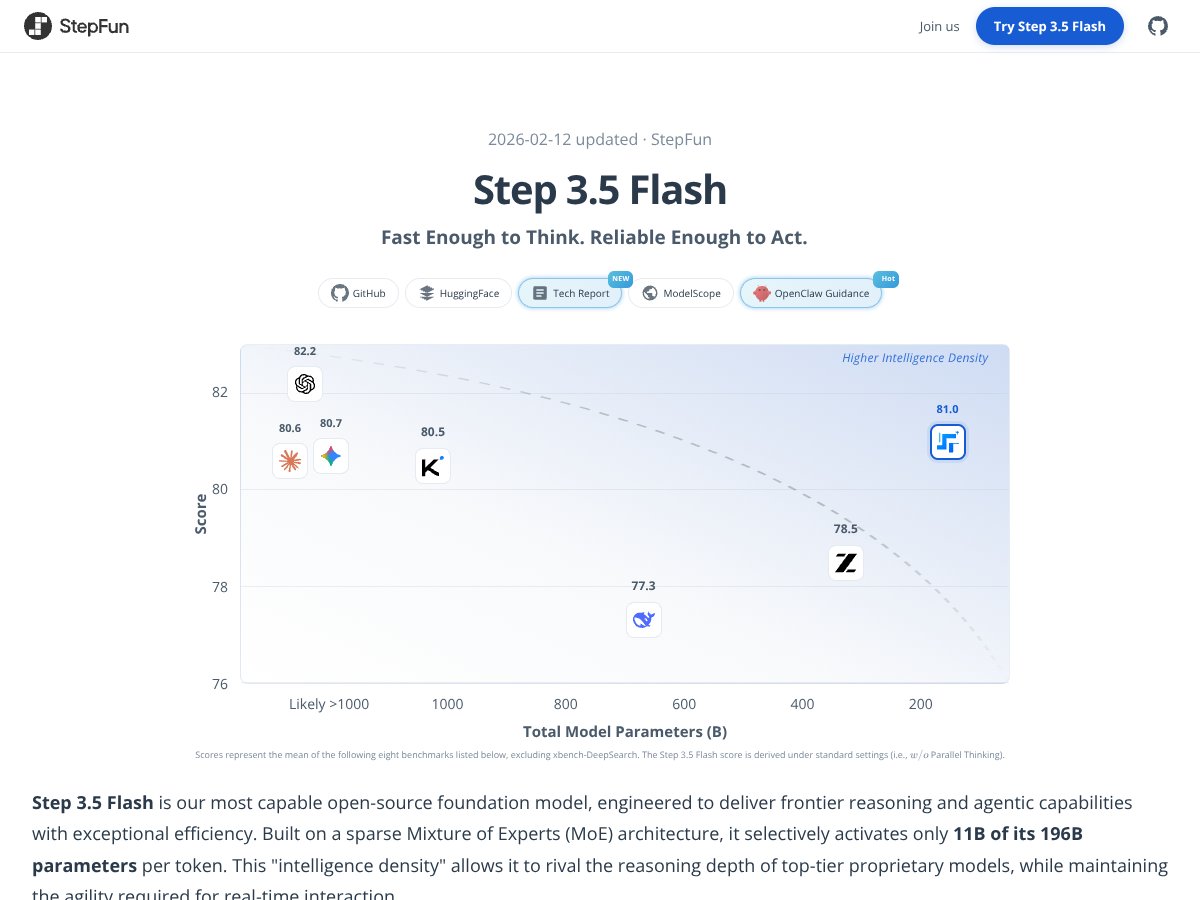
Step 3.5 Flash
Step 3.5 Flash offers top-tier reasoning and local deployment, but requires high-end hardware. Here's my honest review after testing.
Read review
Next.js Evals is a free, open-source tool for benchmarking AI agents on Next.js tasks. It’s precise but limited in scope—here’s my honest review.
