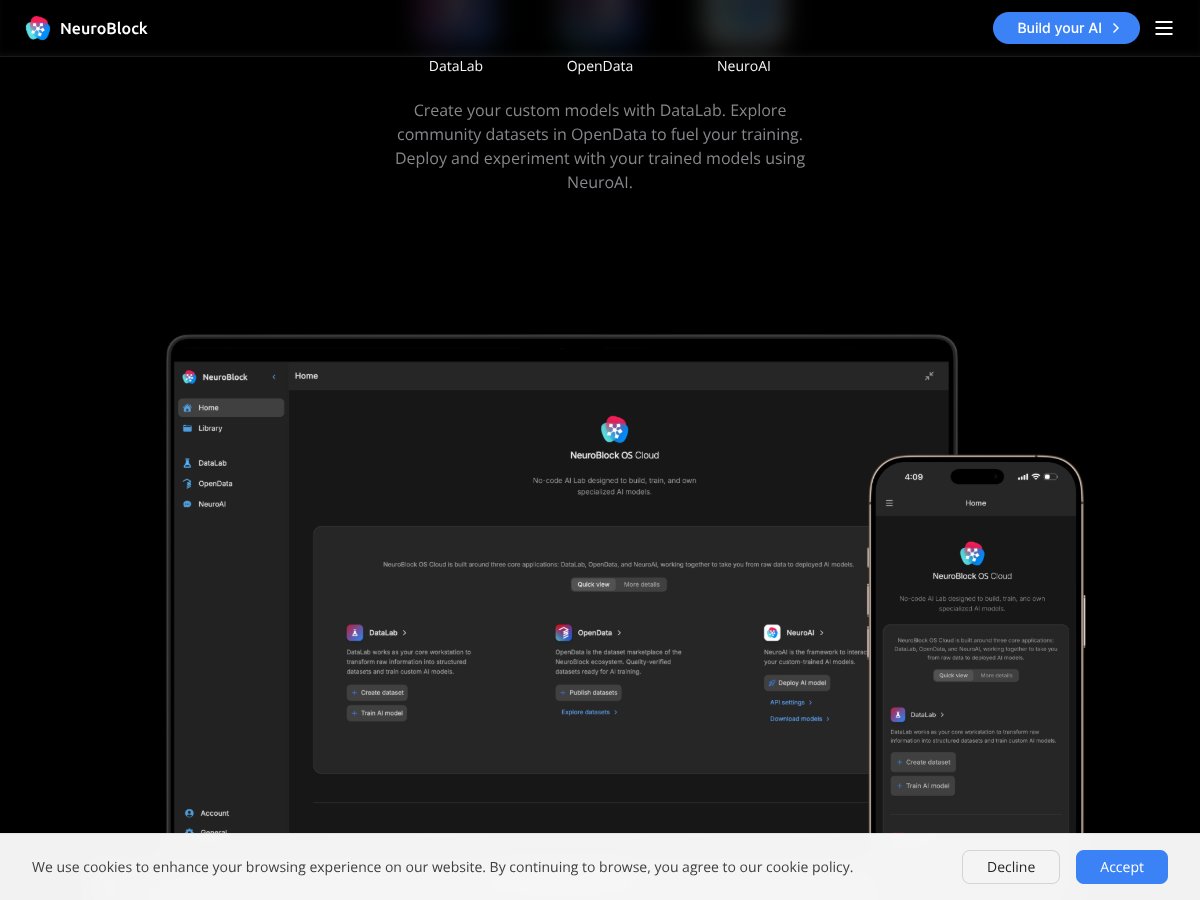
NeuroBlock review: Great for private AI model development but lacks transparent pricing. Here's my honest take after testing this enterprise AI platform.
It’s worth it if you need private, customizable AI models with strong data control. For simpler needs, other platforms may be more cost-effective.
Yes, they offer a free trial and a limited free tier, but advanced features require a paid subscription.
NeuroBlock excels in data privacy and customization but may lack the quick setup of more straightforward tools focused on marketing or edge deployment.
