
Voxtral Transcribe 2 by Mistral Review
Voxtral Transcribe 2 by Mistral offers fast, accurate transcription with privacy focus; however, limited language support. Here's my honest review after testing.
Screenshots
Swipe
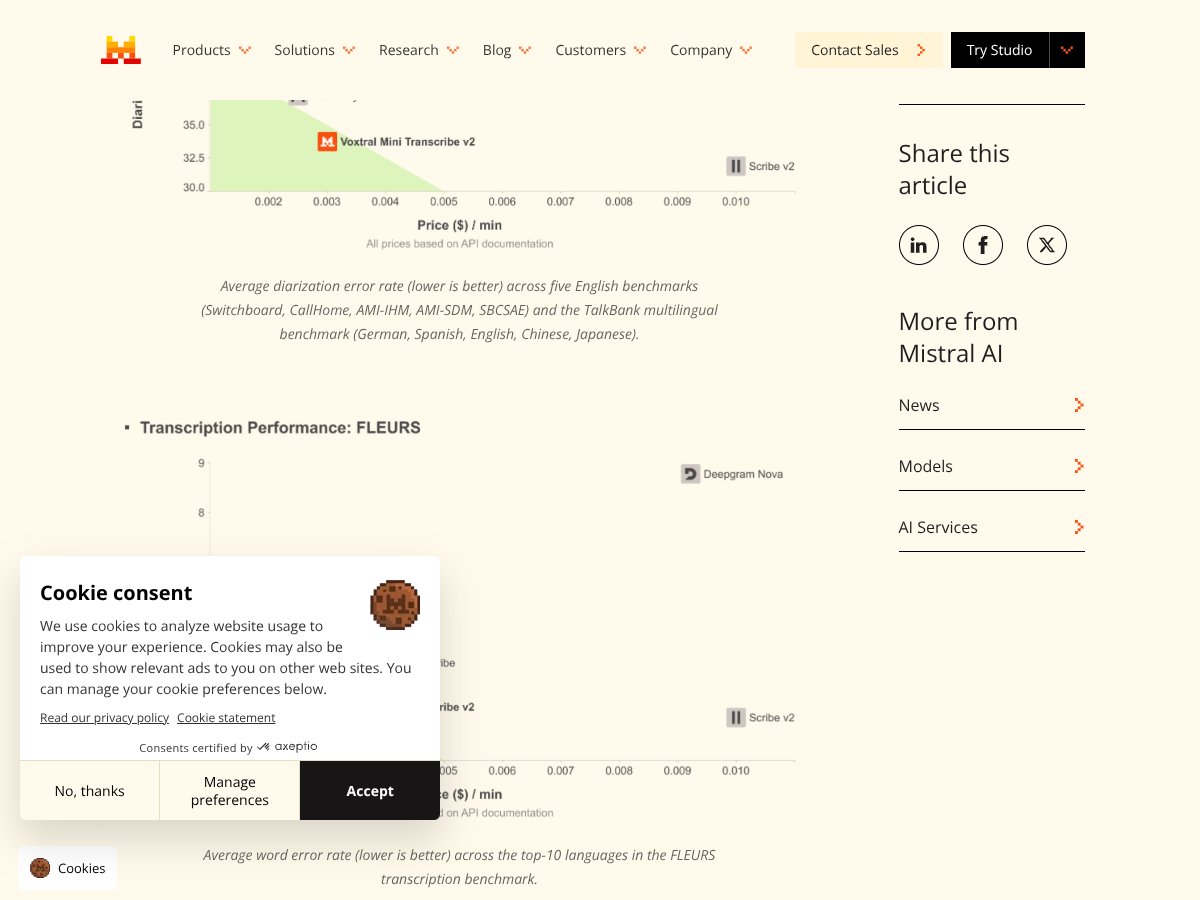
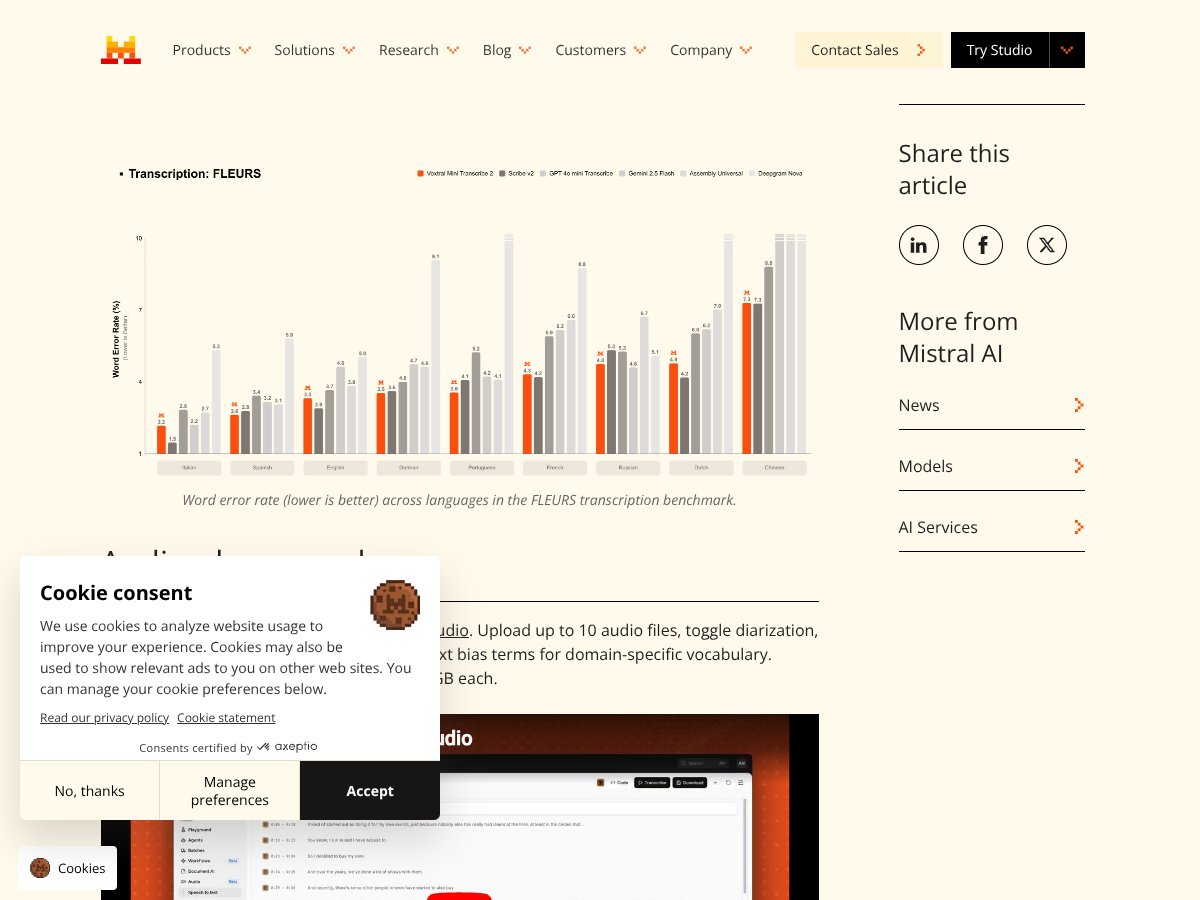
About Voxtral Transcribe 2 by Mistral
Voxtral Transcribe 2 by Mistral offers fast, accurate transcription with privacy focus; however, limited language support. Here's my honest review after testing.
Key Features & Use Cases
Best for
Pros
- ✓Feature-rich platform
- ✓Easy to use
- ✓Good documentation
Cons
- ×Pricing could be clearer
- ×Learning curve for advanced features
Frequently Asked Questions
Is Voxtral Transcribe 2 by Mistral worth the money?
Yes, especially if you need real-time, accurate transcription with privacy options. Costs can add up for large-scale use, so consider your budget.
Is there a free version?
Yes, the Voxtral Realtime open-weights model is free to download from Hugging Face, but requires setup and some technical skill.
How does it compare to Whisper?
Whisper is free and flexible but slower and less suited for live, low-latency applications. Voxtral excels in real-time scenarios.
Can I run it locally?
Yes, Voxtral Transcribe 2 supports local deployment, making it suitable for privacy-sensitive environments.
How many languages does it support?
Currently, 13 languages, including English, Spanish, and Chinese. Less extensive than some competitors but sufficient for many use cases.
Is setup complicated?
It’s designed for developers, so some technical knowledge is needed, especially for self-hosted or private deployment.
As featured on
Add this badge to your site