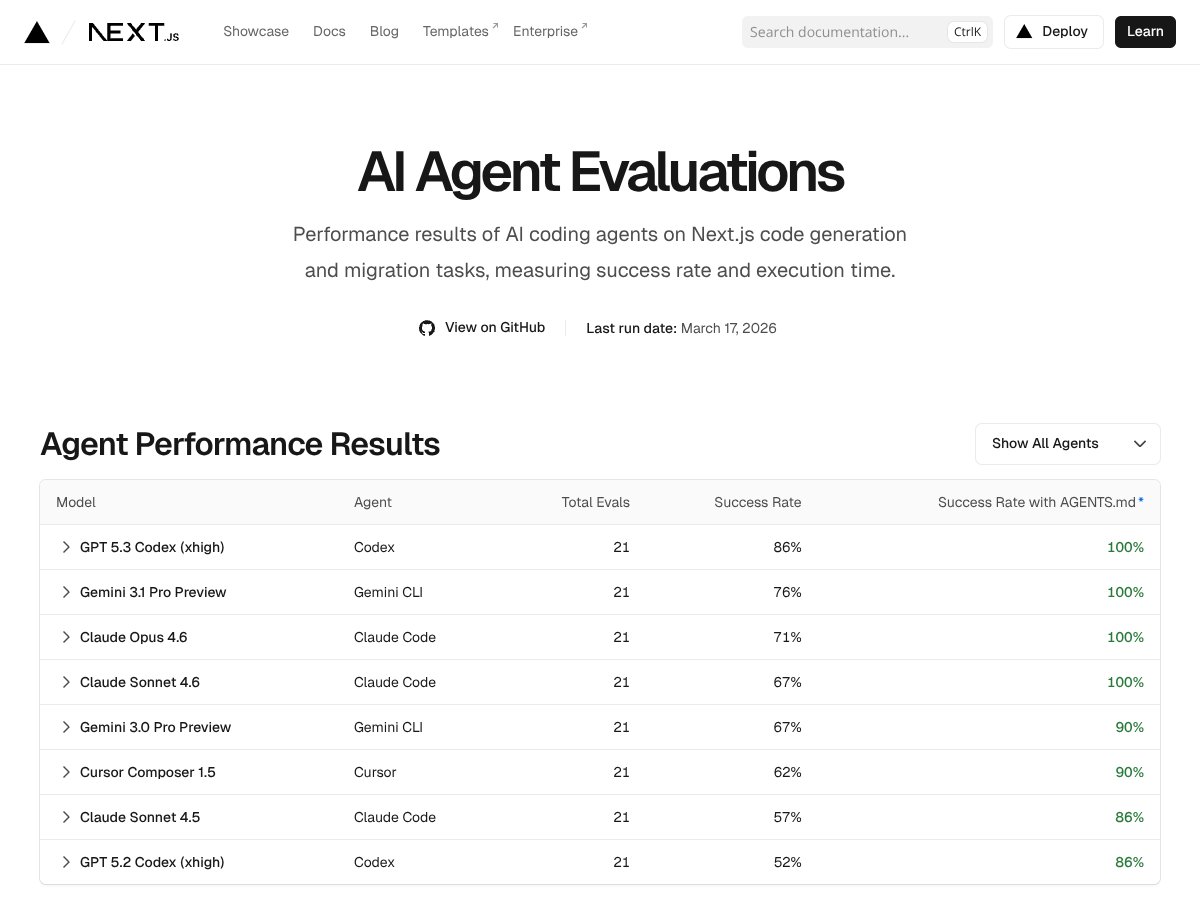
Next.js Evals is a free, open-source tool for benchmarking AI agents on Next.js tasks. It’s precise but limited in scope—here’s my honest review.
It’s free and valuable for Next.js developers wanting to benchmark AI performance, but its scope is limited to Next.js tasks.
Yes, it’s open-source and available on GitHub, with no costs involved.
Next.js Evals is more specialized for Next.js workflows, while Hugging Face covers broader models and tasks.
Yes, since it’s open-source, you can contribute or modify benchmarks to suit your needs.
It supports models like GPT, Gemini CLI, Claude Code, and Cursor, with recent benchmarks highlighting GPT 5.3 Codex.
The latest update was on February 18, 2026, but frequency depends on community contributions.
Continue with tools in the same category, including screenshots and published Automateed reviews.
Step 3.5 Flash offers top-tier reasoning and local deployment, but requires high-end hardware. Here's my honest review after testing.
Read review
Scowld review: Immersive avatar AI with hands-free voice and vision, but still in beta. Great for experimentation, less for polished daily use.