Supports dataset management, model training, inference, private deployment, and API integration, though specific performance benchmarks aren’t publicly available.
Refund policies depend on your plan and vendor terms; contact support directly for details.
It’s primarily enterprise-oriented, so small teams with limited resources might find it complex or costly unless privacy is a top concern.
Continue with tools in the same category, including screenshots and published Automateed reviews.
dictate. review: Great for quick voice-to-text on Apple devices but uncertain accuracy may limit professional use. Here's my honest take after...
Read review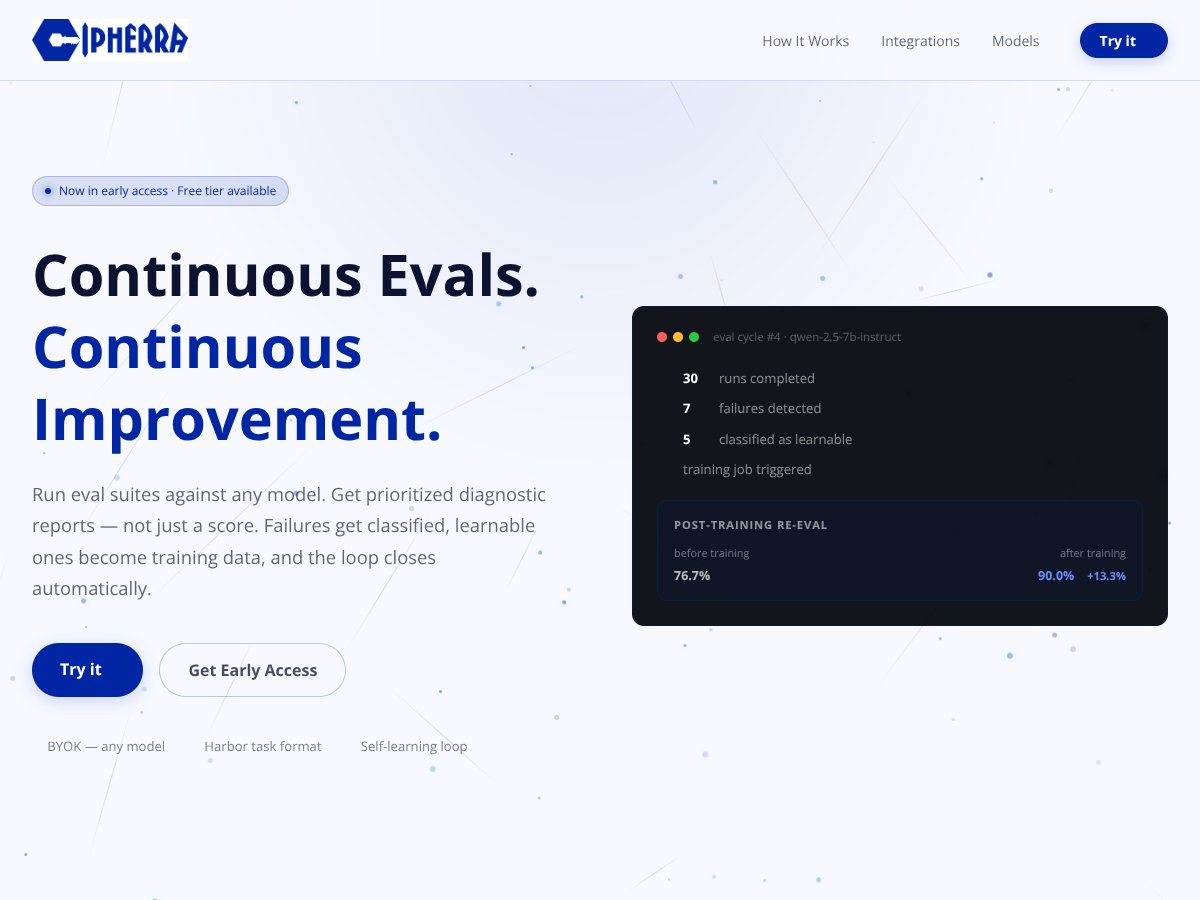
Cipherra review: Promising for large-scale model diagnostics but limited info makes it hard to fully endorse. Here’s my honest take after testing.
Read review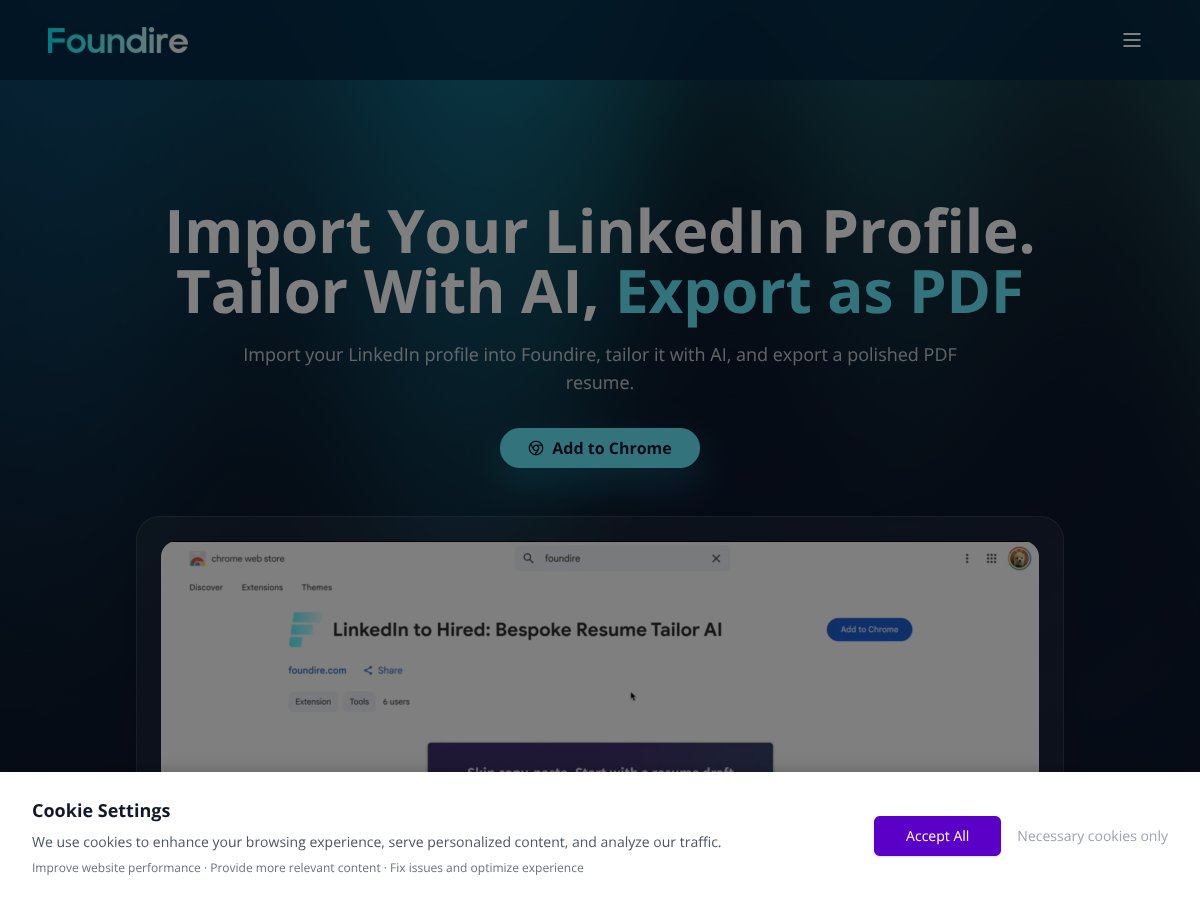
Resume Builder by Foundire review: Great for quick AI resume tweaks but lacks detailed customization. Here's my honest assessment after testing.