Read review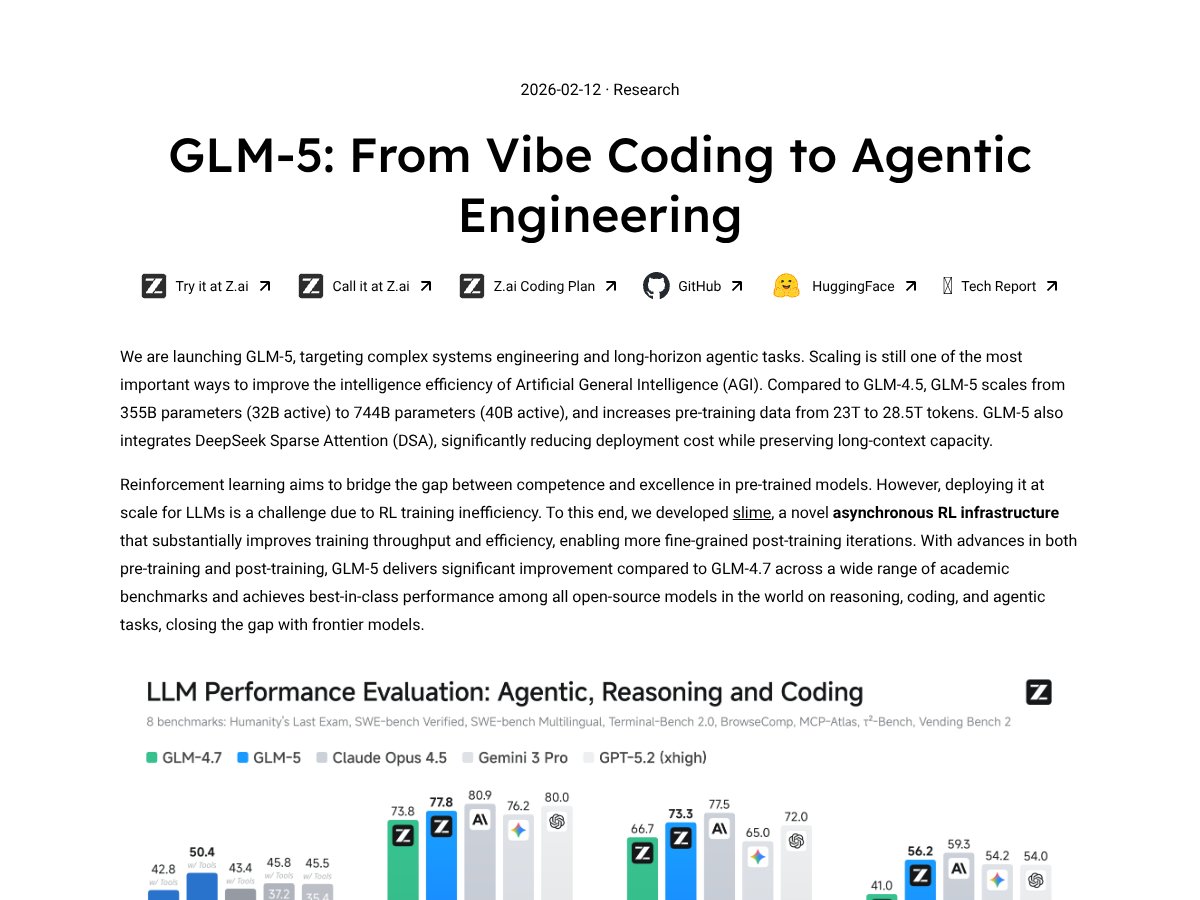
GLM-5 review: Great for long-document analysis and reasoning at a fraction of the cost, but it’s less proven in real-world deployment than some...
Read review
Rosentic review: Great for preventing cross-branch conflicts in open source projects but limited in customization. Here's my honest assessment after...
Read review
Platos | The runtime for Managed Agents review: Great for customization and control but requires DevOps skills. Here's an honest assessment after...
Read review
Granary by Speakeasy review: Great for managing AI workflows efficiently but can be pricey. Here's my honest take after testing in 2026.
Read review
maxc review: Great for automation and terminal workflows but requires setup. Here's my honest take after testing this open-source dev workspace.
Read review
FastMCP 3.0 is a robust framework for building MCP apps with features like security and UI; it’s complex but powerful. Pros and cons here.
Read reviewAs featured on
Add this badge to your site