Read review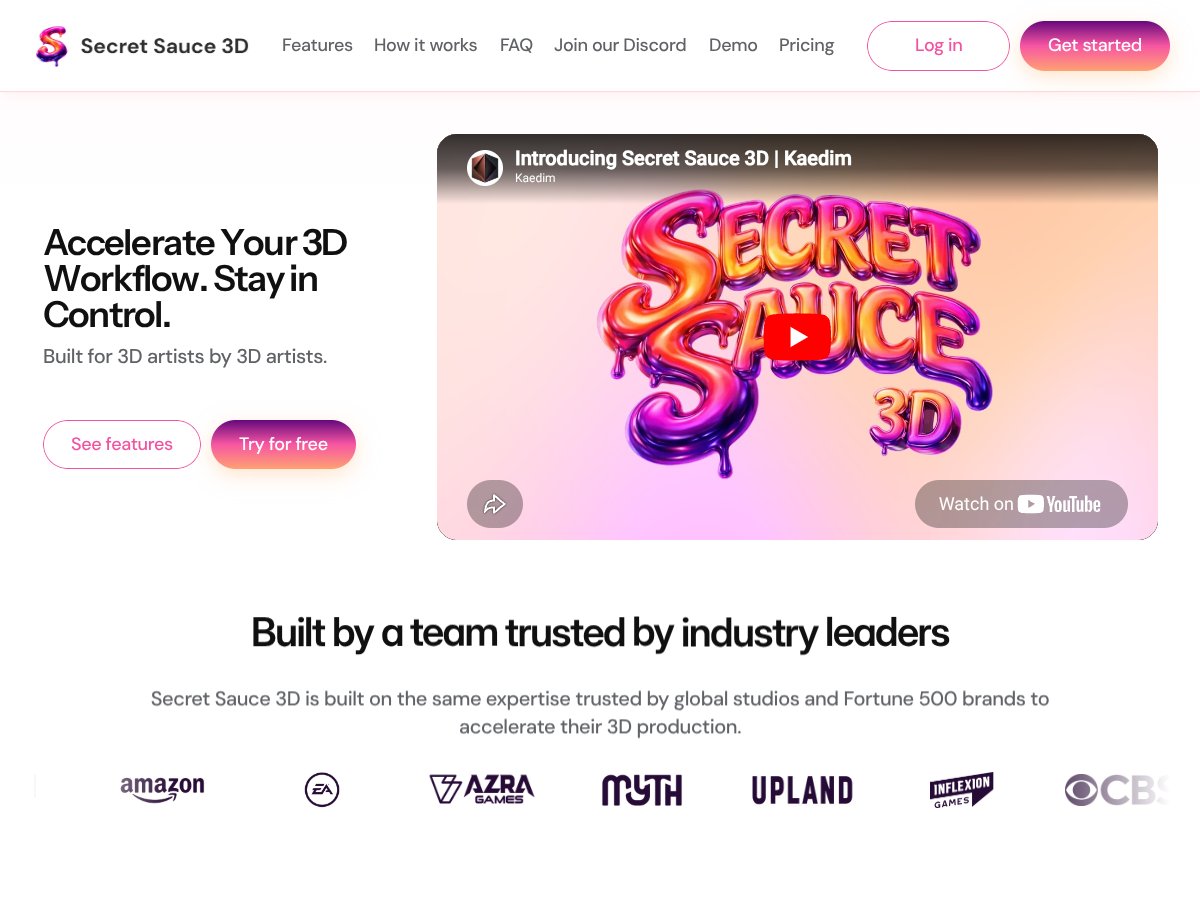
Secret Sauce 3D review: Great for accelerating pipelines and editable outputs, but lacks transparent pricing. Here's my honest assessment after...
Read review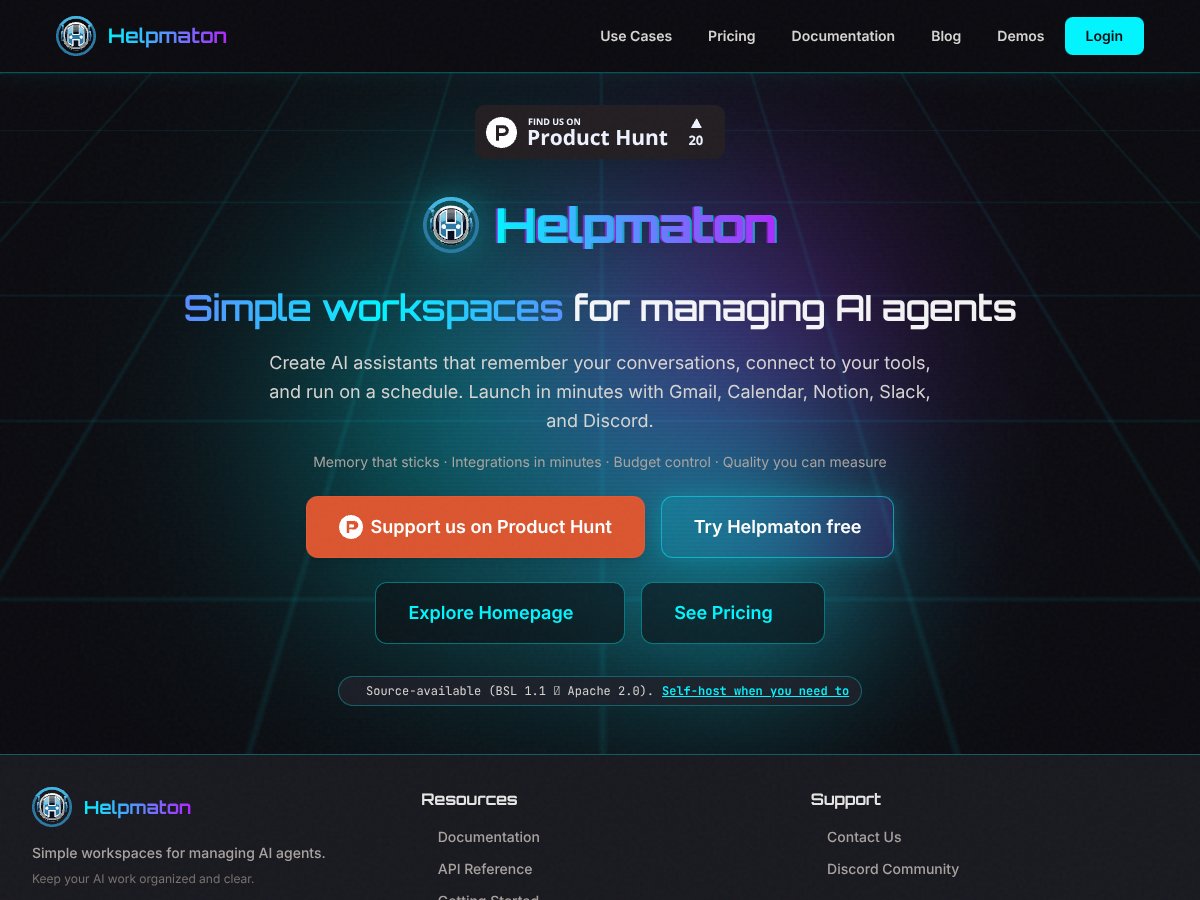
Helpmaton review: Great for managing AI agents in simple workspaces but lacks detailed info. Here's my honest take after testing, including pros and...
Read review
Noteweave offers powerful research-to-action automation with traceable validation, but its pricing and maturity might be barriers for some. Honest...
Read review
Science Beach offers open, collaborative hypothesis testing with AI but requires technical skills. Pros include democratization; cons involve...
Read review
ElevenCreative by ElevenLabs review: Great for all-in-one multimedia creation with strong localization, but some content quality variability. Honest...
Read reviewAs featured on
Add this badge to your site